Linux 性能监测:介绍
看了某某教程、读了某某手册,按照要求改改某某设置、系统设定、内核参数就认为做到系统优化的想法很傻很天真:)系统优化是一项复杂、繁琐、长期的 工作,优化前需要监测、采集、测试、评估,优化后也需要测试、采集、评估、监测,而且是一个长期和持续的过程,不是说现在优化了,测试了,以后就可以一劳 永逸了,也不是说书本上的优化就适合眼下正在运行的系统,不同的系统、不同的硬件、不同的应用优化的重点也不同、优化的方法也不同、优化的参数也不同。性 能监测是系统优化过程中重要的一环,如果没有监测、不清楚性能瓶颈在哪里,优化什么呢、怎么优化呢?所以找到性能瓶颈是性能监测的目的,也是系统优化的关 键。系统由若干子系统构成,通常修改一个子系统有可能影响到另外一个子系统,甚至会导致整个系统不稳定、崩溃。所以说优化、监测、测试通常是连在一起的, 而且是一个循环而且长期的过程,通常监测的子系统有以下这些:
- CPU
- Memory
- IO
- Network
这些子系统互相依赖,了解这些子系统的特性,监测这些子系统的性能参数以及及时发现可能会出现的瓶颈对系统优化很有帮助。
应用类型
不同的系统用途也不同,要找到性能瓶颈需要知道系统跑的是什么应用、有些什么特点,比如 web server 对系统的要求肯定和 file server 不一样,所以分清不同系统的应用类型很重要,通常应用可以分为两种类型:
- IO 相关,IO 相关的应用通常用来处理大量数据,需要大量内存和存储,频繁 IO 操作读写数据,而对 CPU 的要求则较少,大部分时候 CPU 都在等待硬盘,比如,数据库服务器、文件服务器等。
- CPU 相关,CPU 相关的应用需要使用大量 CPU,比如高并发的 web/mail 服务器、图像/视频处理、科学计算等都可被视作 CPU 相关的应用。
看看实际中的例子,第1个是文件服务器拷贝一个大文件时表现出来的特征:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 4 140 1962724 335516 4852308 0 0 388 65024 1442 563 0 2 47 52 0
0 4 140 1961816 335516 4853868 0 0 768 65536 1434 522 0 1 50 48 0
0 4 140 1960788 335516 4855300 0 0 768 48640 1412 573 0 1 50 49 0
0 4 140 1958528 335516 4857280 0 0 1024 65536 1415 521 0 1 41 57 0
0 5 140 1957488 335516 4858884 0 0 768 81412 1504 609 0 2 50 49 0
第2个是 CPU 做大量计算时表现出来的特征:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 140 3625096 334256 3266584 0 0 0 16 1054 470 100 0 0 0 0
4 0 140 3625220 334264 3266576 0 0 0 12 1037 448 100 0 0 0 0
4 0 140 3624468 334264 3266580 0 0 0 148 1160 632 100 0 0 0 0
4 0 140 3624468 334264 3266580 0 0 0 0 1078 527 100 0 0 0 0
4 0 140 3624712 334264 3266580 0 0 0 80 1053 501 100 0 0 0 0
上面两个例子最明显的差别就是 id 一栏,代表 CPU 的空闲率,拷贝文件时候 id 维持在 50% 左右,CPU 大量计算的时候 id 基本为 0。
底线
我们如何知道系统性能是好还是差呢?这需要事先建立一个底线,如果性能监测得到的统计数据跨过这条线,我们就可以说这个系统性能差,如果数据能保持 在线内我们就说性能好。建立这样底线需要知道一些理论、额外的负载测试和系统管理员多年的经验。如果自己没有多年的经验,有一个简单划底线的办法就是:把 这个底线建立在自己对系统的期望上。自己期望这个系统有个什么样的性能,这是一个底线,如果没有达到这个要求就是性能差。比如,VPSee 上个月有个 RAID0 的测试, 期望的测试结果应该是 RAID0 的 IO 性能比单硬盘有显著提高,底线是 RAID0 的 IO 至少要比单硬盘要好(好多少不重要,底线是至少要好),测试结果却发现 RAID0 性能还不如单硬盘,说明性能差,这个时候需要问个为什么,这往往是性能瓶颈所在,经过排查发现是原硬盘有硬件瑕疵造成性能测试结果错误。
监测工具
我们只需要简单的工具就可以对 Linux 的性能进行监测,以下是 VPSee 常用的工具:
| 工具 | 简单介绍 |
|---|---|
| top | 查看进程活动状态以及一些系统状况 |
| vmstat | 查看系统状态、硬件和系统信息等 |
| iostat | 查看CPU 负载,硬盘状况 |
| sar | 综合工具,查看系统状况 |
| mpstat | 查看多处理器状况 |
| netstat | 查看网络状况 |
| iptraf | 实时网络状况监测 |
| tcpdump | 抓取网络数据包,详细分析 |
| tcptrace | 数据包分析工具 |
| netperf | 网络带宽工具 |
| dstat | 综合工具,综合了 vmstat, iostat, ifstat, netstat 等多个信息 |
一个完整运行的 Linux 系统包括很多子系统(介绍,CPU,Memory,IO,Network,…),监测和评估这些子系统是性能监测的一部分。我们往往需要宏观的看整个系统状态,也需要微观的看每个子系统的运行情况。
幸运的是,我们不必重复造轮子,监控这些子系统都有相应的工具可用,这些经过时间考验、随 Unix 成长起来、简单而优雅的小工具是我们日常 Unix/Linux 工作不可缺少的部分。
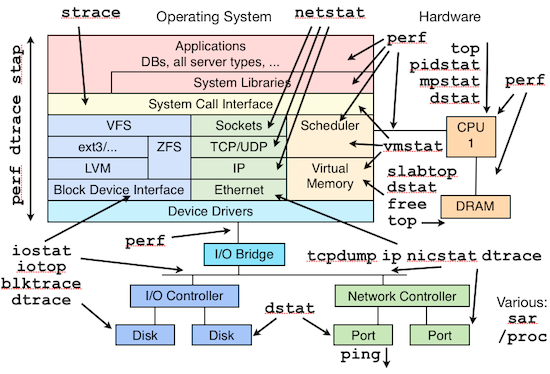
下面这张图片很好的总结了 Linux 各个子系统以及监控这些子系统所需要的工具,如果你对 Linux 系统管理(sysadmin & devops)感兴趣、想入门的话,可以从这张图开始慢慢了解和熟悉各个工具。对于熟练的 Linux 屌丝,这张图你应该能问答自如。(图片来自:Linux Performance Analysis and Tools,幻灯片也很精彩,建议对照阅读。)
Linux 性能监测:介绍的更多相关文章
- Linux性能监测:监测目的与工具介绍
性能监测是系统优化过程中重要的一环,如果没有监测.不清楚性能瓶颈在哪里,优化什么呢.怎么优化呢?所以找到性能瓶颈是性能监测的目的,也是系统优化的关键.本文对Linux性能监测的应用类型.底线和监测工具 ...
- Linux性能监测
1.Linux性能监测:监测目的与工具介绍 看了某某教程.读了某某手册,按照要求改改某些设置.系统设定.内核参数就认为做到系统优化的想法很傻很天真:)系统优化是一项复杂.繁琐.长期的工作,优化前需要监 ...
- Linux性能监测:CPU篇(转)
http://os.51cto.com/art/201012/239880.htm CPU 的占用主要取决于什么样的资源正在 CPU 上面运行,比如拷贝一个文件通常占用较少 CPU,因为大部分工作是由 ...
- Linux 性能监测:Memory
这里的讲到的 "内存" 包括物理内存和虚拟内存,虚拟内存(Virtual Memory)把计算机的内存空间扩展到硬盘,物理内存(RAM)和硬盘的一部分空间(SWAP)组合在一起作为 ...
- Linux 性能监测:CPU
CPU 的占用主要取决于什么样的资源正在 CPU 上面运行,比如拷贝一个文件通常占用较少 CPU,因为大部分工作是由 DMA(Direct Memory Access)完成,只是在完成拷贝以后给一个中 ...
- Linux性能监测:监测目的与工具
Linux性能监测:监测目的与工具介绍 系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不是说现在优化了,测试了 ...
- Linux性能监测:内存篇
在操作系统里,虚拟内存被分成页,在 x86 系统上每个页大小是 4KB.Linux 内核读写虚拟内存是以 “页” 为单位操作的,把内存转移到硬盘交换空间(SWAP)和从交换空间读取到内存的时候都是按页 ...
- Linux性能监测:CPU篇
CPU 也是一种硬件资源,和任何其他硬件设备一样也需要驱动和管理程序才能使用,我们可以把内核的进程调度看作是 CPU 的管理程序,用来管理和分配 CPU 资源,合理安排进程抢占 CPU,并决定哪个进程 ...
- Linux性能工具介绍
l Linux性能工具介绍 p CPU高 p 磁盘I/O p 网络 p 内存 p 应用程序跟踪 l 操作系统与应用程序的关系比喻为“唇亡齿寒”一点不为过 l 应用程序的性能问题/功能问 ...
- pyDash:一个基于 web 的 Linux 性能监测工具
pyDash 是一个轻量且基于 web 的 Linux 性能监测工具,它是用 Python 和 Django 加上 Chart.js 来写的.经测试,在下面这些主流 Linux 发行版上可运行:Cen ...
随机推荐
- 锋利的JQuery(二)
释义: DOM:Document Object Model 文档对象模型 DOM操作细分:DOM Core .HTML-DOM.CSS-DOM text():对HTML文档和XML文档都有效
- 启用 TStringGrid 的自画功能,并避免重影
FMX 控件的 TStringGrid 下,有时为了让不同行或不同 Cell 的显示颜色.字体等有各种不同的颜色, 必须采用自画, 即在其 OnDrawColumnCell 事件中写自己的控制代码显示 ...
- PHP用substr截取字符串出现中文乱码问题用mb_substr
PHP用substr截取字符串出现中文乱码问题用mb_substr实例:mb_substr('截取中文乱码问题测试',0,5, 'utf-8'); 语法 : string substr (string ...
- jQuery上传插件,文件上传测试用例
jQuery上传插件,文件上传测试用例 jQuery File Upload-jQuery上传插件介绍http://www.jq22.com/jquery-info230 jQuery File Up ...
- Intel Edison
起步: https://software.intel.com/zh-cn/node/628224 刷机: https://software.intel.com/zh-cn/flashing-firmw ...
- NEON简介【转】
转自:http://blog.csdn.net/fengbingchun/article/details/38020265 版权声明:本文为博主原创文章,未经博主允许不得转载. “ARM Advanc ...
- plsql日期乱码
乱码状况如截图: 控制面板\所有控制面板项\系统\高级系统设置\环境变量, 设置系统变量,变量名:NLS_LANG,变量值:Simplified Chinese_China.AL32UTF8改为SIM ...
- struts2-json-plugin插件实现异步通信
用例需要依赖的jar: struts2-core.jar struts2-convention-plugin.jar,非必须, struts2-json-plugin.jar org.codehaus ...
- web.xml中 error-page的正确用法
<error-page> <error-code>404</error-code> <location>/mvc/hello1?i=1</loca ...
- HDU 3078:Network(LCA之tarjan)
http://acm.hdu.edu.cn/showproblem.php?pid=3078 题意:给出n个点n-1条边m个询问,每个点有个权值,询问中有k,u,v,当k = 0的情况是将u的权值修改 ...