全栈一路坑(4)——创建博客的API
上一篇博客:全站之路一路坑(3)——使用百度站长工具提交站点地图
这一篇要搭建一个API平台,一是为了给博客补充一些功能,二是为以后做APP提供数据接口。
首先需要安装Django REST Framework的RESTful API库,记得先打开virtualenv,避免全局污染。
pip install djangorestframework
然后添加到INSTALLED_APPS中
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blogpost',
'django.contrib.sites',
'django.contrib.flatpages',
'django_comments',
'django.contrib.sitemaps',
'rest_framework',
]
然后添加url
urlpatterns = [
url(r'^$', 'blogpost.views.index', name='main'),
url(r'^index.html$', 'blogpost.views.index', name='main'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^admin/', admin.site.urls),
url(r'^pages/', include('django.contrib.flatpages.urls')),
url(r'^comments/', include('django_comments.urls')),
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap'),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework')),
]
准备工作完成,先来创建一个博客列表的API,在blogpost下面创建一个serializers.py的文件。BlogpostSet用来定义视图的展现形式,返回需要展示的内容,BlogpostSerializers用户定义API的表现形式,返回哪些字段,返回怎样的格式
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets
from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
queryset = Blogpost.objects.all()
serializer_class = BlogpostSerializer
然后配置url,添加
from django.conf.urls import url, include
from django.contrib import admin
from django.contrib.sitemaps.views import sitemap
from sitemap.sitemaps import PageSitemap, FlatPageSitemap, BlogSitemap
from rest_framework import routers
from blogpost.serializers import BlogpostSet sitemaps = {
"page": PageSitemap,
'flatpages': FlatPageSitemap,
'blog': BlogSitemap
} apiRouter = routers.DefaultRouter()
apiRouter.register(r'blogpost', BlogpostSet) urlpatterns = [
url(r'^$', 'blogpost.views.index', name='main'),
url(r'^index.html$', 'blogpost.views.index', name='main'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^admin/', admin.site.urls),
url(r'^pages/', include('django.contrib.flatpages.urls')),
url(r'^comments/', include('django_comments.urls')),
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap'),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework')),
url(r'^api/', include(apiRouter.urls)),
]
然后访问http://127.0.0.1:8000/api/

点击链接之后就可以看到博客列表的API了
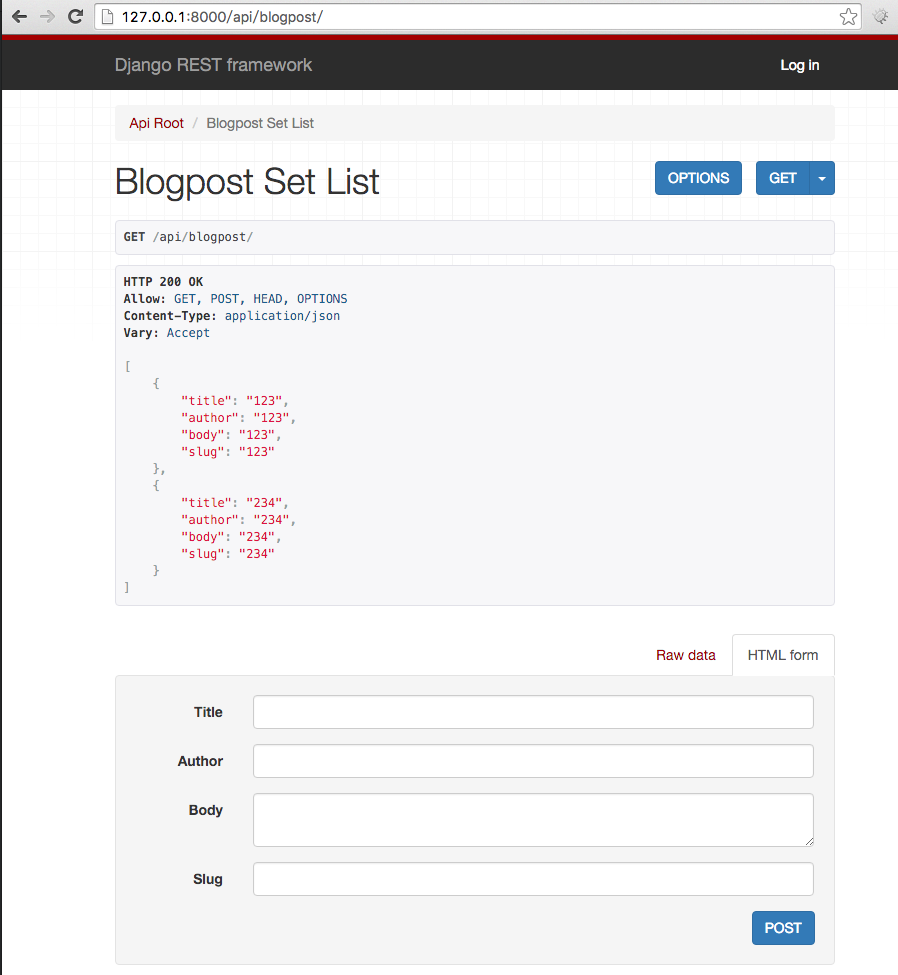
自动完成API
自动完成API其实就是一个搜索接口,首先修改一下博客API,添加了一个搜索字段search_fields,指向title
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets, permissions
from rest_framework.response import Response from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
serializer_class = BlogpostSerializer
search_fields = 'title' def list(self, request):
queryset = Blogpost.objects.all()
search_param = self.request.query_params.get('title', None)
if search_param is not None:
queryset = Blogpost.objects, filter(title__contains=search_param)
serializers = BlogpostSerializer(queryset, many=True)
return Response(serializers.data)
然后测试报错了

作者的代码又一次出错了,修改代码如下
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets, permissions
from rest_framework.response import Response from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
serializer_class = BlogpostSerializer
search_fields = 'title' def get_queryset(self):
return Blogpost.objects.all() def list(self, request):
queryset = Blogpost.objects.all()
search_param = self.request.query_params.get('title', None)
if search_param is not None:
queryset = Blogpost.objects.filter(title__contains=search_param)
serializers = BlogpostSerializer(queryset, many=True)
return Response(serializers.data)
然后就是一段前端的工作了,由于我直接把前端代码拷贝过来了,所以直接能用了

然后就是每一个做API都头疼的问题了,跨域问题
首先添加django-cors-headers
pip install django-cors-headers
然后注册它
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blogpost',
'django.contrib.sites',
'django.contrib.flatpages',
'django_comments',
'django.contrib.sitemaps',
'rest_framework',
'corsheaders',
]
还要注册中间件
MIDDLEWARE_CLASSES = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware',
'corsheaders.middleware.CorsMiddleware',
]
然后在settings.py中再添加对应的配置
CORS_ALLOW_CREDENTIALS = True
上传完代码之后测试一下,pycharm自带了一个很方便的测试restful服务器的工具
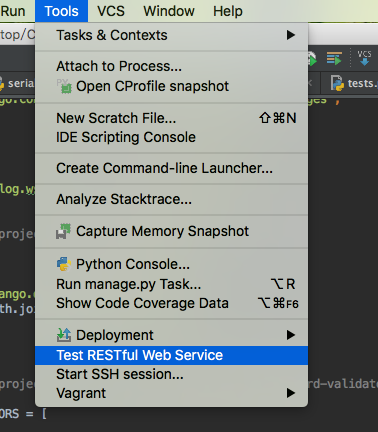
填入相关的测试信息
然后得到了正确的结果

至此,服务端的开发工作暂时就告一段落了,下一篇将开始移动端的开发。
全栈一路坑(4)——创建博客的API的更多相关文章
- 全栈一路坑之使用django创建博客
最近在看一篇全栈增长工程师实战,然后学习里面的项目,结果发现作者用的技术太过老旧,好多东西都已经被抛弃了,所以结合着官方文档和自己的一些理解将错误的信息替换一下,边写边学习 准备工作和工具 作者说需要 ...
- Vue、Node全栈项目~面向小白的博客系统~
个人博客系统 前言 ❝ 代码质量问题轻点喷(去年才学的前端),有啥建议欢迎联系我,联系方式见最下方,感谢! 页面有啥bug也可以反馈给我,感谢! 这是一套包含前后端代码的个人博客系统,欢迎各位提出建议 ...
- 初试Nodejs——使用keystonejs创建博客网站2(修改模板)
上一篇(初试Nodejs——使用keystonejs创建博客网站1(安装keystonejs))讲了keystonejs的安装.安装完成后,已经具备了基本的功能,我们需要对页面进行初步修改,比如,增加 ...
- 在 Windows Azure 网站上使用 Django、Python 和 MySQL:创建博客应用程序
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 撰写. 根据您编写的应用程序,Windows Azure 网站上的基本Python 堆 ...
- 使用GitHub-Pages创建博客和图片上传问题解决
title: 使用GitHub Pages创建博客和图片上传问题解决 date: 2017-10-22 20:44:11 tags: IT 技术 toc: true 搭建博客 博客的搭建过程完全参照小 ...
- Django快速创建博客,包含了整个框架使用过程,简单易懂
创建工程 ...
- Flask+ Angularjs 实例: 创建博客
允许任何用户注册 允许注册的用户登录 允许登录的用户创建博客 允许在首页展示博客 允许登录的用户退 后端 Flask-RESTful - Flask 的 RESTful 扩展 Flask-SQLAlc ...
- 使用hexo,创建博客
下载hexo工具 1 npm install hexo-cli -g 下载完成后可以在命令行下生成一个全局命令hexo搭建博客可用thinkjs 创建一个博客文件夹 1 hexo init 博客文件夹 ...
- 基于hexo创建博客(Github托管)
基于hexo的博客 搭建好的博客网站 dengshuo7412.com 搭建步骤 1.依赖文件下载 Node.js 2.Hexo的安装 3.部署到Github 4.Hexo创建博客基本操作 5.Hex ...
随机推荐
- 实时视频h5
http://www.cnblogs.com/dotfun/p/4286878.html
- 导入50G文件到mysql,然后再倒入sqlserver
--导入大文件50G文件到mysql1.修改配置innodb_flush_log_at_trx_commit=0 2.导入时的注意事项set autocommit=1;show variables l ...
- POJ 3321:Apple Tree(dfs序+树状数组)
题目大意:对树进行m次操作,有两类操作,一种是改变一个点的权值(将0变为1,1变为0),另一种为查询以x为根节点的子树点权值之和,开始时所有点权值为1. 分析: 对树进行dfs,将树变为序列,记录每个 ...
- [python]做一个简单爬虫
为什么选择python,它强大的库可以让你专注在爬虫这一件事上而不是更底层的更繁杂的事 爬虫说简单很简单,说麻烦也很麻烦,完全取决于你的需求是什么以及你爬的网站所决定的,遇到的第一个简单的例子是pas ...
- BZOJ3561 DZY Loves Math VI 【莫比乌斯反演】
题目 给定正整数n,m.求 输入格式 一行两个整数n,m. 输出格式 一个整数,为答案模1000000007后的值. 输入样例 5 4 输出样例 424 提示 数据规模: 1<=n,m<= ...
- IPFS
http://www.r9it.com/20190412/ipfs-private-net.html IPFS指令集中文版(一) https://www.jianshu.com/p/ce74b32d2 ...
- C语言中 单引号与双引号的区别
在C语言中,字符用单引号,字符串用双引号.在c1='a';中,'a'是字符常量,必须用单引号."a"表示字符串,包含两个字符,一个是'a',一个是'\0'. 用数组来存储字符串. ...
- Vue中slot内容分发
<slot>元素是一个内容分发API,使用多个内容插槽时可指定name属性 <!DOCTYPE html> <html> <head> <meta ...
- jquery 实践操作:attr()方法
此篇要记录的是 关于 jquery 的 attr() 方法 在JS中设置节点的属性与属性值用到setAttribute(),获得节点的属性与属性值用到getAttribute(),而在jquery中 ...
- 勒索病毒 -- “永恒之蓝”NSA 武器免疫工具
“永恒之蓝”NSA 武器免疫工具 针对 445 端口:445端口是一个毁誉参半的端口,他和139端口一起是IPC$入侵的主要通道.有了它我们可以在局域网中轻松访问各种共享文件夹或共享打印机,但也正是因 ...