mysql数据库同步系统otter部署实践(中国与欧洲同步)
otter的介绍就不说了, 自己去看官网https://github.com/alibaba/otter/wiki
本系统中, 中国的服务器部署在阿里云上, 欧洲服务器部署在亚马逊上, 由于阿里云的网络不支持外网回环访问(即在本机上向本机的外网地址发送数据), 所以需要将node与manager部署在不同的主机上。如果只是在虚拟机中调试, 很多服务都可以放在一台主机中。
1. 阿里云服务器
1. mysql服务, 外网ip 120.x.x.1, 内网ip 10.x.x.1
2. manager服务, 本系统与mysql安装在同一台服务器上
3. node服务, 外网ip 120.x.x.2, 内网ip 10.x.x.2
4. zookeeper服务, 外网ip 120.x.x.3, 内网ip 10.x.x.3
2. 亚马逊服务器
1. mysql服务, 外网ip 59.x.x.1, 内网ip 172.x.x.1
2. node服务,外网ip 59.x.x.2, 内网ip 172.x.x.2
3. zookeeper服务, 外网ip 59.x.x.2, 内网ip 172.x.x.3
3. 下载otter和zookeeper
已经编译好的压缩包
https://github.com/alibaba/otter/releases
下载manager系统表
下载ddl同步策略表
下载zookeeper
http://www.apache.org/dyn/closer.cgi/zookeeper/
4. 配置阿里云mysql
修改两台服务器的mysql配置, /etc/mysql/my.cnf (5.7版本的mysql的配置文件应该是/etc/mysql/mysql.conf.d/mysqld.cnf)
注意: server-id需要和manager上配置的node的id一致
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci #设置mysql的字符集
#bind-address = 127.0.0.1 这一行要注释掉
server-id = 1
log_bin = /data/lib/mysql/mysql-bin.log
expire_logs_days = 5
max_binlog_size = 200M
binlog_do_db = xxx
binlog_format = ROW
重启mysql
5. 配置亚马逊上的mysql
只是server-id不一样
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci #设置mysql的字符集
#bind-address = 127.0.0.1 这一行要注释掉
server-id = 2
log_bin = /data/lib/mysql/mysql-bin.log
expire_logs_days = 5
max_binlog_size = 200M
binlog_do_db = xxx
binlog_format = ROW
重启mysql
6. 导入系统表和otter用户
注意修改密码
mysql>source otter-manager-schema.sql
mysql>source otter-system-ddl-mysql.sql
mysql>CREATE USER canal IDENTIFIED BY 'canal;
mysql>GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql>GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%';
mysql>FLUSH PRIVILEGES;7. 安装aria2和zookeeper
在需要运行node服务器上安装aria2, 它是一个下载工具, otter使用它下载了什么文件, 我也不知道
apt-get install aria2在分别在阿里云和亚马逊的两台服务器上安装zookeeper和运行zookeeper, 这个过程很简单
cd zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
cd ../bin/
./zkServer.sh start8. 配置manager
cd manager/conf/
vim otter.properties## otter manager domain name
otter.domainName = 120.x.x.1 #修改为当前服务器的公网地址
## otter manager http port
otter.port = 8080
## jetty web config xml
otter.jetty = jetty.xml
## otter manager database config
otter.database.driver.class.name = com.mysql.jdbc.Driver
otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter #由于mysql和manager在同一个服务器
otter.database.driver.username = canal
otter.database.driver.password = canal #需要修改为实际的密码
## otter communication port
otter.communication.manager.port = 1099
## otter communication pool size
otter.communication.pool.size = 10
## default zookeeper address
otter.zookeeper.cluster.default = 120.x.x.3:2181 #修改为阿里云上安装的zookeeper
## default zookeeper sesstion timeout = 60s
...
9. 启动manager
cd manager/bin
./startup.sh在浏览器中打开manager主页
http://120.x.x.1:8080/
右击右上角的登录按钮, 用户名为admin, 密码也为admin (点击系统管理->权限管理, 然后修改密码)
9.1添加zookeeper管理
点击机器管理->zookeeper管理,
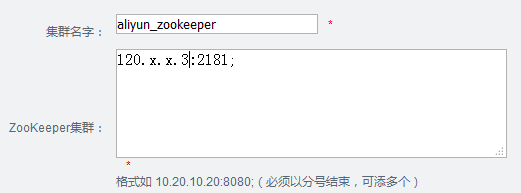
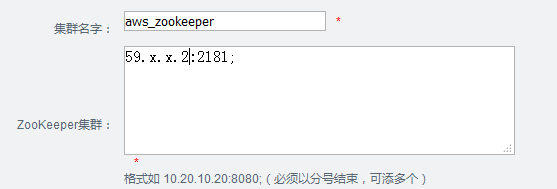
9.2 添加Node管理
点击 机器管理->Node管理
注意: 添加顺序不能改变, manager会为node分配一个id, mysql的server-id要与node id一致
机器名称 : aliyun_node
机器ip: 10.x.x.2
机器端口 : 2088
外部ip: 120.x.x.2
启用外部IP: 是
zookeeper集群: aliyun_zookeeper
保存
再添加一次
机器名称 : aws_node
机器ip: 172.x.x.2
机器端口 : 2088
外部ip: 59.x.x.2
启用外部IP: 是
zookeeper集群: aliyun_zookeeper
保存
9.3 添加数据源
配置管理 -> 数据源配置
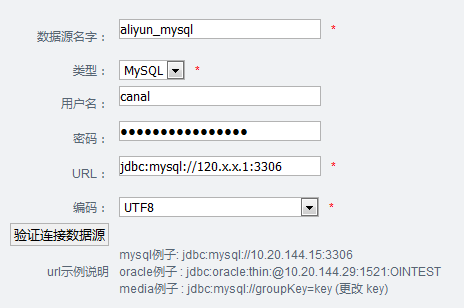
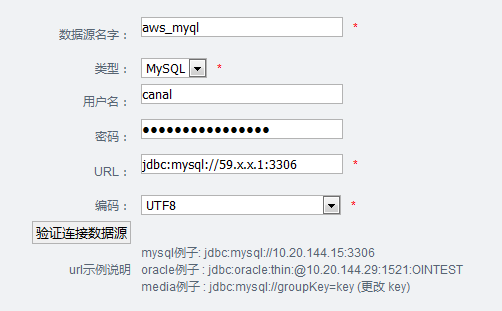
9.4 添加数据表
schema name: xxx
table name: test
数据源: aliyun_mysql
保存
schema name: xxx
table name: test
数据源: aws_mysql
保存
9.5 添加canal配置
canal名称: aliyun_canal
zookeeper集群: aliyun_zookeeper
数据库地址: 120.x.x.1:3306;
数据库账号: canal
数据库密码: canal
保存
canal名称: aws_canal
zookeeper集群: aws_zookeeper
数据库地址: 59.x.x.1:3306;
数据库账号: canal
数据库密码: canal
保存
9.6添加channel
同步管理 -> 添加
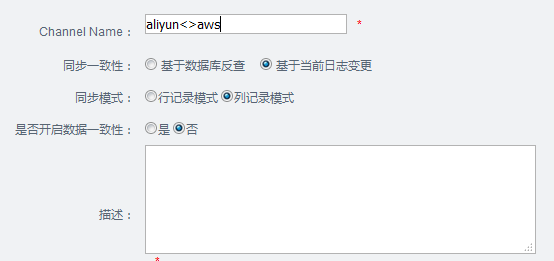
9.7添加pipeline
同步管理 -> aliyun<>aws -> 添加
pipeline名字: aliyun->aws
select机器: aliyun_node
load机器: aws_node
主站点: 是
canal名字: aliyun_canal
高级设置: 勾
支持ddl同步: 是
保存
pipeline名字: aws->aliyun
select机器: aws_node
load机器: aliyun_node
主站点: 否
canal名字: aliyun_canal
高级设置: 勾
支持ddl同步: 否
保存
10. 配置/启动node
1. 配置aliyun上的node
cd node/conf/
echo 1 > nid
vim otter.properties
...
## otter arbitrate & node connect manager config
otter.manager.address = 120.x.x.1:1099 #填manager的外网地址
1. 配置aws上的node
cd node/conf/
echo 2 > nid
vim otter.properties
...
## otter arbitrate & node connect manager config
otter.manager.address = 120.x.x.1:1099 #填manager的外网地址
然后执行startup.sh
注意: 这个脚本默认配置了很大的内容, 如果内存不够, 可以修改这个文件
11. 启动
打开 机器管理 -> Node管理, 显示两个node状态为运行
打开 同步管理, 点击启用
https://my.oschina.net/u/2343729/blog/826050
mysql数据库同步系统otter部署实践(中国与欧洲同步)的更多相关文章
- 阿里巴巴开源项目:分布式数据库同步系统otter(解决中美异地机房) - agapple - ITeye技术网站
阿里巴巴开源项目:分布式数据库同步系统otter(解决中美异地机房) - agapple - ITeye技术网站 阿里巴巴开源项目:分布式数据库同步系统otter(解决中美异地机房)
- wamp集成环境下mysql数据库的分开部署和远程访问
今天折腾了一天一个小问题,就是明明正确的php代码在访问数据库的时候总是提示DB ERROR.后来才发现是填写数据库名的时候,写成了该数据库的ip地址(其实也是本机ip但是本机还是不能访问),而不是l ...
- 阿里云(ecs服务器)使用3-安装mysql数据库以及远程部署
1.安装 1.下载rpm包,下载地址 http://dev.mysql.com/downloads/mysql/,选择Linux-Generic版本 .新建 /usr/local/mysql 文件夹, ...
- mysql数据库索引优化与实践(一)
前言 mysql数据库是现在应用最广泛的数据库系统.与数据库打交道是每个Java程序员日常工作之一,索引优化是必备的技能之一. 为什么要了解索引 真实案例 案例一:大学有段时间学习爬虫,爬取了知乎30 ...
- 重新学习MySQL数据库12:从实践sql语句优化开始
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/a724888/article/details/79394168 本文不堆叠网上海量的sql优化技巧或 ...
- Mysql学习总结(20)——MySQL数据库优化的最佳实践
1)谨慎而有效地使用索引 选择合理的索引(前缀性及可选性).删除没有用的索引. 2)使用规范化,但不要使用过头 规范化(至少是第三范式)是一个易于理解且标准的方法.然而,在有些情况下,你可能希望违反这 ...
- Mysql数据库调优和性能优化的21条最佳实践
Mysql数据库调优和性能优化的21条最佳实践 1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开 ...
- Java开发最佳实践(二) ——《Java开发手册》之"异常处理、MySQL 数据库"
二.异常日志 (一) 异常处理 (二) 日志规约 三.单元测试 四.安全规约 五.MySQL数据库 (一) 建表规约 (二) 索引规约 (三) SQL语句 (四) ORM映射 六.工程结构 七.设计规 ...
- Linux实战教学笔记29:MySQL数据库企业级应用实践
第二十九节 MySQL数据库企业级应用实践 一,概述 1.1 MySQL介绍 MySQL属于传统关系型数据库产品,它开放式的架构使得用户选择性很强,同时社区开发与维护人数众多.其功能稳定,性能卓越,且 ...
随机推荐
- TensorFlow 学习(十)—— 工具函数
1. 基本 tf.clip_by_value() 截断,常和对数函数结合使用 # 计算交叉熵 crose_ent = -tf.reduce_mean(tf.log(y_*tf.clip_by_valu ...
- 【23.33%】【codeforces 664C】International Olympiad
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...
- How to configure spring boot through annotations in order to have something similar to <jsp-config> in web.xml?
JSP file not rendering in Spring Boot web application You will need not one but two dependencies (ja ...
- hx计算机基础
参考:http://python.jobbole.com/82294/ https://www.jianshu.com/p/aed6067eeac9 1. 操作系统基础题 1)在32位操作系统下,系统 ...
- 第一次react-native项目实践要点总结 good
今天完成了我的第一个react-native项目的封包,当然其间各种环境各种坑,同时,成就感也是满满的.这里总结一下使用react-native的一些入门级重要点(不涉及环境).注意:阅读需要语法基础 ...
- OpenCV调试利器——Image Watch插件的安装和使用
各大编译工具在调试的时候都可以实时查看变量的值,了解变量值的变动情况,在图像处理相关的程序调试中,是否也可以实时查看内存中图像变量的图形信息以及图像上指定区域或点位的数值变化情况呢? 在工业机器视觉领 ...
- AI2XAML's Bug(sequel)
原文:AI2XAML's Bug(sequel) I wrote an article about AI2XAML's Bug the day before yesterday. This arti ...
- Bjarne Stroustrup语录2(一些C++使用注意点)
一.致读者 1. 在编程序时,你是在为你针对某个问题的解决方案中的思想建立起一种具体表示.让程序的结构尽可能地直接反映这些思想: ★.如果你能把“它”看成一个独立的概念,就把它做成一个类. ...
- OpenGL(二十二) gluBuild2DMipmaps 加载Mip纹理贴图
当纹理被用于渲染一个面积比它本身小很多的对象时,会由于纹理图像的降采样率不足而导致混叠现象,主要的表现特征是纹理图像的闪烁,出现纹理躁动.特别是在场景远近移动变换时,这种闪烁情况更为明显,严重可能会影 ...
- WPF 设置控件阴影后,引发的Y轴位置变化问题
原文:WPF 设置控件阴影后,引发的Y轴位置变化问题 背景 最近遇到一个动画执行时,文本位置变化的问题.如下图: 如果你仔细看的话,当星星变小时,文本往下降了几个像素. 貌似有点莫名其妙,因为控件之间 ...