Solr全文检索引擎配置及使用方法
介绍
Solr是一款开源的全文检索引擎,基于lucene。拥有完善的可配置功能界面。具有丰富的查询语言,可扩展,可优化。
下载安装
进入solr官网下载包(这里我使用的版本是8.0)
http://www.apache.org/dyn/closer.lua/lucene/solr/8.0.0
启动Solr
命令行进入solr的bin目录,提示Started Solr server on port 8983. Happy searching!即成功启动服务。
常用命令
solr start -p 端口号 启动服务
solr restart -p 端口号 重启服务
solr stop -p 端口号 关闭服务
solr create -c name 创建一个core实例

创建Core实例
Solr所有操作在Core中进行,所以使用Solr之前需先创建Core实例,Solr服务可创建多个Core实例。
两种方式创建Core实例,创建Core实例将在solr目录下server/solr生成对应目录。
通过命令创建

AdminUI创建
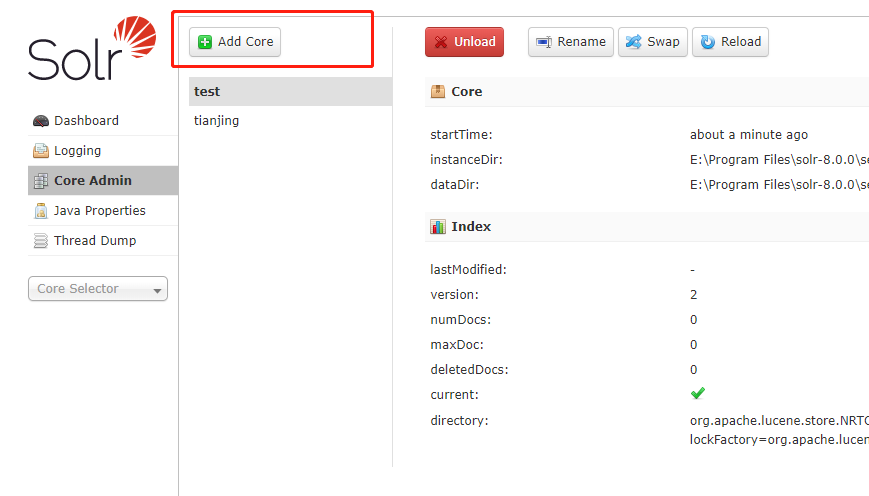
配置Schema
Schema配置将告诉solr服务如何建立索引,它的配置围绕core目录下conf/managed-schema文件,该文件指定每个字段类型,分词方式。
可通过手动编辑或者使用schemaAPI进行配置(推荐使用schemaAPI,可不需要重新加载Core或重启Solr服务,方便维护),不推荐使用手动编辑的方式(可能造成数据丢失)。
配置中文分词器
Solr虽然自带的中文分词器,但不能自定义中文词库,扩展性较差。这里我们使用IK分词器,这是一个第三方的分词器,可以很好的扩展中文词库。
github地址(含配置方法/使用教程):https://github.com/magese/ik-analyzer-solr
可在AdminUI中Analysis中测试分词效果
DIH导入索引数据
DIH全称是Data Import Handler 数据导入处理器,作用是将数据导入到Solr中,而数据存储在xml,pdf或关系型数据库中。solr首先需要获取这些数据,然后在数据中建立索引达到快速搜索的目的。
1.在core/conf/solrconfig.xml文件中配置数据导入文件映射位置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
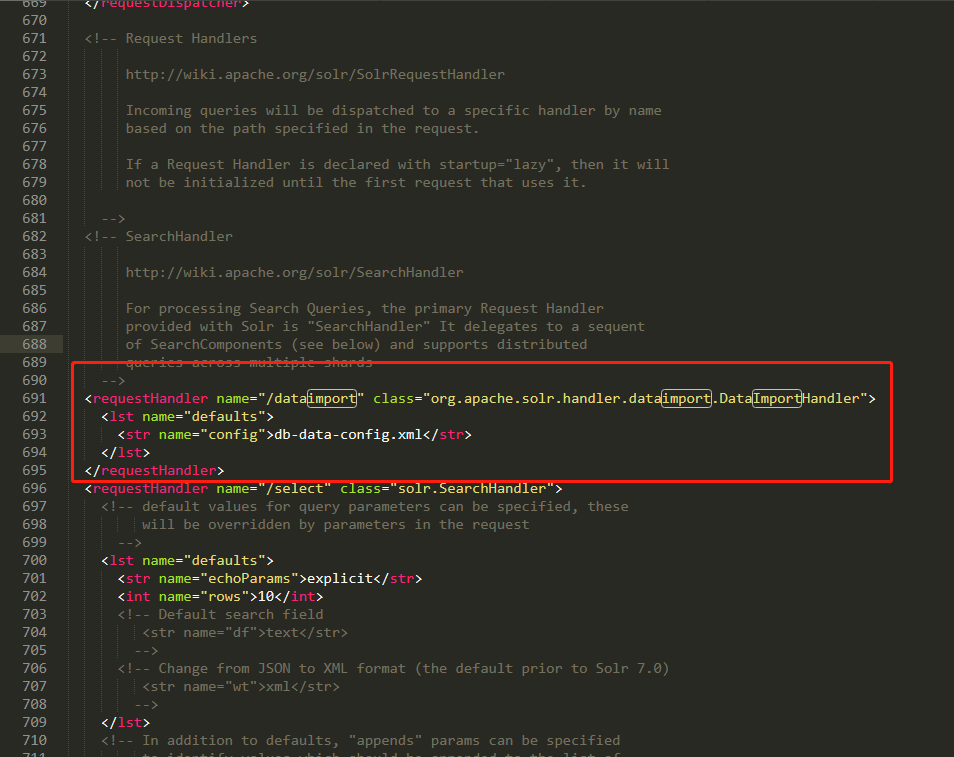
2.copy一份导入数据示例文件到core/conf/目录中,并重命名为db-data-config.xml
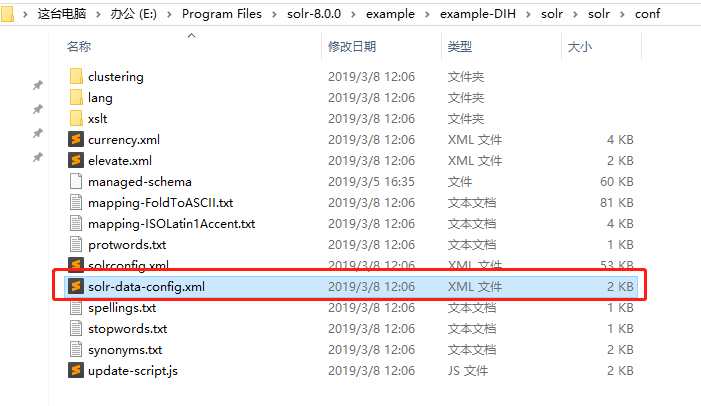
3.修改db-data-config.xml配置
<dataConfig>
<dataSource driver="org.postgresql.Driver" url="jdbc:postgresql://127.0.0.1:5432/test" user="postgres" password="123456"/>
<document>
<entity name="sw2015_p11shangyedasha" query="select id,name,address,ST_AsText(geom) as geom from sw2015_p11shangyedasha">
<field column="id" name="id"></field>
<field column="name" name="name"></field>
<field column="address" name="address"></field>
<field column="geom" name="geom"></field>
</entity>
</document>
</dataConfig>
4.执行DIH数据导入命令(AdminUI)
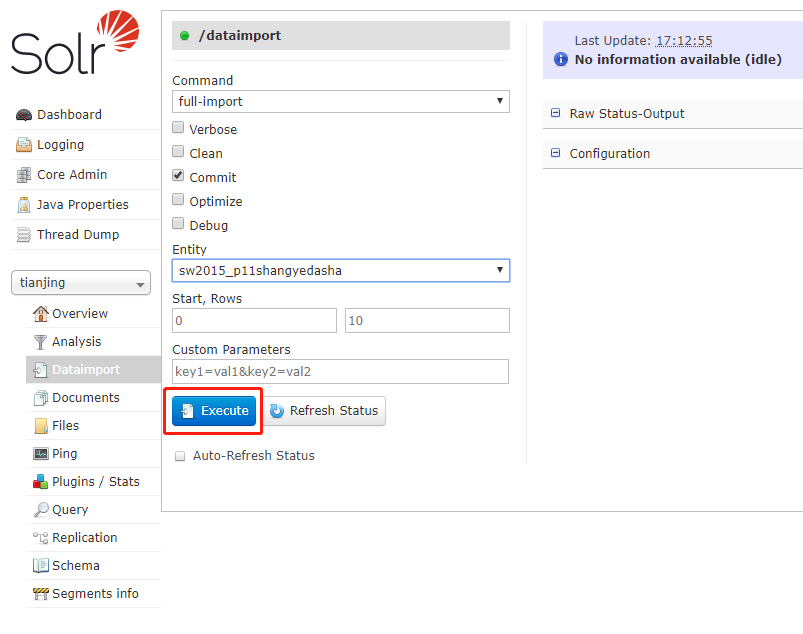
5.测试数据是否成功导入
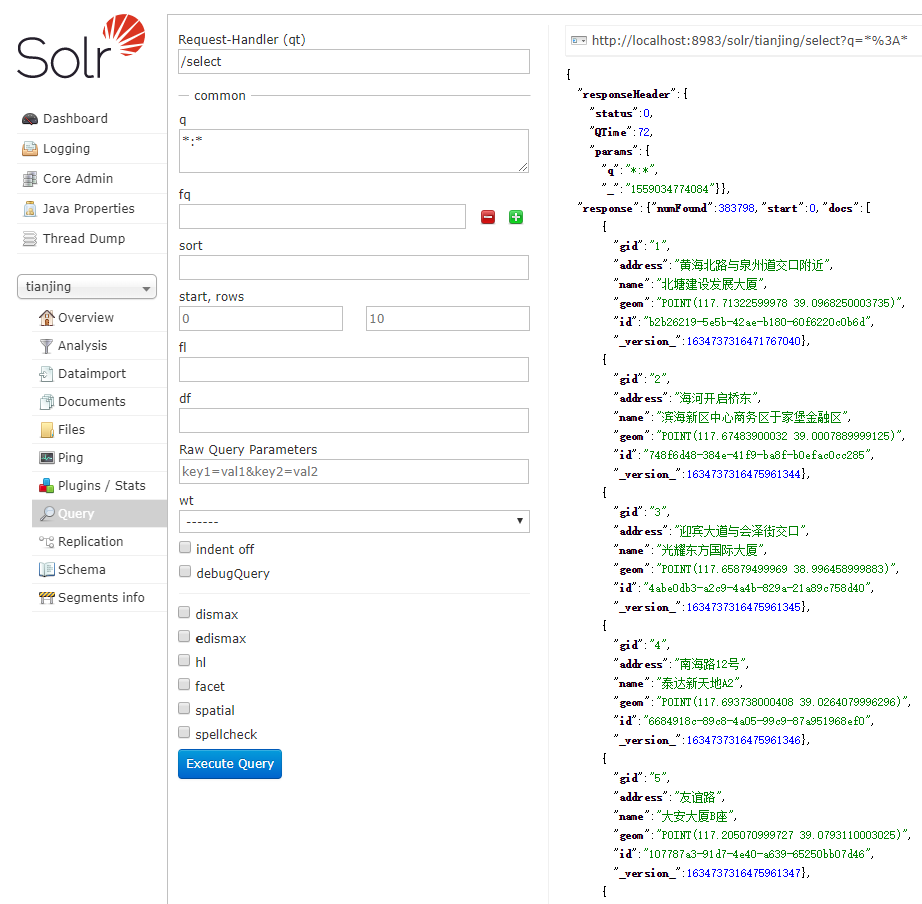
Query查询参数说明
q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=*:*,
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
sort 排序方式,例如id desc 表示按照 “id” 降序
wt (writer type)指定输出格式,有 xml, json, php等
fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
df 默认的查询字段,一般默认指定。
qt (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version 查询语法的版本,建议不使用它,由服务器指定默认值。
Solr的检索运算符
“:” 指定字段查指定值,如返回所有值*:*
“?” 表示单个任意字符的通配
“*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
“~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
AND、|| 布尔操作符
OR、&& 布尔操作符
NOT、!、-(排除操作符不能单独与项使用构成查询)
“+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在²
( ) 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510]
{} 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510}
JAVA连接Solr
maven引入solrj,solrj是java访问Solr的客户端工具包。
<!-- Solr -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>8.0.0</version>
</dependency>
SolrUtil.java
package com.bret.gis.utils; import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocumentList; public class SolrUtil { //指定solr服务器的地址
private final static String SOLR_URL = "http://localhost:8983/solr/"; /**
* 创建SolrServer对象
*
* 该对象有两个可以使用,都是线程安全的
* 1、CommonsHttpSolrServer:启动web服务器使用的,通过http请求的
* 2、 EmbeddedSolrServer:内嵌式的,导入solr的jar包就可以使用了
* 3、solr 4.0之后好像添加了不少东西,其中CommonsHttpSolrServer这个类改名为HttpSolrClient
*
* @return
*/
public HttpSolrClient createSolrServer(){
HttpSolrClient solr = null;
solr = new HttpSolrClient.Builder(SOLR_URL).withConnectionTimeout(10000).withSocketTimeout(60000).build();
return solr;
} /**
* 查询
* @throws Exception
*/
public SolrDocumentList querySolr(String q,int start,int rows) throws Exception{
HttpSolrClient solrServer = new HttpSolrClient.Builder(SOLR_URL + "tianjing/").withConnectionTimeout(10000).withSocketTimeout(60000).build();
SolrQuery query = new SolrQuery();
//下面设置solr查询参数
//query.set("q", "*:*");// 参数q 查询所有
query.set("q",q);//相关查询,比如某条数据某个字段含有周、星、驰三个字 将会查询出来 ,这个作用适用于联想查询 //参数fq, 给query增加过滤查询条件
query.addFilterQuery("id:[0 TO 9]");//id为0-4 //给query增加布尔过滤条件
//query.addFilterQuery("description:演员"); //description字段中含有“演员”两字的数据 //参数df,给query设置默认搜索域
query.set("df", "name"); //参数sort,设置返回结果的排序规则
query.setSort("id",SolrQuery.ORDER.desc); //设置分页参数
query.setStart(start);
query.setRows(rows);//每一页多少值 //参数hl,设置高亮
query.setHighlight(true);
//设置高亮的字段
query.addHighlightField("name");
//设置高亮的样式
query.setHighlightSimplePre("<font color='red'>");
query.setHighlightSimplePost("</font>"); //获取查询结果
QueryResponse response = solrServer.query(query);
//两种结果获取:得到文档集合或者实体对象 //查询得到文档的集合
SolrDocumentList solrDocumentList = response.getResults();
System.out.println("通过文档集合获取查询的结果");
System.out.println("查询结果的总数量:" + solrDocumentList.getNumFound());
//遍历列表
/*for (SolrDocument doc : solrDocumentList) {
System.out.println("id:"+doc.get("id")+" name:"+doc.get("name")+" description:"+doc.get("description"));
}*/
//得到实体对象
/*List<Person> tmpLists = response.getBeans(Person.class);
if(tmpLists!=null && tmpLists.size()>0){
System.out.println("通过文档集合获取查询的结果");
for(Person per:tmpLists){
System.out.println("id:"+per.getId()+" name:"+per.getName()+" description:"+per.getDescription());
}
}*/ return solrDocumentList; } }
Solr全文检索引擎配置及使用方法的更多相关文章
- 全文检索引擎Solr的配置
描述: 在Linux环境下实现高速的全文检索 一.当前环境: CentOS (Linux) 6.3 64 bit 二.所需软件 1.Java的JDK Java jdk 1.7.0[注意:solr5.x ...
- 全文检索引擎 Solr 部署与基本原理
全文检索引擎 Solr 部署与基本原理 搜索引擎Solr环境搭建实例 关于 solr , schema.xml 的配置说明 全文检索引擎Solr系列-–全文检索基本原理 一.搜索引擎Solr环境搭建实 ...
- 全文检索引擎及工具 Lucene Solr
全文检索引擎及工具 lucence lucence是一个全文检索引擎. lucence代码级别的使用步骤大致如下: 创建文档(org.apache.lucene.document.Document), ...
- [摘]全文检索引擎Solr系列—–全文检索基本原理
原文链接--http://www.importnew.com/12707.html 全文检索引擎Solr系列—–全文检索基本原理 2014/08/18 | 分类: 基础技术, 教程 | 2 条评论 | ...
- 全文检索引擎Solr 指南
全文检索引擎Solr系列:第一篇:http://t.cn/RP004gl.第二篇:http://t.cn/RPHDjk7 .第三篇:http://t.cn/RPuJt3T
- Solr全文检索框架
概述: 什么是Solr? Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webSh ...
- 全文检索引擎在Django中的使用
Haystack 1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsear ...
- solr全文检索学习
序言: 前面我们说了全局检索Lucene,但是我们发现Lucene在使用上还是有些不方便的,例如想要看索引的内容时,就必须自己调api去查,再例如一些添加文档,需要写的代码还是比较多的 另外我们之前说 ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
随机推荐
- jquery.nicescroll.min.js滚动条插件的用法
1.jquery.nicescroll.min.js源码 /* jquery.nicescroll 3.6.8 InuYaksa*2015 MIT http://nicescroll.areaaper ...
- 算法23-------岛屿的最大面积 LeetCode 695
一.题目: 给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合.你可以假设二维矩阵的四个边缘都被水包围着. 找到给定 ...
- UVA1584-Circular Sequence(紫书例题3.6)
Some DNA sequences exist in circular forms as in the following gure, which shows a circular sequence ...
- 【codeforces 452D】Washer, Dryer, Folder
[题目链接]:http://codeforces.com/problemset/problem/452/D [题意] 洗衣服有3个步骤,洗,干,叠; 有对应的3种洗衣机,分别有n1,n2,n3台,然后 ...
- 字符拆分存入Map计算单词的个数
///计算从命令行输入单词的种类与个数//Map<key,Value>Key-->单词:Value-->数量
- ftp for linux 配置
曾经配的熟悉的不能再熟悉了的东西,多年不用就忘了. 好真是好记性不如烂笔头.本文假如你已经安装好了, 1,ftp默认是不同意root用户登录的,假设要root用户登录,请例如以下改动:打开/etc/v ...
- [React] Work with HTML Canvas in React
React's abstraction over the DOM means that it's not always obvious how to do DOM-related things, li ...
- hiho模拟面试题2 补提交卡 (贪心,枚举)
题目: 时间限制:2000ms 单点时限:1000ms 内存限制:256MB 描写叙述 小Ho给自己定了一个雄伟的目标:连续100天每天坚持在hihoCoder上提交一个程序.100天过去了.小Ho查 ...
- C中操作文件的几种模式
使用文件的方式共同拥有12种,以下给出了它们的符号和意义. 文件打开方式 意义 rt 仅仅读打开一个文本文件.仅仅同意读数据 wt 仅仅写打开或建立一个文本文件,仅仅同意写数据 at 追 ...
- hdoj 4548 美素数 【打表】
另类打表:将从1到n的满足美素数条件的数目赋值给prime[n],这样最后仅仅须要用prime[L]减去prime[R-1]就可以: 美素数 Time Limit: 3000/1000 MS (Jav ...