全栈一路坑(4)——创建博客的API
上一篇博客:全站之路一路坑(3)——使用百度站长工具提交站点地图
这一篇要搭建一个API平台,一是为了给博客补充一些功能,二是为以后做APP提供数据接口。
首先需要安装Django REST Framework的RESTful API库,记得先打开virtualenv,避免全局污染。
pip install djangorestframework
然后添加到INSTALLED_APPS中
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blogpost',
'django.contrib.sites',
'django.contrib.flatpages',
'django_comments',
'django.contrib.sitemaps',
'rest_framework',
]
然后添加url
urlpatterns = [
url(r'^$', 'blogpost.views.index', name='main'),
url(r'^index.html$', 'blogpost.views.index', name='main'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^admin/', admin.site.urls),
url(r'^pages/', include('django.contrib.flatpages.urls')),
url(r'^comments/', include('django_comments.urls')),
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap'),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework')),
]
准备工作完成,先来创建一个博客列表的API,在blogpost下面创建一个serializers.py的文件。BlogpostSet用来定义视图的展现形式,返回需要展示的内容,BlogpostSerializers用户定义API的表现形式,返回哪些字段,返回怎样的格式
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets
from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
queryset = Blogpost.objects.all()
serializer_class = BlogpostSerializer
然后配置url,添加
from django.conf.urls import url, include
from django.contrib import admin
from django.contrib.sitemaps.views import sitemap
from sitemap.sitemaps import PageSitemap, FlatPageSitemap, BlogSitemap
from rest_framework import routers
from blogpost.serializers import BlogpostSet sitemaps = {
"page": PageSitemap,
'flatpages': FlatPageSitemap,
'blog': BlogSitemap
} apiRouter = routers.DefaultRouter()
apiRouter.register(r'blogpost', BlogpostSet) urlpatterns = [
url(r'^$', 'blogpost.views.index', name='main'),
url(r'^index.html$', 'blogpost.views.index', name='main'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^admin/', admin.site.urls),
url(r'^pages/', include('django.contrib.flatpages.urls')),
url(r'^comments/', include('django_comments.urls')),
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap'),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework')),
url(r'^api/', include(apiRouter.urls)),
]
然后访问http://127.0.0.1:8000/api/

点击链接之后就可以看到博客列表的API了
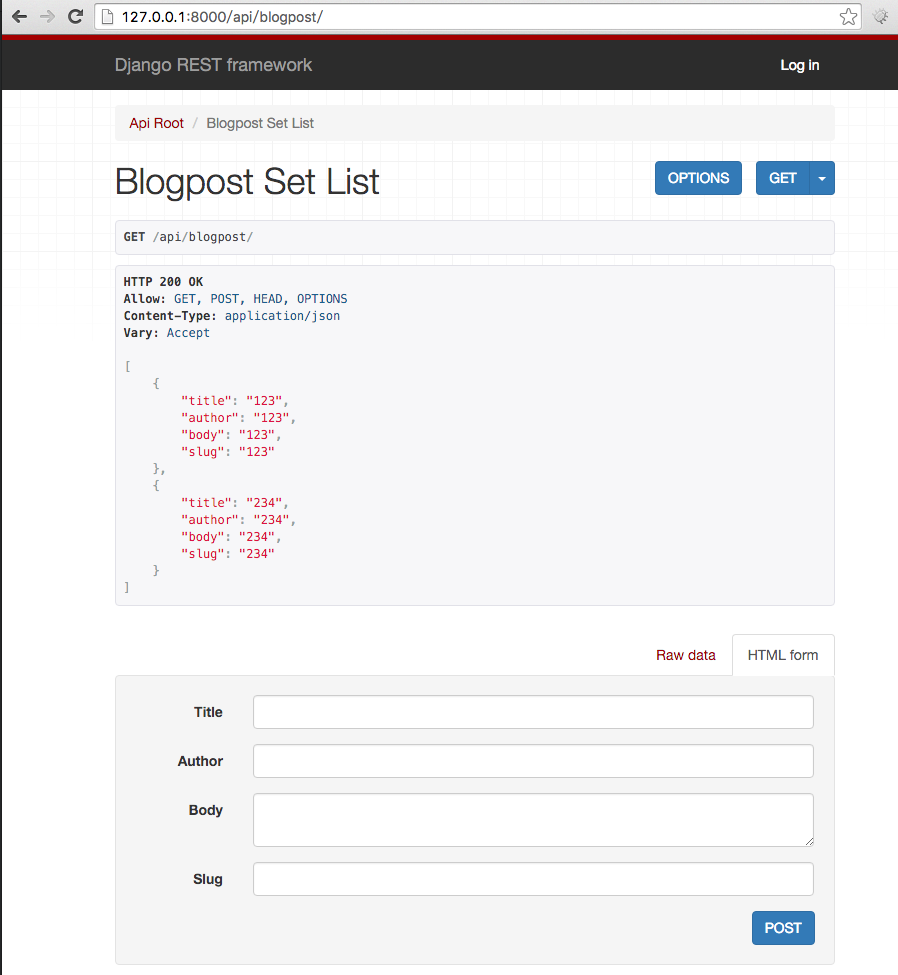
自动完成API
自动完成API其实就是一个搜索接口,首先修改一下博客API,添加了一个搜索字段search_fields,指向title
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets, permissions
from rest_framework.response import Response from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
serializer_class = BlogpostSerializer
search_fields = 'title' def list(self, request):
queryset = Blogpost.objects.all()
search_param = self.request.query_params.get('title', None)
if search_param is not None:
queryset = Blogpost.objects, filter(title__contains=search_param)
serializers = BlogpostSerializer(queryset, many=True)
return Response(serializers.data)
然后测试报错了

作者的代码又一次出错了,修改代码如下
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets, permissions
from rest_framework.response import Response from blogpost.models import Blogpost class BlogpostSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug') class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
serializer_class = BlogpostSerializer
search_fields = 'title' def get_queryset(self):
return Blogpost.objects.all() def list(self, request):
queryset = Blogpost.objects.all()
search_param = self.request.query_params.get('title', None)
if search_param is not None:
queryset = Blogpost.objects.filter(title__contains=search_param)
serializers = BlogpostSerializer(queryset, many=True)
return Response(serializers.data)
然后就是一段前端的工作了,由于我直接把前端代码拷贝过来了,所以直接能用了

然后就是每一个做API都头疼的问题了,跨域问题
首先添加django-cors-headers
pip install django-cors-headers
然后注册它
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blogpost',
'django.contrib.sites',
'django.contrib.flatpages',
'django_comments',
'django.contrib.sitemaps',
'rest_framework',
'corsheaders',
]
还要注册中间件
MIDDLEWARE_CLASSES = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware',
'corsheaders.middleware.CorsMiddleware',
]
然后在settings.py中再添加对应的配置
CORS_ALLOW_CREDENTIALS = True
上传完代码之后测试一下,pycharm自带了一个很方便的测试restful服务器的工具
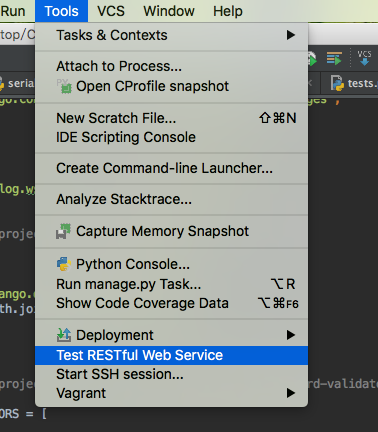
填入相关的测试信息
然后得到了正确的结果

至此,服务端的开发工作暂时就告一段落了,下一篇将开始移动端的开发。
全栈一路坑(4)——创建博客的API的更多相关文章
- 全栈一路坑之使用django创建博客
最近在看一篇全栈增长工程师实战,然后学习里面的项目,结果发现作者用的技术太过老旧,好多东西都已经被抛弃了,所以结合着官方文档和自己的一些理解将错误的信息替换一下,边写边学习 准备工作和工具 作者说需要 ...
- Vue、Node全栈项目~面向小白的博客系统~
个人博客系统 前言 ❝ 代码质量问题轻点喷(去年才学的前端),有啥建议欢迎联系我,联系方式见最下方,感谢! 页面有啥bug也可以反馈给我,感谢! 这是一套包含前后端代码的个人博客系统,欢迎各位提出建议 ...
- 初试Nodejs——使用keystonejs创建博客网站2(修改模板)
上一篇(初试Nodejs——使用keystonejs创建博客网站1(安装keystonejs))讲了keystonejs的安装.安装完成后,已经具备了基本的功能,我们需要对页面进行初步修改,比如,增加 ...
- 在 Windows Azure 网站上使用 Django、Python 和 MySQL:创建博客应用程序
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 撰写. 根据您编写的应用程序,Windows Azure 网站上的基本Python 堆 ...
- 使用GitHub-Pages创建博客和图片上传问题解决
title: 使用GitHub Pages创建博客和图片上传问题解决 date: 2017-10-22 20:44:11 tags: IT 技术 toc: true 搭建博客 博客的搭建过程完全参照小 ...
- Django快速创建博客,包含了整个框架使用过程,简单易懂
创建工程 ...
- Flask+ Angularjs 实例: 创建博客
允许任何用户注册 允许注册的用户登录 允许登录的用户创建博客 允许在首页展示博客 允许登录的用户退 后端 Flask-RESTful - Flask 的 RESTful 扩展 Flask-SQLAlc ...
- 使用hexo,创建博客
下载hexo工具 1 npm install hexo-cli -g 下载完成后可以在命令行下生成一个全局命令hexo搭建博客可用thinkjs 创建一个博客文件夹 1 hexo init 博客文件夹 ...
- 基于hexo创建博客(Github托管)
基于hexo的博客 搭建好的博客网站 dengshuo7412.com 搭建步骤 1.依赖文件下载 Node.js 2.Hexo的安装 3.部署到Github 4.Hexo创建博客基本操作 5.Hex ...
随机推荐
- JSP自定义tag控件标签
JSP支持自定tag的方法,那就是直接讲JSP代码保存成*.tag或者*.tagx的标签定义文件.tag和tagx文件不仅支持经典jsp代码,各种标签模版代码,还支持xml样式的jsp指令代码. 按照 ...
- logback mybatis 打印sql语句
logbac.xml 文件的基础配置参考的园友的 http://www.cnblogs.com/yuanermen/archive/2012/02/13/2349609.html 然后hibernat ...
- MySQL时间字段究竟使用INT还是DateTime
今天解析DEDECMS时发现deder的MYSQL时间字段,都是用 `senddata` ) unsigned '; 随后又在网上找到这篇文章,看来如果时间字段有参与运算,用int更好,一来检索时不用 ...
- 【LoadRunner】利用lr_db_connect函数对Oracle数据库压测的完整流程
项目中常常会有直接对数据库进行压测的需求,以前都是通过Jmeter实现的,但是Jmeter本身图表及结果收集方面没有Loadrunner那么强大,所以利用loadrunner工具自己的函数整理了一个脚 ...
- java中常用的几种缓存类型介绍
在平时的开发中会经常用到缓存,比如locache.redis等,但一直没有对缓存有过比较全面的总结.下面从什么是缓存.为什么使用缓存.缓存的分类以及对每种缓存的使用分别进行分析,从而对缓存有更深入的了 ...
- [oldboy-django][4python面试]有关yield那些事
1 yield 在使用send, next时候的区别(举例m = yield 5) 无论send,next首先理解m = yield 5 是将表达式"yield 5 "的结果返回给 ...
- [转]手写数字识别错误NameError: name 'mnist' is not defined
转自:https://blog.csdn.net/coder_Gray/article/details/78562382 在Tensorflow上进行mnist数字识别实例时,出现如下错误 NameE ...
- 获取完整的URL request.getQueryString()
public String codeToString(String str) { String strString = str; try { byte tempB[] = strString.getB ...
- iOS开发UI篇—自定义layer
一.第一种方式 1.简单说明 以前想要在view中画东西,需要自定义view,创建一个类与之关联,让这个类继承自UIView,然后重写它的DrawRect:方法,然后在该方法中画图. 绘制图形的步骤: ...
- Java实现简单的socket通信
今天学习了一下java如何实现socket通信,感觉难点反而是在io上,因为java对socket封装已经很完善了. 今天代码花了整个晚上调试,主要原因是io的flush问题和命令行下如何运行具有pa ...