Quantization Method
如上一篇Quantization所说,可以在编码端通过设置offset来调整量化后的值,从而趋向于期望的量化值,而且在逆量化公式可以看出offset值在逆量化的时候是不会用到的。
目前来说,确定offset的算法有三种:static offset、around offset、trellis offset。
Static Offset
H.264参考模型建议:当帧内预测时:$f = \frac{1}{3}\bigtriangleup$;当帧间预测时$f = \frac{1}{6}\bigtriangleup$。这种采用固定的比例作为量化的offset。
Around Offset
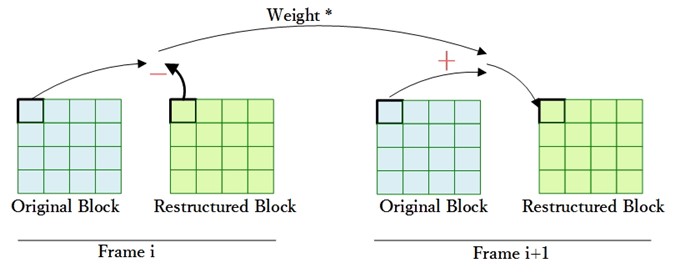
量化的时候加上Offset,目的是为了通过Offset的调整,使量化能趋向于得到最优结果。那么如何才是最优?当然是对量化后level进行反量化后,得到的数值与量化前的数值保持一致。当然这是不可能的,不过我们可以对第i次的量化结果,反馈到第i+1次量化计算中。通过这种自行反馈的方式,调整量化offset,使其趋向于最优的量化结果。
Around Offset会采用当前位置的上一次量化结果对这次的量化offset进行调整。
$ M_{i+1} = M_i + weight \times ((coeff_i – level_i << Qbits_i) >> (Qbits_i + 1))$
$ f_{i+1} = M_{i+1} << Qbits_{i+1}$
//Q_offsets.c
//fi+1 = Mi+1 << Qbitsi+1
static inline void update_q_offset4x4(LevelQuantParams **q_params, short *offsetList, int q_bits)
{
int i, j;
short *p_list = &offsetList[];
for (j = ; j < ; j++)
{
for (i = ; i < ; i++)
{
q_params[j][i].OffsetComp = (int) *p_list++ << q_bits;
}
}
} /*!
************************************************************************
* \brief
* Calculation of the quantization offset parameters at the frame level
*
* \par Input:
* none
*
* \par Output:
* none
************************************************************************
*/
void CalculateOffset4x4Param (VideoParameters *p_Vid)
{
QuantParameters *p_Quant = p_Vid->p_Quant;
int k;
int qp_per, qp;
int img_type = ((p_Vid->type == SI_SLICE) ? I_SLICE : (p_Vid->type == SP_SLICE ? P_SLICE : p_Vid->type)); int max_qp_scale = imax(p_Vid->bitdepth_luma_qp_scale, p_Vid->bitdepth_chroma_qp_scale);
int max_qp = + max_qp_scale;
InputParameters *p_Inp = p_Vid->p_Inp; p_Vid->AdaptRndWeight = p_Inp->AdaptRndWFactor [p_Vid->nal_reference_idc != ][img_type];
p_Vid->AdaptRndCrWeight = p_Inp->AdaptRndCrWFactor[p_Vid->nal_reference_idc != ][img_type]; if (img_type == I_SLICE )
{
for (qp = ; qp < max_qp + ; qp++)
{
k = p_Quant->qp_per_matrix [qp];
qp_per = Q_BITS + k - OffsetBits;
k = p_Inp->AdaptRoundingFixed ? : qp; // Intra4x4 luma
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Intra4x4 chroma u
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Intra4x4 chroma v
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
}
}
else if (img_type == B_SLICE)
{
for (qp = ; qp < max_qp + ; qp++)
{
k = p_Quant->qp_per_matrix [qp];
qp_per = Q_BITS + k - OffsetBits;
k = p_Inp->AdaptRoundingFixed ? : qp; // Inter4x4 luma
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][], qp_per);
// Intra4x4 luma
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Inter4x4 chroma u
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][], qp_per);
// Intra4x4 chroma u
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Inter4x4 chroma v
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][], qp_per);
// Intra4x4 chroma v
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
}
}
else
{
for (qp = ; qp < max_qp + ; qp++)
{
k = p_Quant->qp_per_matrix [qp];
qp_per = Q_BITS + k - OffsetBits;
k = p_Inp->AdaptRoundingFixed ? : qp; // Inter4x4 luma
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Intra4x4 luma
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Inter4x4 chroma u
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][], qp_per);
// Intra4x4 chroma u
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
// Inter4x4 chroma v
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][], qp_per);
// Intra4x4 chroma v
update_q_offset4x4(p_Quant->q_params_4x4[][][qp], p_Quant->OffsetList4x4[k][ ], qp_per);
}
}
} //Q_around.c
//Mi+1 = Mi + k
/*!
************************************************************************
* \brief
* update rounding offsets based on JVT-N011
************************************************************************
*/
void update_offset_params(Macroblock *currMB, int mode, byte luma_transform_size_8x8_flag)
{
VideoParameters *p_Vid = currMB->p_Vid;
InputParameters *p_Inp = currMB->p_Inp;
int is_inter = (mode != I4MB)&&(mode != I16MB) && (mode != I8MB);
int luma_pos = AdaptRndPos[(is_inter<<) + luma_transform_size_8x8_flag][p_Vid->type];
int i,j;
int qp = currMB->qp + p_Vid->bitdepth_luma_qp_scale;
int cur_qp = p_Inp->AdaptRoundingFixed ? : qp;
int temp = ;
QuantParameters *p_Quant = p_Vid->p_Quant;
int offsetRange = << (OffsetBits - );
int blk_mask = 0x03 + (luma_transform_size_8x8_flag<<);
int blk_shift = + luma_transform_size_8x8_flag;
short **offsetList = luma_transform_size_8x8_flag ? p_Quant->OffsetList8x8[cur_qp] : p_Quant->OffsetList4x4[cur_qp];
short *cur_offset_list = offsetList[luma_pos]; int **fAdjust = luma_transform_size_8x8_flag ? p_Vid->ARCofAdj8x8[][mode] : p_Vid->ARCofAdj4x4[][mode]; if (mode == IPCM) return; if( (p_Vid->active_sps->chroma_format_idc == YUV444) && (p_Inp->separate_colour_plane_flag != ) )
{
if( luma_transform_size_8x8_flag ) // 8x8
luma_pos += * p_Vid->colour_plane_id;
else // 4x4
luma_pos += p_Vid->colour_plane_id;
cur_offset_list = offsetList[luma_pos];
} for (j=; j < MB_BLOCK_SIZE; j++)
{
int j_pos = ((j & blk_mask)<<blk_shift);
for (i=; i < MB_BLOCK_SIZE; i++)
{
temp = j_pos + (i & blk_mask);
cur_offset_list[temp] = (short) iClip3(, offsetRange, cur_offset_list[temp] + (short) fAdjust[j][i]);
}
} if(p_Vid->P444_joined)
{
int **fAdjustCbCr;
int uv; for(uv = ; uv < ; uv++)
{
luma_pos = AdaptRndPos[(is_inter<<) + luma_transform_size_8x8_flag][p_Vid->type];
fAdjustCbCr = luma_transform_size_8x8_flag ? p_Vid->ARCofAdj8x8[uv + ][mode] : p_Vid->ARCofAdj4x4[uv + ][mode];
if(luma_transform_size_8x8_flag ) // 8x8
luma_pos += * (uv+);
else // 4x4
luma_pos += (uv+);
cur_offset_list = offsetList[luma_pos];
for (j=; j < MB_BLOCK_SIZE; j++)
{
int j_pos = ((j & blk_mask)<<blk_shift);
for (i=; i < MB_BLOCK_SIZE; i++)
{
temp = j_pos + (i & blk_mask);
cur_offset_list[temp] = (short) iClip3(, offsetRange, cur_offset_list[temp] + (short) fAdjustCbCr[j][i]);
}
}
}
} if ((p_Inp->AdaptRndChroma) && (p_Vid->yuv_format == YUV420 || p_Vid->yuv_format == YUV422 ))
{
int u_pos = AdaptRndCrPos[is_inter][p_Vid->type];
int v_pos = u_pos + ;
int k, jpos, uv = ; for (k = u_pos; k <= v_pos; k++)
{
int **fAdjustChroma = (luma_transform_size_8x8_flag && mode == P8x8 )? p_Vid->ARCofAdj4x4[uv][] : p_Vid->ARCofAdj4x4[uv][mode];
uv++;
cur_offset_list = p_Quant->OffsetList4x4[cur_qp][k]; for (j = ; j < p_Vid->mb_cr_size_y; j++)
{
jpos = ((j & 0x03)<<);
for (i = ; i < p_Vid->mb_cr_size_x; i++)
{
temp = jpos + (i & 0x03);
cur_offset_list[temp] = (short) iClip3(, offsetRange, cur_offset_list[temp] + (short) fAdjustChroma[j][i]);
}
}
}
}
} //Quant4x4_around.c
//k = weight * ((coeff - level<<Qbits) >> Qbits+1) /*!
************************************************************************
* \brief
* Quantization process for All coefficients for a 4x4 block
*
************************************************************************
*/
int quant_4x4_around(Macroblock *currMB, int **tblock, struct quant_methods *q_method)
{
VideoParameters *p_Vid = currMB->p_Vid;
QuantParameters *p_Quant = p_Vid->p_Quant;
Slice *currSlice = currMB->p_Slice;
Boolean is_cavlc = (Boolean) (currSlice->symbol_mode == CAVLC); int AdaptRndWeight = p_Vid->AdaptRndWeight; int block_x = q_method->block_x;
int qp = q_method->qp;
int* ACL = &q_method->ACLevel[];
int* ACR = &q_method->ACRun[];
LevelQuantParams **q_params_4x4 = q_method->q_params;
const byte (*pos_scan)[] = q_method->pos_scan;
const byte *c_cost = q_method->c_cost;
int *coeff_cost = q_method->coeff_cost; LevelQuantParams *q_params = NULL;
int **fadjust4x4 = q_method->fadjust; int i,j, coeff_ctr; int *m7;
int scaled_coeff; int level, run = ;
int nonzero = FALSE;
int qp_per = p_Quant->qp_per_matrix[qp];
int q_bits = Q_BITS + qp_per;
const byte *p_scan = &pos_scan[][]; int* padjust4x4; // Quantization
for (coeff_ctr = ; coeff_ctr < ; ++coeff_ctr)
{
i = *p_scan++; // horizontal position
j = *p_scan++; // vertical position padjust4x4 = &fadjust4x4[j][block_x + i];
m7 = &tblock[j][block_x + i]; if (*m7 != )
{
q_params = &q_params_4x4[j][i];
scaled_coeff = iabs (*m7) * q_params->ScaleComp;
level = (scaled_coeff + q_params->OffsetComp) >> q_bits; if (level != )
{
if (is_cavlc)
level = imin(level, CAVLC_LEVEL_LIMIT); *padjust4x4 = rshift_rnd_sf((AdaptRndWeight * (scaled_coeff - (level << q_bits))), q_bits + ); *coeff_cost += (level > ) ? MAX_VALUE : c_cost[run]; level = isignab(level, *m7);
*m7 = rshift_rnd_sf(((level * q_params->InvScaleComp) << qp_per), );
// inverse scale can be alternative performed as follows to ensure 16bit
// arithmetic is satisfied.
// *m7 = (qp_per<4) ? rshift_rnd_sf((level*q_params->InvScaleComp),4-qp_per) : (level*q_params->InvScaleComp)<<(qp_per-4);
*ACL++ = level;
*ACR++ = run;
// reset zero level counter
run = ;
nonzero = TRUE;
}
else
{
*padjust4x4 = ;
*m7 = ;
++run;
}
}
else
{
*padjust4x4 = ;
++run;
}
} *ACL = ; return nonzero;
}
trellis offset
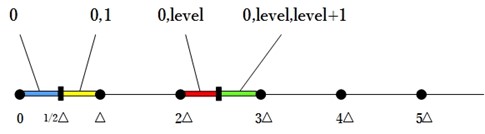
trellis offset其实用trellis quantization来描述更为准确,因为这种量化方式不会用到offset。Trellis就是采用Rdoq来得到最佳量化值,即取0、level还是level+1会达到最优的量化结果。由于不会用到offset,因此得到的level统一都是取下整,这样的话需要进行Rdo的候选level有三个:0、level、level+1。三个候选值还是稍微多了,可以采用以下方式进行筛选。
Rdoq当中包含Rdo这三个字母,这意味它依赖编码后的码流长度以及残差来选择最优结果,不过由于Rdoq处于编码途中,因此无法得到确切的编码后码流长度以及残差,因此只能通过预测值来,即上述候选值来进行计算。计算码流长度涉及到熵编码,而熵编码是以8x8或4x4为单位进行的,但是由于当前像素进行预测时,其后面的像素还没有进行预测,所以进行Rdoq时,当前像素之前的像素点采用的是预测后的level,而当前像素点之后的像素点采用level[num-1]的像素点。
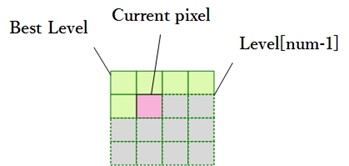
Rdoq实际上就是对于当前像素点所在的block进行Rdo:在该block上,当前像素采用的是0、level还是level+1才能得到最优的结果。
/*!
************************************************************************
* \brief
* Quantization process for All coefficients for a 4x4 block
*
************************************************************************
*/
int quant_4x4_trellis(Macroblock *currMB, int **tblock, struct quant_methods *q_method)
{
int block_x = q_method->block_x; int* ACL = &q_method->ACLevel[];
int* ACR = &q_method->ACRun[];
Slice *currSlice = currMB->p_Slice;
QuantParameters *p_Quant = currMB->p_Vid->p_Quant;
int qp = q_method->qp;
LevelQuantParams **q_params_4x4 = q_method->q_params;
const byte (*pos_scan)[] = q_method->pos_scan;
const byte *c_cost = q_method->c_cost;
int *coeff_cost = q_method->coeff_cost; Boolean is_cavlc = (Boolean) (currSlice->symbol_mode == CAVLC); int i,j, coeff_ctr; int *m7; int level, run = ;
int nonzero = FALSE;
int qp_per = p_Quant->qp_per_matrix[qp];
const byte *p_scan = &pos_scan[][]; int levelTrellis[]; /* rdoq_4x4
* To decide witch level to use
* 0:0 1:level 2:level+1 (lowerint == 0)
*/
currSlice->rdoq_4x4(currMB, tblock, q_method, levelTrellis); // Quantization
for (coeff_ctr = ; coeff_ctr < ; ++coeff_ctr)
{
i = *p_scan++; // horizontal position
j = *p_scan++; // vertical position m7 = &tblock[j][block_x + i]; if (*m7 != )
{
/*
scaled_coeff = iabs (*m7) * q_params_4x4[j][i].ScaleComp;
level = (scaled_coeff + q_params_4x4[j][i].OffsetComp) >> q_bits;
*/
level = levelTrellis[coeff_ctr]; if (level != )
{
if (is_cavlc)
level = imin(level, CAVLC_LEVEL_LIMIT); *coeff_cost += (level > ) ? MAX_VALUE : c_cost[run]; level = isignab(level, *m7);
*m7 = rshift_rnd_sf(((level * q_params_4x4[j][i].InvScaleComp) << qp_per), );
*ACL++ = level;
*ACR++ = run;
// reset zero level counter
run = ;
nonzero = TRUE;
}
else
{
*m7 = ;
++run;
}
}
else
{
++run;
}
} *ACL = ; return nonzero;
} /*!
************************************************************************
* \brief
* Rate distortion optimized Quantization process for
* all coefficients in a 4x4 block (CAVLC)
*
************************************************************************
*/
void rdoq_4x4_CAVLC(Macroblock *currMB, int **tblock, struct quant_methods *q_method, int levelTrellis[])
{
VideoParameters *p_Vid = currMB->p_Vid;
int block_x = q_method->block_x;
int block_y = q_method->block_y;
LevelQuantParams **q_params_4x4 = q_method->q_params;
const byte (*pos_scan)[] = q_method->pos_scan;
const byte *p_scan = &pos_scan[][];
int qp = q_method->qp;
QuantParameters *p_Quant = currMB->p_Vid->p_Quant;
int qp_per = p_Quant->qp_per_matrix[qp];
int qp_rem = p_Quant->qp_rem_matrix[qp]; levelDataStruct levelData[];
double lambda_md = p_Vid->lambda_rdoq[p_Vid->type][p_Vid->masterQP]; int type = LUMA_4x4;
int pos_x = block_x >> BLOCK_SHIFT;
int pos_y = block_y >> BLOCK_SHIFT;
int b8 = *(pos_y >> ) + (pos_x >> );
int b4 = *(pos_y & 0x01) + (pos_x & 0x01); init_trellis_data_4x4_CAVLC(currMB, tblock, block_x, qp_per, qp_rem, q_params_4x4, p_scan, &levelData[], type);
est_RunLevel_CAVLC(currMB, levelData, levelTrellis, LUMA, b8, b4, , lambda_md);
} /*!
****************************************************************************
* \brief
* Initialize levelData
****************************************************************************
*/
void init_trellis_data_4x4_CAVLC(Macroblock *currMB, int **tblock, int block_x, int qp_per, int qp_rem, LevelQuantParams **q_params,
const byte *p_scan, levelDataStruct *dataLevel, int type)
{
Slice *currSlice = currMB->p_Slice;
int i, j, coeff_ctr;
int *m7;
int end_coeff_ctr = ( ( type == LUMA_4x4 ) ? : );
int q_bits = Q_BITS + qp_per;
int q_offset = ( << (q_bits - ) );
int scaled_coeff, level, lowerInt, k;
double err, estErr; for (coeff_ctr = ; coeff_ctr < end_coeff_ctr; coeff_ctr++)
{
i = *p_scan++; // horizontal position
j = *p_scan++; // vertical position m7 = &tblock[j][block_x + i]; if (*m7 == )
{
dataLevel->levelDouble = ;
dataLevel->level[] = ;
dataLevel->noLevels = ;
err = 0.0;
dataLevel->errLevel[] = 0.0;
dataLevel->pre_level = ;
dataLevel->sign = ;
}
else
{
estErr = ((double) estErr4x4[qp_rem][j][i]) / currSlice->norm_factor_4x4; scaled_coeff = iabs(*m7) * q_params[j][i].ScaleComp;
dataLevel->levelDouble = scaled_coeff;
level = (scaled_coeff >> q_bits); lowerInt = ((scaled_coeff - (level << q_bits)) < q_offset )? : ; dataLevel->level[] = ;
if (level == && lowerInt == )
{
dataLevel->noLevels = ;
}
else if (level == && lowerInt == )
{
dataLevel->level[] = ;
dataLevel->noLevels = ;
}
else if (level > && lowerInt == )
{
dataLevel->level[] = level;
dataLevel->noLevels = ;
}
else
{
dataLevel->level[] = level;
dataLevel->level[] = level + ;
dataLevel->noLevels = ;
} for (k = ; k < dataLevel->noLevels; k++)
{
err = (double)(dataLevel->level[k] << q_bits) - (double)scaled_coeff;
dataLevel->errLevel[k] = (err * err * estErr);
} if(dataLevel->noLevels == )
dataLevel->pre_level = ;
else
dataLevel->pre_level = (iabs (*m7) * q_params[j][i].ScaleComp + q_params[j][i].OffsetComp) >> q_bits;
dataLevel->sign = isign(*m7);
}
dataLevel++;
}
} /*!
****************************************************************************
* \brief
* estimate run and level for CAVLC
****************************************************************************
*/
void est_RunLevel_CAVLC(Macroblock *currMB, levelDataStruct *levelData, int *levelTrellis, int block_type,
int b8, int b4, int coeff_num, double lambda)
{
int k, lastnonzero = -, coeff_ctr;
int level_to_enc[] = {}, sign_to_enc[] = {};
int cstat, bestcstat = ;
int nz_coeff=;
double lagr, lagrAcc = , minlagr = ;
VideoParameters *p_Vid = currMB->p_Vid; int subblock_x = ((b8 & 0x1) == ) ? (((b4 & 0x1) == ) ? : ) : (((b4 & 0x1) == ) ? : );
// horiz. position for coeff_count context
int subblock_y = (b8 < ) ? ((b4 < ) ? : ) :((b4 < ) ? : );
// vert. position for coeff_count context
int nnz;
levelDataStruct *dataLevel = &levelData[]; if (block_type != CHROMA_AC)
nnz = predict_nnz(currMB, LUMA, subblock_x, subblock_y);
else
nnz = predict_nnz_chroma(currMB, currMB->subblock_x >> , (currMB->subblock_y >> ) + ); for (coeff_ctr=;coeff_ctr < coeff_num;coeff_ctr++)
{
levelTrellis[coeff_ctr] = ; for(k=; k < dataLevel->noLevels; k++)
{
dataLevel->errLevel[k] /= ;
} lagrAcc += dataLevel->errLevel[imax(, dataLevel->noLevels - )]; level_to_enc[coeff_ctr] = dataLevel->pre_level;
sign_to_enc[coeff_ctr] = dataLevel->sign; if(dataLevel->noLevels > )
{
dataLevel->coeff_ctr = coeff_ctr;
lastnonzero = coeff_ctr;
}
else
dataLevel->coeff_ctr = -;
dataLevel++;
} if(lastnonzero != -)
{
//sort the coefficients based on their absolute value
qsort(levelData, lastnonzero + , sizeof(levelDataStruct), cmp);
dataLevel = &levelData[lastnonzero]; for(coeff_ctr = lastnonzero; coeff_ctr >= ; coeff_ctr--) // go over all coeff
{
if(dataLevel->noLevels == )
{
dataLevel--;
continue;
} lagrAcc -= dataLevel->errLevel[dataLevel->noLevels-];
for(cstat=; cstat<dataLevel->noLevels; cstat++) // go over all states of cur coeff k
{
level_to_enc[dataLevel->coeff_ctr] = dataLevel->level[cstat];
lagr = lagrAcc + dataLevel->errLevel[cstat];
lagr += lambda * est_CAVLC_bits( p_Vid, level_to_enc, sign_to_enc, nnz, block_type);
if(cstat== || lagr<minlagr)
{
minlagr = lagr;
bestcstat = cstat;
}
} lagrAcc += dataLevel->errLevel[bestcstat];
level_to_enc[dataLevel->coeff_ctr] = dataLevel->level[bestcstat];
dataLevel--;
} for(coeff_ctr = ; coeff_ctr <= lastnonzero; coeff_ctr++)
{
levelTrellis[coeff_ctr] = level_to_enc[coeff_ctr];
if (level_to_enc[coeff_ctr] != )
nz_coeff++;
}
} p_Vid->nz_coeff [p_Vid->current_mb_nr ][subblock_x][subblock_y] = nz_coeff;
} /*!
************************************************************************
* \brief
* estimate CAVLC bits
************************************************************************
*/
int est_CAVLC_bits (VideoParameters *p_Vid, int level_to_enc[], int sign_to_enc[], int nnz, int block_type)
{
int no_bits = ;
SyntaxElement se; int coeff_ctr, scan_pos = ;
int k, level = , run = -, vlcnum;
int numcoeff = , lastcoeff = , numtrailingones = ;
int numones = , totzeros = , zerosleft, numcoef;
int numcoeff_vlc;
int level_two_or_higher;
int max_coeff_num = , cdc = (block_type == CHROMA_DC ? : );
int yuv = p_Vid->yuv_format - ;
static const int incVlc[] = {, , , , , , }; // maximum vlc = 6 int pLevel[] = {};
int pRun[] = {}; static const int Token_lentab[][][] =
{
{
{ , , , ,,,,,,,,,,,,,},
{ , , , , ,,,,,,,,,,,,},
{ , , , , , ,,,,,,,,,,,},
{ , , , , , , , ,,,,,,,,,}
},
{
{ , , , , , , ,,,,,,,,,,},
{ , , , , , , , ,,,,,,,,,},
{ , , , , , , , ,,,,,,,,,},
{ , , , , , , , , , ,,,,,,,}
},
{
{ , , , , , , , , , , , , ,,,,},
{ , , , , , , , , , , , , , ,,,},
{ , , , , , , , , , , , , , ,,,},
{ , , , , , , , , , , , , , ,,,}
}
}; static const int Totalzeros_lentab[TOTRUN_NUM][] =
{
{ ,,,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,},
{ ,,,,,,,,,,,},
{ ,,,,,,,,,,},
{ ,,,,,,,,,},
{ ,,,,,,,,},
{ ,,,,,,,},
{ ,,,,,,},
{ ,,,,,},
{ ,,,,},
{ ,,,},
{ ,,},
{ ,},
};
static const int Run_lentab[TOTRUN_NUM][] =
{
{,},
{,,},
{,,,},
{,,,,},
{,,,,,},
{,,,,,,},
{,,,,,,,,,,,,,,},
};
static const int Token_lentab_cdc[][][] =
{
//YUV420
{{ , , , , , , , , , , , , , , , , },
{ , , , , , , , , , , , , , , , , },
{ , , , , , , , , , , , , , , , , },
{ , , , , , , , , , , , , , , , , }},
//YUV422
{{ , , , , ,,,,, , , , , , , , },
{ , , , , ,,,,, , , , , , , , },
{ , , , , , ,,,, , , , , , , , },
{ , , , , , , ,,, , , , , , , , }},
//YUV444
{{ , , , ,,,,,,,,,,,,,},
{ , , , , ,,,,,,,,,,,,},
{ , , , , , ,,,,,,,,,,,},
{ , , , , , , , ,,,,,,,,,}}
};
static const int Totalzeros_lentab_cdc[][TOTRUN_NUM][] =
{
//YUV420
{{ ,,,},
{ ,,},
{ ,}},
//YUV422
{{ ,,,,,,,},
{ ,,,,,,},
{ ,,,,,},
{ ,,,,},
{ ,,,},
{ ,,},
{ ,}},
//YUV444
{{ ,,,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,,},
{ ,,,,,,,,,,,,},
{ ,,,,,,,,,,,},
{ ,,,,,,,,,,},
{ ,,,,,,,,,},
{ ,,,,,,,,},
{ ,,,,,,,},
{ ,,,,,,},
{ ,,,,,},
{ ,,,,},
{ ,,,},
{ ,,},
{ ,}}
}; max_coeff_num = ( (block_type == CHROMA_DC) ? p_Vid->num_cdc_coeff :
( (block_type == LUMA_INTRA16x16AC || block_type == CB_INTRA16x16AC || block_type == CR_INTRA16x16AC || block_type == CHROMA_AC) ? : ) ); //convert zigzag scan to (run, level) pairs
for (coeff_ctr = ; coeff_ctr < max_coeff_num; coeff_ctr++)
{
run++;
level = level_to_enc[coeff_ctr];
if (level != )
{
pLevel[scan_pos] = isignab(level, sign_to_enc[coeff_ctr]);
pRun [scan_pos] = run;
++scan_pos;
run = -; // reset zero level counter
}
} level = ;
for(k = ; (k < max_coeff_num) && level != ; k++)
{
level = pLevel[k]; // level
run = pRun[k]; // run if (level)
{
totzeros += run; // lets add run always (even if zero) to avoid conditional
if (iabs(level) == )
{
numones ++;
numtrailingones ++;
numtrailingones = imin(numtrailingones, ); // clip to 3
}
else
{
numtrailingones = ;
}
numcoeff ++;
lastcoeff = k;
}
} if (!cdc)
{
numcoeff_vlc = (nnz < ) ? : ((nnz < ) ? : ((nnz < ) ? : ));
}
else
{
// chroma DC (has its own VLC)
// numcoeff_vlc not relevant
numcoeff_vlc = ;
} se.value1 = numcoeff;
se.value2 = numtrailingones;
se.len = numcoeff_vlc; /* use len to pass vlcnum */ if (!cdc)
{
if (se.len == )
no_bits += ; // 4 + 2 bit FLC
else
no_bits += Token_lentab[se.len][se.value2][se.value1];
}
else
no_bits += Token_lentab_cdc[yuv][se.value2][se.value1]; if (!numcoeff)
return no_bits;
else
{
if (numtrailingones)
no_bits += numtrailingones; // encode levels
level_two_or_higher = (numcoeff > && numtrailingones == ) ? : ; vlcnum = (numcoeff > && numtrailingones < ) ? : ; for (k = lastcoeff - numtrailingones; k >= ; k--)
{
level = pLevel[k]; // level se.value1 = level; if (level_two_or_higher)
{
level_two_or_higher = ;
if (se.value1 > )
se.value1 --;
else
se.value1 ++;
} // encode level
if (vlcnum == )
estSyntaxElement_Level_VLC1(&se);
else
estSyntaxElement_Level_VLCN(&se, vlcnum); // update VLC table
if (iabs(level) > incVlc[vlcnum])
vlcnum++; if ((k == lastcoeff - numtrailingones) && iabs(level) > )
vlcnum = ; no_bits += se.len;
} // encode total zeroes
if (numcoeff < max_coeff_num)
{
se.value1 = totzeros; vlcnum = numcoeff-; se.len = vlcnum; if (!cdc)
no_bits += Totalzeros_lentab[se.len][se.value1];
else
no_bits += Totalzeros_lentab_cdc[yuv][se.len][se.value1];
} // encode run before each coefficient
zerosleft = totzeros;
numcoef = numcoeff;
for (k = lastcoeff; k >= ; k--)
{
run = pRun[k]; // run se.value1 = run; // for last coeff, run is remaining totzeros
// when zerosleft is zero, remaining coeffs have 0 run
if ((!zerosleft) || (numcoeff <= ))
break; if (numcoef > && zerosleft)
{
vlcnum = imin(zerosleft - , RUNBEFORE_NUM_M1);
se.len = vlcnum;
no_bits += Run_lentab[se.len][se.value1];
zerosleft -= run;
numcoef --;
}
}
} return no_bits;
}
Quantization Method的更多相关文章
- 哈希学习(2)—— Hashing图像检索资源
CVPR14 图像检索papers——图像检索 1. Triangulation embedding and democratic aggregation for imagesearch (Oral ...
- Hashing图像检索源码及数据库总结
下面的这份哈希算法小结来源于本周的周报,原本并没有打算要贴出来的,不过,考虑到这些资源属于关注利用哈希算法进行大规模图像搜索的各位看官应该很有用,所以好东西本小子就不私藏了.本资源汇总最主要的收录原则 ...
- 论文翻译——Character-level Convolutional Networks for Text Classification
论文地址 Abstract Open-text semantic parsers are designed to interpret any statement in natural language ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- Soft-to-Hard Vector Quantization for End-to-End Learning Compressible Representations
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract: 我们提出了一种新的方法,通过端到端的训练策略来学习深度架构中的可压缩表征.我们的方法是基于量化和熵的软(连续)松弛,我 ...
- jsp中出现onclick函数提示Cannot return from outside a function or method
在使用Myeclipse10部署完项目后,原先不出错的项目,会有红色的叉叉,JSP页面会提示onclick函数错误 Cannot return from outside a function or m ...
- Apply Newton Method to Find Extrema in OPEN CASCADE
Apply Newton Method to Find Extrema in OPEN CASCADE eryar@163.com Abstract. In calculus, Newton’s me ...
- 设计模式(九): 从醋溜土豆丝和清炒苦瓜中来学习"模板方法模式"(Template Method Pattern)
今天是五.四青年节,祝大家节日快乐.看着今天这标题就有食欲,夏天到了,醋溜土豆丝和清炒苦瓜适合夏天吃,好吃不上火.这两道菜大部分人都应该吃过,特别是醋溜土豆丝,作为“鲁菜”的代表作之一更是为大众所熟知 ...
随机推荐
- 查看Linux声卡基本信息[转载]
查看系统版本~$ uname -aLinux laptop 2.6.27-7-generic #1 SMP Tue Nov 4 19:33:20 UTC 2008 i686 GNU/Linux 查看型 ...
- git使用介绍
Git简单介绍 参考网址: git使用简介 这个教程推荐使用:git教程 git和svn的差异 git和svn的最大差异在于git是分布式的管理方式而svn是集中式的管理方式.如果不习惯用代码管理工具 ...
- Swift: 下标(Subscripts)
类.结构体.枚举都可以定义下标(subscript),下标是访问集合.列表.序列的元素的快捷方式. 在Swift中可以为类型定义下标,而且不限于一维. 语法 下标定义的方法:跟实例方法的语法类似,su ...
- Java的容器小结
1. 各个类与接口的关系:
- Android进阶笔记02:Android 网络请求库的比较及实战(二)
一.Volley 既然在android2.2之后不建议使用HttpClient,那么有没有一个库是android2.2及以下版本使用HttpClient,而android2.3及以上版本 ...
- Android系统移植与驱动开发——第七章——LED驱动
LED驱动的实现原理 编写LED驱动: 测试LED驱动之前需要用USB数据线连接开发板,然后打开电源,成功启动之后,执行build.sh脚本文件编译和安装LED驱动,顺利则会自动连接 如果有多个设备文 ...
- MediaCodec文档翻译
MediaCodec|文档翻译 classoverView mediacodec类可以用来调用系统底层的编码/解码软件. mediacodec一般是这么用的: MediaCodec codec = M ...
- angular.bind
angular.bind :Returns a function which calls function fn bound to self (self becomes the this for fn ...
- java中判断两个字符串是否相等的问题
我最近刚学java,今天编程的时候就遇到一个棘手的问题,就是关于判断两个字符串是否相等的问题.在编程中,通常比较两个字符串是否相同的表达式是“==”,但在java中不能这么写.在java中,用的是eq ...
- tinkphp URL重写,支持伪静态
通常的URL里面含有index.php,为了达到更好的SEO效果可能需要去掉URL里面的index.php ,通过URL重写的方式可以达到这种效果,通常需要服务器开启URL_REWRITE模块才能支持 ...