ORM框架SQLAlchemy学习
一、基本介绍
以下介绍来自维基百科,自由的百科全书。
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。因此,SQLAlchmey采用了类似于Java里Hibernate的数据映射模型,而不是其他ORM框架采用的Active Record模型。不过,Elixir和declarative等可选插件可以让用户使用声明语法。
SQLAlchemy首次发行于2006年2月,并迅速地在Python社区中最广泛使用的ORM工具之一,不亚于Django的ORM框架。
SQLAlchemy-- > 第一步:将对象转换成SQL 第二步:使用数据API执行SQL并获取执行结果。
1.安装
# windows pip3 install sqlalchemy
# Linux $ easy_install sqlalchemy
2.流程介绍
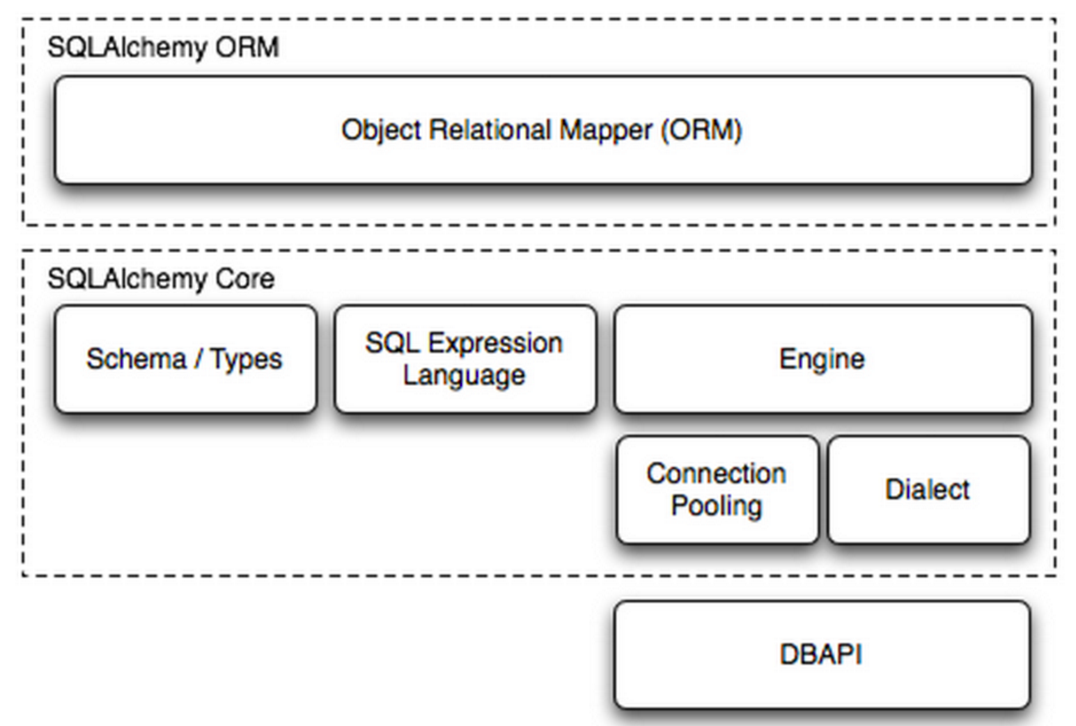
#1、使用者通过ORM对象提交命令
#2、将命令交给SQLAlchemy Core(Schema/Types SQL Expression Language)转换成SQL语句
#3、使用 Engine/ConnectionPooling/Dialect 进行数据库操作
# 3.1、匹配使用者事先配置好的egine
# 3.2、egine从连接池中取出一个链接
# 3.3、基于该链接通过Dialect调用DB API,将SQL转交给它去执行
简而言之:
#第一个阶段(流程1-2):将SQLAlchemy的对象换成可执行的sql语句 #第二个阶段(流程3):将sql语句交给数据库执行
可跳过第一阶段,即自己写sql语句,直接给数据库执行。
from sqlalchemy import create_engine #1 准备
# 需要事先安装好pymysql
# 需要事先创建好数据库:create database db1 charset utf8; #2 创建引擎
egine=create_engine('mysql+pymysql://root@127.0.0.1/db1?charset=utf8') #3 执行 自己写的sql语句
# egine.execute('create table if not EXISTS t1(id int PRIMARY KEY auto_increment,name char(32));') # cur=egine.execute('insert into t1 values(%s,%s);',[(1,"egon1"),(2,"egon2"),(3,"egon3")]) #按位置传值 # cur=egine.execute('insert into t1 values(%(id)s,%(name)s);',name='egon4',id=4) #按关键字传值 #4 新插入行的自增id
# print(cur.lastrowid) #5 查询
cur=egine.execute('select * from t1') cur.fetchone() #获取一行
cur.fetchmany(2) #获取多行
cur.fetchall() #获取所有行
3. DB API 介绍
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,常见的几种配置如下:
#1、MySQL-mysqldb
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> #2、MySQL-pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options> #3、MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> #4、cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
二、创建表
ORM中:
# 类名 ===> 表名
# 对象 ===> 表中的一行记录
需求:
创建四张表:业务线,服务,用户,角色,利用ORM创建出它们,并建立好它们直接的关系
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,DateTime,Enum,ForeignKey,UniqueConstraint,ForeignKeyConstraint,Index
from sqlalchemy.orm import sessionmaker # 引擎使用pymysql链接数据库
egine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() #创建单表:业务线
class Business(Base):
__tablename__='business' # 表名 business
id=Column(Integer,primary_key=True,autoincrement=True) # 主键 + 自动创建
bname=Column(String(32),nullable=False,index=True) # 长度32 可以为空?False !不可以 #多对一:多个服务可以属于一个业务线,多个业务线不能包含同一个服务
class Service(Base):
__tablename__='service' # 表名 service
id=Column(Integer,primary_key=True,autoincrement=True) # 主键 + 自动创建
sname=Column(String(32),nullable=False,index=True)
ip=Column(String(15),nullable=False)
port=Column(Integer,nullable=False) business_id=Column(Integer,ForeignKey('business.id')) # 外键关联业务线ID __table_args__=(
UniqueConstraint(ip,port,name='uix_ip_port'),
Index('ix_id_sname',id,sname)
) #一对一:一种角色只能管理一条业务线,一条业务线只能被一种角色管理
class Role(Base):
__tablename__='role'
id=Column(Integer,primary_key=True,autoincrement=True)
rname=Column(String(32),nullable=False,index=True)
priv=Column(String(64),nullable=False) business_id=Column(Integer,ForeignKey('business.id'),unique=True) # 唯一 #多对多:多个用户可以是同一个role,多个role可以包含同一个用户
class Users(Base):
__tablename__='users'
id=Column(Integer,primary_key=True,autoincrement=True)
uname=Column(String(32),nullable=False,index=True) class Users2Role(Base):
__tablename__='users2role'
id=Column(Integer,primary_key=True,autoincrement=True)
uid=Column(Integer,ForeignKey('users.id'))
rid=Column(Integer,ForeignKey('role.id')) __table_args__=(
UniqueConstraint(uid,rid,name='uix_uid_rid'), # 联合唯一索引
) # 全部创建
def init_db():
Base.metadata.create_all(egine) # 全部删除
def drop_db():
Base.metadata.drop_all(egine) if __name__ == '__main__':
init_db() # 注:设置外键的另一种方式 ForeignKeyConstraint(['other_id'], ['othertable.other_id'])
三、基本操作(增删改查)
表结构:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import sessionmaker # sqlalchemy通过pymysql第三方插件链接mysql数据库进行操作
egine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工(只有初创公司才把员工当骆驼用,一个员工身兼数职)
class Dep(Base):
__tablename__='dep' # 部门
id=Column(Integer,primary_key=True,autoincrement=True)
dname=Column(String(64),nullable=False,index=True) class Emp(Base):
__tablename__='emp' # 员工
id=Column(Integer,primary_key=True,autoincrement=True)
ename=Column(String(32),nullable=False,index=True)
dep_id=Column(Integer,ForeignKey('dep.id')) # 外键关联所属部门ID def init_db():
Base.metadata.create_all(egine) def drop_db():
Base.metadata.drop_all(egine) drop_db() # 全部删除
init_db() # 全部创建 Session=sessionmaker(bind=egine)
session=Session()
增加
# 一次增加一个
row_obj=Dep(dname='销售') # 按关键字传参,无需指定id,因其是自增长的
session.add(row_obj) # 一次增加多个
session.add_all([
Dep(dname='技术'),
Dep(dname='运营'),
Dep(dname='人事'),
]) # add之后需要commit
session.commit()
删除
# session.query(类名) filter(过滤条件)
session.query(Dep).filter(Dep.id > 3).delete() # 删除之后要commit
session.commit()
修改
# 修改
session.query(Dep).filter(Dep.id ==2).update({'dname':'财务'})
session.query(Dep).filter(Dep.id > 1).update({'dname':Dep.dname+'_ABC'},synchronize_session=False)
session.query(Dep).filter(Dep.id < 9).update({'id':Dep.id*100},synchronize_session='evaluate') # 修改后别忘记commit
session.commit()
查询
# 查所有,取所有字段
res=session.query(Dep).all()
for row in res:
print(row.id,row.dname) # 查所有,取指定字段
res=session.query(Dep.dname).order_by(Dep.id).all() # 根据id分组
for row in res:
print(row.dname) # 查表中第一条记录
res=session.query(Dep.dname).first()
print(res) # 过滤查询
res=session.query(Dep).filter(Dep.id > 1,Dep.id <1000) #逗号分隔,默认为and
print([(row.id,row.dname) for row in res])
四、高级查询
表结构
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import sessionmaker egine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工(只有创建公司才把员工当骆驼用,一个员工身兼数职)
class Dep(Base):
__tablename__='dep' # 部门
id=Column(Integer,primary_key=True,autoincrement=True)
dname=Column(String(64),nullable=False,index=True) class Emp(Base):
__tablename__='emp' # 人员
id=Column(Integer,primary_key=True,autoincrement=True)
ename=Column(String(32),nullable=False,index=True)
dep_id=Column(Integer,ForeignKey('dep.id')) def init_db():
Base.metadata.create_all(egine) def drop_db():
Base.metadata.drop_all(egine) drop_db()
init_db() Session=sessionmaker(bind=egine)
session=Session() # 准备数据
session.add_all([
Dep(dname='技术'),
Dep(dname='销售'),
Dep(dname='运营'),
Dep(dname='人事'),
]) session.add_all([
Emp(ename='1号',dep_id=1),
Emp(ename='2号',dep_id=1),
Emp(ename='3号',dep_id=1),
Emp(ename='4号',dep_id=2),
Emp(ename='5号',dep_id=3),
Emp(ename='6号',dep_id=4),
Emp(ename='7号',dep_id=2),
Emp(ename='8号',dep_id=4),
Emp(ename='9号',dep_id=3)
]) session.commit()
1.高级查询语句:条件、通配符、limit、排序、分组、连表、组合
#一、条件查询
sql=session.query(Emp).filter_by(ename=='1号') # filter_by只能传参数:什么等于什么
res=sql.all() #sql语句的执行结果 res=session.query(Emp).filter(Emp.id>0,Emp.ename == '1号').all() # filter内传的是表达式,逗号分隔,默认为and,
res=session.query(Emp).filter(Emp.id.between(1,3),Emp.ename == '1号').all()
res=session.query(Emp).filter(Emp.id.in_([1,3,99,101]),Emp.ename == '1号').all()
res=session.query(Emp).filter(~Emp.id.in_([1,3,99,101]),Emp.ename == '1号') # ~代表取反,转换成sql就是关键字not from sqlalchemy import and_,or_
res=session.query(Emp).filter(and_(Emp.id > 0,Emp.ename=='1号')).all() # and语句
res=session.query(Emp).filter(or_(Emp.id < 3,Emp.ename=='2号')).all() # or语句
res=session.query(Emp).filter( # and、or混合使用
or_(
Emp.dep_id == 3,
and_(Emp.id > 1,Emp.ename=='2号'),
Emp.ename != ''
)
).all() #二、通配符 like语句
res=session.query(Emp).filter(Emp.ename.like('%5_%')).all()
res=session.query(Emp).filter(~Emp.ename.like('%5_%')).all() #三、limit 从第0条到第5条,取前2条(猜的)
res=session.query(Emp)[0:5:2] #四、排序
res=session.query(Emp).order_by(Emp.dep_id.desc()).all()
res=session.query(Emp).order_by(Emp.dep_id.desc(),Emp.id.asc()).all() #五、分组
from sqlalchemy.sql import func res=session.query(Emp.dep_id).group_by(Emp.dep_id).all()
res=session.query(
func.max(Emp.dep_id),
func.min(Emp.dep_id),
func.sum(Emp.dep_id),
func.avg(Emp.dep_id),
func.count(Emp.dep_id),
).group_by(Emp.dep_id).all() res=session.query(
Emp.dep_id,
func.count(1),
).group_by(Emp.dep_id).having(func.count(1) > 2).all() #六、连表
# 笛卡尔积
res=session.query(Emp,Dep).all() #select * from emp,dep; #where条件
res=session.query(Emp,Dep).filter(Emp.dep_id==Dep.id).all()
# for row in res:
# emp_tb=row[0]
# dep_tb=row[1]
# print(emp_tb.id,emp_tb.ename,dep_tb.id,dep_tb.dname) #内连接
res=session.query(Emp).join(Dep)
#join默认为内连接,SQLAlchemy会自动帮我们通过foreign key字段去找关联关系
#但是上述查询的结果均为Emp表的字段,这样链表还有毛线意义,于是我们修改为
res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep).all() #左连接:isouter=True
res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep,isouter=True).all() #右连接:同左连接,只是把两个表的位置换一下 #七、组合
q1=session.query(Emp.id,Emp.ename).filter(Emp.id > 0,Emp.id < 5)
q2=session.query(Emp.id,Emp.ename).filter(
or_(
Emp.ename.like('%5%'),
Emp.ename.like('%9%'),
)
)
res1=q1.union(q2) # 组合+去重
res2=q1.union_all(q2) # 组合,不去重 print([i.ename for i in q1.all()]) #['1号', '2号', '3号', '4号']
print([i.ename for i in q2.all()]) #['1号', '4号']
print([i.ename for i in res1.all()]) #['1号', '2号', '3号', '4号']
print([i.ename for i in res2.all()]) #['1号', '2号', '3号', '4号', '4号', '1号']
2.子查询
注意:子查询的sql必须用括号包起来,尤其在形式三中需要注意这一点
#示例:查出id大于2的员工,当做子查询的表使用 #原生SQL:
# select * from (select * from emp where id > 2); #ORM:
res=session.query(
session.query(Emp).filter(Emp.id > 8).subquery()
).all()
形式一:子查询当做一张表来用,调用subquery()
#示例:#查出销售部门的员工姓名 #原生SQL:
# select ename from emp where dep_id in (select id from dep where dname='销售'); #ORM:
res=session.query(Emp.ename).filter(Emp.dep_id.in_(
session.query(Dep.id).filter_by(dname='销售'), #传的是参数
# session.query(Dep.id).filter(Dep.dname=='销售') #传的是表达式
)).all()
形式二:子查询当做in的范围用,调用in_
#示例:查询所有的员工姓名与部门名 #原生SQL:
# select ename as 员工姓名,(select dname from dep where id = emp.dep_id) as 部门名 from emp; #ORM:
sub_sql=session.query(Dep.dname).filter(Dep.id==Emp.dep_id) #SELECT dep.dname FROM dep, emp WHERE dep.id = emp.dep_id
sub_sql.as_scalar() #as_scalar的功能就是把上面的sub_sql加上了括号 res=session.query(Emp.ename,sub_sql.as_scalar()).all()
形式三:子查询当做select后的字段,调用as_scalar()
五、正向查询、反向查询
表结构
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import sessionmaker,relationship egine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() class Dep(Base):
__tablename__='dep'
id=Column(Integer,primary_key=True,autoincrement=True)
dname=Column(String(64),nullable=False,index=True) class Emp(Base):
__tablename__='emp'
id=Column(Integer,primary_key=True,autoincrement=True)
ename=Column(String(32),nullable=False,index=True)
dep_id=Column(Integer,ForeignKey('dep.id')) #在ForeignKey所在的类内添加relationship的字段,注意:
#1:Dep是类名
#2:depart字段不会再数据库表中生成字段
#3:depart用于Emp表查询Dep表(正向查询),而xxoo用于Dep表查询Emp表(反向查询),
depart=relationship('Dep',backref='xxoo') def init_db():
Base.metadata.create_all(egine) def drop_db():
Base.metadata.drop_all(egine) drop_db() # 先清空表
init_db() # 再创建表 Session=sessionmaker(bind=egine)
session=Session() # 准备数据
session.add_all([
Dep(dname='技术'),
Dep(dname='销售'),
Dep(dname='运营'),
Dep(dname='人事'),
]) session.add_all([
Emp(ename='1号',dep_id=1),
Emp(ename='2号',dep_id=1),
Emp(ename='3号',dep_id=1),
Emp(ename='4号',dep_id=2),
Emp(ename='5号',dep_id=3),
Emp(ename='6号',dep_id=4),
Emp(ename='7号',dep_id=2),
Emp(ename='8号',dep_id=4),
Emp(ename='9号',dep_id=3)
]) session.commit()
连表查询
# 示例:查询员工名与其部门名
res=session.query(Emp.ename,Dep.dname).join(Dep) #迭代器
for row in res:
print(row[0],row[1]) # 等同于print(row.ename,row.dname)
基于relationship的正查、反查
# SQLAlchemy的relationship在内部帮我们做好表的链接 # 查询员工名与其部门名(正向查)
res=session.query(Emp)
for row in res:
print(row.ename,row.id,row.depart.dname) #查询部门名以及该部门下的员工(反向查)
res=session.query(Dep)
for row in res:
# print(row.dname,row.xxoo)
print(row.dname,[r.ename for r in row.xxoo])
ORM框架SQLAlchemy学习的更多相关文章
- Python ORM框架SQLAlchemy学习笔记之数据添加和事务回滚介绍
1. 添加一个新对象 前面介绍了映射到实体表的映射类User,如果我们想将其持久化(Persist),那么就需要将这个由User类建立的对象实例添加到我们先前创建的Session会话实例中: 复制代码 ...
- python(十二)下:ORM框架SQLAlchemy使用学习
此出处:http://blog.csdn.net/fgf00/article/details/52949973 本节内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 ...
- SQL学习笔记八之ORM框架SQLAlchemy
阅读目录 一 介绍 二 创建表 三 增删改查 四 其他查询相关 五 正查.反查 一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进 ...
- ORM框架SQLAlchemy使用学习
参考源:http://blog.csdn.net/fgf00/article/details/52949973 一.ORM介绍 如果写程序用pymysql和程序交互,那是不是要写原生sql语句.如果进 ...
- ORM框架SQLAlchemy与权限管理系统的数据库设计
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用对象关系映射进行数据库操作,即:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果. 执行流 ...
- flask的orm框架(SQLAlchemy)-操作数据
# 原创,转载请留言联系 Flask-SQLAlchemy 实现增加数据 用 sqlalchemy 添加数据时,一定要注意,不仅仅要连接到数据表,并且你的创建表的类也必须写进来.而且字段和约束条件要吻 ...
- Android 数据库ORM框架GreenDao学习心得及使用总结<一>
转: http://www.it165.net/pro/html/201401/9026.html 最近在对开发项目的性能进行优化.由于项目里涉及了大量的缓存处理和数据库运用,需要对数据库进行频繁的读 ...
- 【转载】Android开源:数据库ORM框架GreenDao学习心得及使用总结
转载链接:http://www.it165.net/pro/html/201401/9026.html 最近在对开发项目的性能进行优化.由于项目里涉及了大量的缓存处理和数据库运用,需要对数据库进行频繁 ...
- MySQL之ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
随机推荐
- Selenium + Nightwatch 自动化测试环境搭建
首先要安装 Java 7 或更高 ,(http://www.oracle.com/technetwork/java/javase/downloads/index.html) 并且 java 命令可正常 ...
- Nouveau源代码分析(三):NVIDIA设备初始化之nouveau_drm_probe
Nouveau源代码分析(三) 向DRM注冊了Nouveau驱动之后,内核中的PCI模块就会扫描全部没有相应驱动的设备,然后和nouveau_drm_pci_table对比. 对于匹配的设备,PCI模 ...
- 实例讲解SVN分支和合并问题(转)
本节向大家简单描述一下SVN分支和合并方面的知识,在学习SVN的过程中SVN分支和合并时经常遇到的问题,在这里和大家分享一下,希望本文对大家有用. 关于主线同SVN分支合并的概念及如何使用的误区此问题 ...
- Spark技术内幕: Task向Executor提交的源代码解析
在上文<Spark技术内幕:Stage划分及提交源代码分析>中,我们分析了Stage的生成和提交.可是Stage的提交,仅仅是DAGScheduler完毕了对DAG的划分,生成了一个计算拓 ...
- 基于bootstrap+MySQL搭建动态网站
这个只是在上个练习项目中的后台管理项目加入了MySQL,数据不是写死的,而是从数据库中获取到的,获取到数据执行增删改查操作,没什么 计数难度,不做介绍
- websotrom 2016.2 license Server
license server” 输入:http://114.215.133.70:41017 仅供学习测试使用,支持正版.
- BZOJ 2818 Gcd 线性欧拉
题意:链接 方法:线性欧拉 解析: 首先列一下表达式 gcd(x,y)=z(z是素数而且x,y<=n). 然后我们能够得到什么呢? gcd(x/z,y/z)=1; 最好还是令y>=x 则能 ...
- 2.alert() 函数
①alert() 函数在 JavaScript 中并不常用,但它对于代码测试非常方便. <!DOCTYPE html><html><body> <h1> ...
- CSS3学习笔记(5)—页面遮罩效果
今天把页面遮罩的效果发一下,之前遮罩都是用JS实现的,忽然发现CSS3里面的box-shadow属性除了做立体阴影外,还可以做页面的遮罩. 下面来看一下完成的动态效果: 从上图可以看出,就是当鼠标悬浮 ...
- Java线程池技术以及实现
对于服务端而言,经常面对的是客户端传入的短小任务,需要服务端快速处理并返回结果.如果服务端每次接受一个客户端请求都创建一个线程然后处理请求返回数据,这在请求客户端数量少的阶段看起来是一个不错的选择,但 ...