多分类问题multicalss classification
多分类问题:有N个类别C1,C2,...,Cn,多分类学习的基本思路是“拆解法”,即将多分类任务拆分为若干个而分类任务求解,最经典的拆分策略是:“一对一”,“一对多”,“多对多”
(1)一对一
给定数据集D={(x1,y1),(x2,y2),...,(xn,yn)},yi€{c1,c2,...,cN},一对一将这N个类别两两配对,从而产生N(N-1)/2个二分类任务,在测试阶段新样本将同时提交给所有的分类器,于是将得到N(n-1)/2个分类结果,最终把预测最多的结果作为投票结果。
算法:

(2)一对多
一对多则是将每一个样例作为正例,其他剩余的样例作为反例来训练N个分类器,如果在测试时仅有一个分类器产生了正例,则最终的结果为该分类器,如果产生了多个正例,则判断分类器的置信度,选择置信度大的分类别标记作为最终分类结果。
算法:

举例描述:
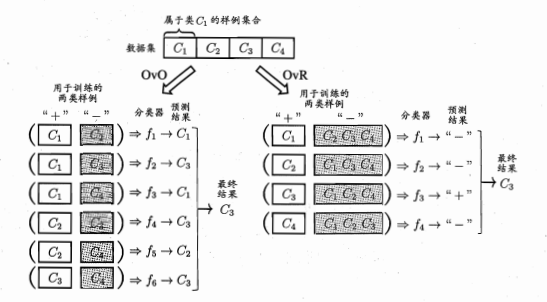
一对一问题:如果有4个类,首先从中任选两个类,进行标记,判断某一个样例更倾向于哪一个类,记录预测的结果,对所有的样例进行判断,看他应该属于两个类中的哪一个,然后选择其他的两个类,重复这个过程,最后收集某一个样例的全部判断结果,会得到不同的结果,找到其中的所占的比例最大的结果即为最终的结果。
(3)多对多问题:
有一种最常用的技术是:”纠错输出码“,分为两个阶段,编码阶段和解码阶段
编码阶段:对N个类别进行M次划分,每次将一部分类划分为正类,一部分类划分为反类,编码矩阵有两种形式:二元码和三元码,前者只有正类和反类,后者除了正类和和反类还有停用类,在解码阶段,各分类器的预测结果联合起来形成测试示例的编码,该编码与各类所对应的编码进行比较,将距离最小的编码所对应的类别作为预测结果。
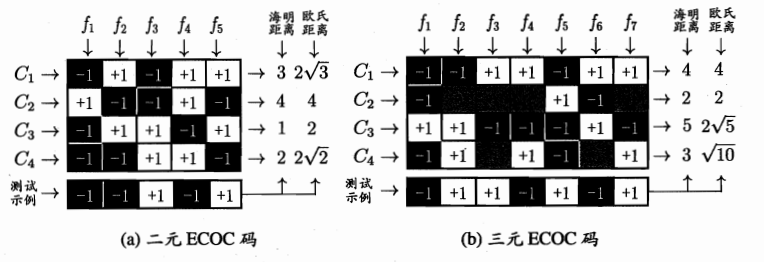
例如:在上图(1)中,f1分类器使得所有的C2为正例,其他为反例,f2分类器使得C1,C3为正,剩余分类器如图所示,因此可以得到一串输入码,以C1为例,其输入码为(-1,+1,-1,+1,+1)对于测试用例(-1,-1,+1,-1,+1)计算它与其他类的距离,即计算输入码和测试用例的欧式距离以C1和测试用例为例=(-1-1)2+(+1-1)2+(-1-1)2+(+1+1)2+(+1-1)2=12½
海明距离:
多分类问题multicalss classification的更多相关文章
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
- 吴恩达机器学习笔记28-多类分类(Multiclass Classification)
当我们有不止两种分类时(也就是
- 脸型分类-Face shape classification using Inception v3
本文链接:https://blog.csdn.net/u011961856/article/details/77984667函数解析github 代码:https://github.com/adoni ...
- 感知机分类(perceptron classification)
概述 在机器学习中,感知机(perceptron)是二分类的线性分类模型,属于监督学习算法.输入为实例的特征向量,输出为实例的类别(取+1和-1). 感知机对应于输入空间中将实例划分为两类的分离超平面 ...
- 第三章——分类(Classification)
3.1 MNIST 本章介绍分类,使用MNIST数据集.该数据集包含七万个手写数字图片.使用Scikit-Learn函数即可下载该数据集: >>> from sklearn.data ...
- stanford coursera 机器学习编程作业 exercise 3(逻辑回归实现多分类问题)
本作业使用逻辑回归(logistic regression)和神经网络(neural networks)识别手写的阿拉伯数字(0-9) 关于逻辑回归的一个编程练习,可参考:http://www.cnb ...
- 【Todo】【转载】Spark学习 & 机器学习(实战部分)-监督学习、分类与回归
理论原理部分可以看这一篇:http://www.cnblogs.com/charlesblc/p/6109551.html 这里是实战部分.参考了 http://www.cnblogs.com/shi ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- CART分类与回归树与GBDT(Gradient Boost Decision Tree)
一.CART分类与回归树 资料转载: http://dataunion.org/5771.html Classification And Regression Tree(CART)是决策 ...
随机推荐
- 【转】关系映射文件***.hbm.xml详解
http://blog.sina.com.cn/s/blog_7ffb8dd5010144yo.html 附.Oracle使用标准.可变长度的内部格式来存储数字.这个内部格式精度可以高达38位. NU ...
- OC基础(4)
NSString 类介绍及用法 结构体成员变量 对象和方法之间的关系 对象作为方法的参数连续传递 *:first-child { margin-top: 0 !important; } body &g ...
- 【转】WEB测试到移动测试的转换
移动互联网的发展毋庸置疑是必然的趋势,我们曾经传统WEB互联网测试的同学,也必然走上移动测试的道路,移动测试与pc测试到底需要怎样的思维转变才能更快的进入移动节奏呢?对比下WEB与移动的测试不同点: ...
- PL/0与Pascal-S编译器程序详细注释
学校编译课的作业之一,要求阅读两个较为简单的编译器的代码并做注释, 个人感觉是一次挺有意义的锻炼, 将自己的心得分享出来与一同在进步的同学们分享. 今后有时间再做进一步的更新和总结,其中可能有不少错误 ...
- 基于Web的企业网和互联网的信息和应用( 1194.22 )
基于Web的企业网和互联网的信息和应用( 1194.22 ) 原文更新日期: 2001年6月21日原文地址: http://www.access-board.gov/sec508/guide/1194 ...
- ant风格是什么?
我们在看java技术书籍的过程中,当加载文件时总会遇到是否支持ant风格路径加载,这里说的ant风格是什么意思呢,今天我查了一下,明白了什么意思,现在总结一下 ANT通配符有三种: 通配符 说明 ? ...
- iOS百度地图探索
新建工程后,几项准备: 1.工程中一个文件设为.mm后缀 2.在Xcode的Project -> Edit Active Target -> Build -> Linking -&g ...
- sql语句小练习一
create database aaa go use aaa go create table student( sno varchar(3), sname varchar(4) not null ...
- 做好SEO需要掌握的20个基础知识
作为一个网站优化者,有一些基础seo知识点是大家必须要掌握的,网站排名的好快,和这些基础的SEO优化知识有没做好,有没做到位,有着直接的关系!今天,伟伟SEO就把我前面讲的SEO优化基础知识做个总结, ...
- 【MVC】ASP.NET MVC HtmlHelper用法大全
1.ActionLink <%=Html.ActionLink("这是一个连接", "Index", "Home")%> 带 ...