Sql Server 优化----SQL语句的执行方式与锁以及阻塞的关系
阻塞原因之一是不同的Session在访问同一张表的时候因为不兼容锁的原因造成的, 当前执行的SQL语句是否被阻塞(或者死锁),不仅跟当前表上的已有的锁有关,也会跟当前执行的SQL语句的执行方式有关 简单来说,对于表的访问方式,SQL语句的执行无非是表扫描,索引扫描,(聚集索引或者非聚集索引)索引查找等等 如果SQL语句的执行方式不当或者没有合理的索引,会造成没必要的阻塞,如果逻辑控制不当,甚至造成更严重的问题,造成数据逻辑的错误
建个测试表,下面测试演示一下

create table testIndexAndLock
(
id int identity(1,1),
col2 varchar(50)
)
GO insert into testIndexAndLock values (NEWID())
GO
很常见的业务就是,当前Session中开启了事物,执行更新或者删除某一行数据,然后再进行一系列其他的操作,当前事物提交之前,该排它锁一致保持,直到事物提交
比如下面截图:
第一个Session中利用事物和排他性操作锁定一行数据,,进行业务逻辑处理,按道理来说:目的仅仅是锁定当前行的数据(id = 6666),进行排他性操作,并没有锁定其的数据行
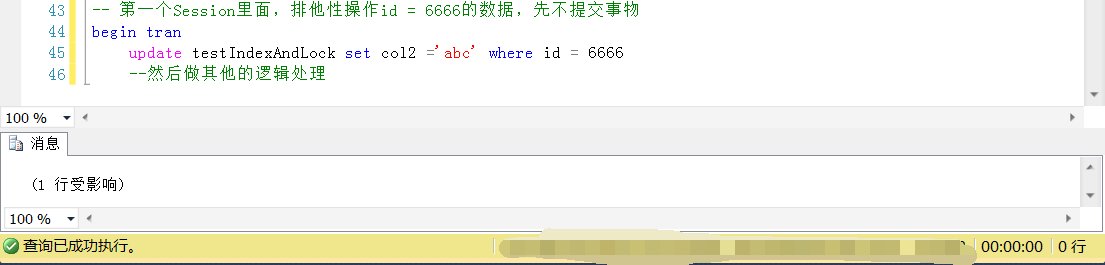
然后再第二个Session中,查询其他的无关的Id,按道理,上面一个Session只是锁定了id = 6666的行,怎么当前Session查询Id = 7777的行的时候会被阻塞呢?

这里就是上面说的对当前表的访问方式了,因为当前查询的表上没有任何索引,在查询id = 7777的时候,虽然id = 7777的行上没有任何锁,为什么查询还是被阻塞? 这里在执行查询id = 7777的时候,用的是全表扫描的方式执行的,此时遇到Id = 6666的这行数据的时候,因为这行数据上有排它锁,当前Session被阻塞 可以简单理解为当前Session会逐行扫描表中的数据行,在扫描的过程中,不管是表也好,数据行也好,如果遇到兼容的锁,可以正常访问, 如果遇到不兼容的锁,比如这里的查询是共享锁(s锁),遇到第一个Session中的id = 6666的这行数据的时候,发现上面是排它锁, 此时,当前Session要对该行加的锁(共享锁)与该行上的排它锁(x锁)不兼容,就只能等待,知道id = 6666这行数据上的排它锁释放或者变化与当前请求的共享锁兼容的锁,才能执行 如果id = 6666上面的排它锁一直没有释放或者变化为兼容共享锁的锁类型,当前Session就一直等待 表现为当前Session被阻塞 这种问题解决办法也很简单,类似现象如果要不被阻塞,要么等到第一个Session的排它锁释放,要么就换一种查询的方式 尝试在表的Id列上建立一个索引,当然聚集索引也可以,目的是防止查询的时候以全表扫描的方式进行
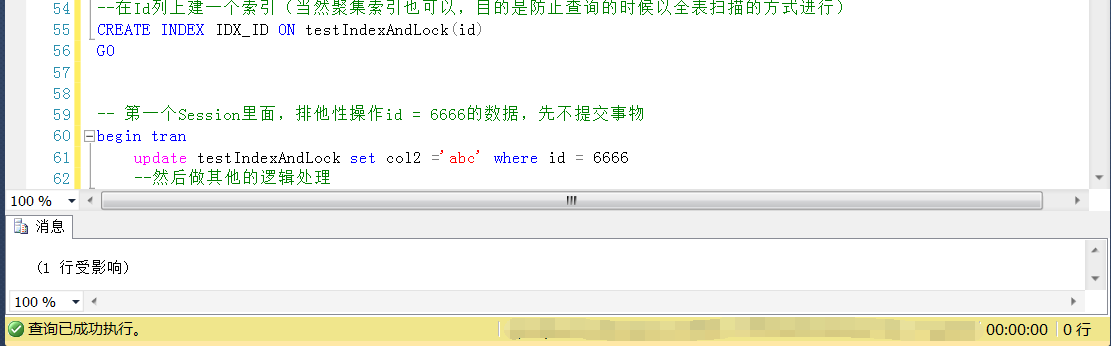
在第二个Session中执行上面的查询,查询Id = 7777的数据行,可以发现这个查询可以顺利完成
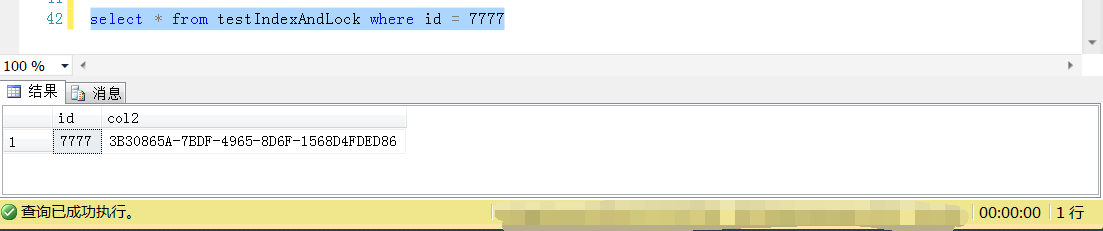
这个就是通过索引改变查询的执行计划,避免全表扫描的时候遇到任何一行数据上有排它锁造成阻塞的情况。 这里说的索引,并不仅仅是为了提高效率,更重要的是改变了查询的执行方式,避免遇到表上有排他性锁的锁在成阻塞的情况。
索引的作用不仅仅是提高查询效率,更重要的是避免全表扫描的过程中遇到排它锁被阻塞的情况,对减少阻塞有一定的帮助作用。
Sql Server 优化----SQL语句的执行方式与锁以及阻塞的关系的更多相关文章
- Sql Server 优化 SQL 查询:如何写出高性能SQL语句
1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个 10万条记录的表中查1条 ...
- SQL Server查看Sql语句执行的耗时和IO消耗
原文:SQL Server查看Sql语句执行的耗时和IO消耗 在做系统过程中,经常需要针对某些场景进行性能优化,那么如何判定性能优化的效果呢?肯定需要知道优化之前Sql语句的耗时和优化之后Sql语句的 ...
- Sql server的Merge语句,源表中如果有重复数据会导致执行报错
用过sql server的Merge语句的开发人员都应该很清楚Merge用来做表数据的插入/更新是非常方便的,但是其中有一个问题值得关注,那就是Merge语句中的源表中不能出现重复的数据,我们举例来说 ...
- Linux下用freetds执行SQL Server的sql语句和存储过程
Linux下用freetds执行SQL Server的sql语句和存储过程 http://www.linuxidc.com/Linux/2012-06/61617.htm freetds相关 http ...
- 深入SQL Server优化【推荐】
深入sql server优化,MSSQL优化,T-SQL优化,查询优化 十步优化SQL Server 中的数据访问故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性 ...
- SQL Server优化的方法
SQL Server优化的方法<一> 查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了 ...
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- 【SQL Server 优化性能的几个方面】(转)
转自:http://blog.csdn.net/feixianxxx/article/details/5524819 SQL Server 优化性能的几个方面 (一).数据库的设计 可以参看最 ...
- SQL Server优化技巧——如何避免查询条件OR引起的性能问题
之前写过一篇博客"SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析",里面介绍了OR可能会引起全表扫描或索引扫描的各种案例,以及如何优化查询条件中含有OR的SQL语句的 ...
随机推荐
- InnoDB undo log物理结构的初始化
水平有限,如果有误请指出.一直以来未对Innodb 的undo进行好好的学习,最近刚好有点时间准备学习一下,通过阿里内核月报和自己看代码的综合总结一下.本文环境: 代码版本 percona 5.7.2 ...
- 【剑指Offer】57、二叉树的下一个结点
题目描述: 给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回.注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针. 解题思路: 本题解决起来并不是很困难 ...
- 3..jquery的ajax获取form表单数据
jq是对dom进行的再次封装.是一个js库,极大简化了js使用 jquery库在js文件中,包含了所有jquery函数,引用:<script src="jquery-1.11.1.mi ...
- svn_精简版【极速安装】
1.进入官网下载:http://tortoisesvn.net/ 2.进行安装. 3.官方下载汉化包 [32 位,64位] 4.安装完汉化包后,右键->Settings 5.选择语言包,确定就o ...
- js实现cookie有效期至当次日凌晨
实际开发中有要求用户一些行为每天一次,次日开始重新回复功能,一般前端都是通过cookie来记住用户的操作,然后进行判断当日是否还有机会,这时候需要给存储的cookie值一个有效期,让次日自动失效,重新 ...
- 0808关于RDS如何恢复到本地教程
转自http://www.cnblogs.com/ilanni/archive/2016/02/25/5218129.html 公司目前使用的数据库是阿里云的RDS,目前RDS的版本为mysql5.6 ...
- VMware 12安装CentOS 6.9时出现:The centos disc was not found in any of your drives.Please insert the centos disc and press OK to retry
错误: The centos disc was not found in any of your drives.Please insert the centos disc and press OK t ...
- 当使用servlet输出json时,浏览器端jquery的ajax遇到parse error的问题
在使用jquery的ajax进行请求发送并由服务端的servlet返回json格式的数据内容时,假设输出内容没有正确设置,会遇到client浏览器报告parse error的问题.这个问题的解决仅仅须 ...
- <图形图像,动画,多媒体> 读书笔记 --- 录制与编辑视频
使用UIImagePickerController 进行录制 #import "ViewController.h" #import <MobileCoreServices/M ...
- 我想要得那块牌—记烟台大学第一届"ACM讲堂"
2014年5月23日.烟台大学ACM实验室举办了第一届"ACM讲堂",演讲的主题是"我想要得那块牌",大二和大三的參赛队员以及三位指导老师都进行了演讲. 晚上七 ...