Opencv决策树分类器应用
机器学习在数据挖掘、计算机视觉、搜索引擎、医学诊断、证券市场分析、语言与手写识别等领域有着十分广泛的应用,特别是在数据分析挥着越来越重要的作用。在机器学习中,决策树是最基础且应用最广泛的归纳推理算法之一,基于决策树算法,衍生出很多出色的集成算法,如random forest、adaboost、gradient tree boostiong等。
决策树构建的基本步骤如下:
1.开始,所有记录看作一个节点
2.遍历每个变量的每一种分割方式,找到最好的分割点
3.分割成两个节点N1和N2
4.对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止
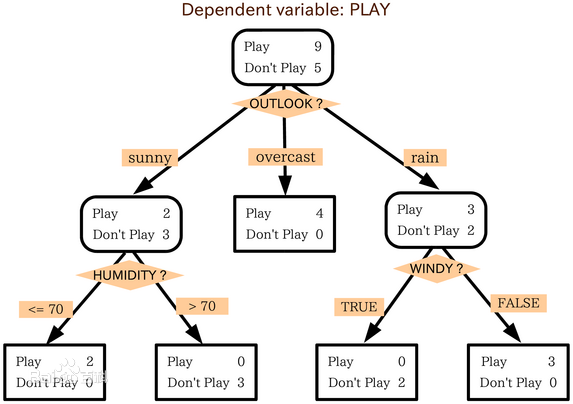
决策树归纳是从有类标号的训练元中学习决策模型。常用的决策树算法有ID3,C4.5和CART。它们都是采用贪心(即非回溯的)方法,自顶向下递归的分治方法构造。这几个算法选择属性划分的方法各不相同,ID3使用的是信息增益,C4.5使用的是信息增益率,而CART使用的是Gini基尼指数。
何为信息熵?信息熵是跟所有可能性有关系的。每个可能事件的发生都有个概率。信息熵就是平均而言发生一个事件我们信息量大小。所以数学 上,信息熵其实是信息量的期望。熵越大,说明系统越混乱,携带的信息就越少。熵越小,说明系统越有序,携带的信息就越多。
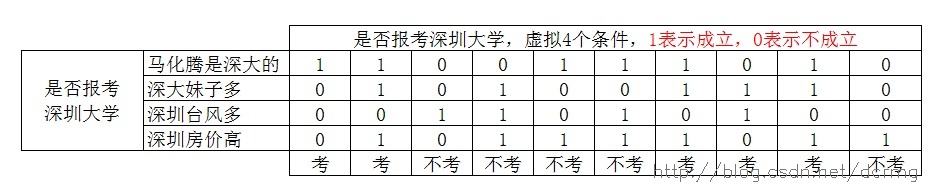
以下是根据4个条件的成立与否,来决定是否报考深圳大学,通过这10个样本生成决策树,进而对输入的4个条件来判断是否报考深大,以下是样本数据:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
//10个训练样本
float trainingDat[10][4]={{1,0,0,0},{1,1,0,1},{0,0,1,0},
{0,1,1,1},{1,0,0,0},{1,0,1,1},{1,1,1,1},{0,1,1,0},{1,1,0,1},{0,0,0,1}};
Mat trainingDataMat(10,4,CV_32FC1,trainingDat);
//样本的分类结果,作为标签供训练决策树分类器
float responses[10]={1,1,0,0,0,0,1,1,1,0}; // 1代表考取,0代表不考
Mat responsesMat(10,1,CV_32FC1,responses);
float priors[4]={1,1,1,1}; //先验概率,这里每个特征的概率都是一样的
//定义决策树参数
CvDTreeParams params(15, //决策树的最大深度
1, //决策树叶子节点的最小样本数
0, //回归精度,本例中忽略
false, //不使用替代分叉属性
25, //最大的类数量
0, //不需要交叉验证
false, //不需要使用1SE规则
false, //不对分支进行修剪
priors //先验概率
);
//掩码
Mat varTypeMat(5,1,CV_8U,Scalar::all(1));
CvDTree tree;
tree.train(trainingDataMat, //训练样本
CV_ROW_SAMPLE, //样本矩阵的行表示样本,列表示特征
responsesMat, //样本的响应值矩阵
Mat(),
Mat(),
varTypeMat, //类形式的掩码
Mat(), //没有属性确实
params //决策树参数
);
CvMat varImportance;
varImportance=tree.getVarImportance();
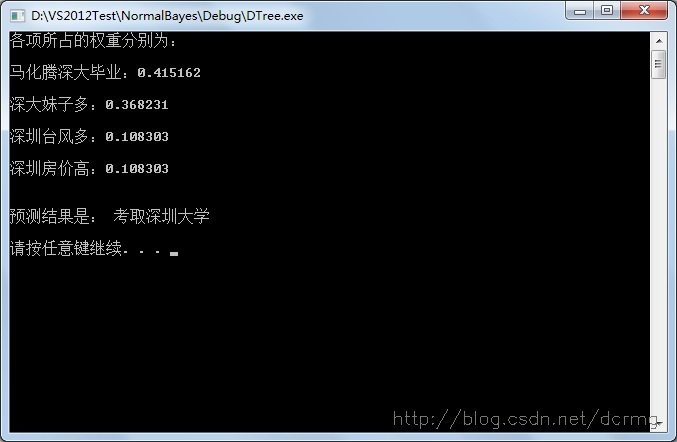
cout<<"各项所占的权重分别为:\n\n";
string item;
for(int i=0;i<varImportance.cols*varImportance.rows;i++)
{
switch (i)
{
case 0:
item="马化腾深大毕业:";
break;
case 1:
item="深大妹子多:";
break;
case 2:
item="深圳台风多:";
break;
case 3:
item="深圳房价高:";
break;
default:
break;
}
float value =varImportance.data.db[i];
cout<<item<<value<<endl<<endl;
}
float myData[4]={0,1,1,0}; //测试样本
Mat myDataMat(4,1,CV_32FC1,myData);
double r=tree.predict(myDataMat,Mat(),false)->value; //获得预测结果
if(r==(double)1.0)
{
cout<<endl<<"预测结果是: 考取深圳大学"<<endl<<endl;
}
else
{
cout<<endl<<"预测结果是: 不考取深圳大学"<<endl<<endl;
}
system("pause");
return 0;
}输入预测参数 0,1,1,0,结果为:
Opencv决策树分类器应用的更多相关文章
- OpenCV训练分类器制作xml文档
OpenCV训练分类器制作xml文档 (2011-08-25 15:50:06) 转载▼ 标签: 杂谈 分类: 学习 我的问题:有了opencv自带的那些xml人脸检测文档,我们就可以用cvLoad( ...
- 基于Python的决策树分类器与剪枝
作者|Angel Das 编译|VK 来源|Towards Data Science 介绍 决策树分类器是一种有监督的学习模型,在我们关心可解释性时非常有用. 决策树通过基于每个层次的多个问题做出决策 ...
- Opencv——级联分类器(AdaBoost)
API说明: cv::CascadeClassifier::detectMultiScale(InputArray image,//输入灰度图像 CV_OUT std::vector<Rect& ...
- 使用opencv训练分类器时,traincascade训练报错:Train dataset for temp stage can not be filled.解决方法
opencv分类器训练中,出错一般都是路径出错,例如, 1.opencv_traincascade.exe路径 2.负样本路径文件,neg.dat中的样本前路径是否正确 3.移植到别的电脑并修改完路径 ...
- OpenCV——级联分类器(CascadeClassifier)
级联分类器的计算特征值的基础类FeatureEvaluator 功能:读操作read.复制clone.获得特征类型getFeatureType,分配图片分配窗口的操作setImage.setWindo ...
- Opencv级联分类器实现人脸识别
在本章中,我们将学习如何使用OpenCV使用系统相机捕获帧.org.opencv.videoio包的VideoCapture类包含使用相机捕获视频的类和方法.让我们一步一步学习如何捕捉帧 - 第1步: ...
- OpenCV 级联分类器
#include "opencv2/objdetect/objdetect.hpp" #include "opencv2/highgui/highgui.hpp" ...
- opencv 训练自己的分类器汇总
原地址:http://www.cnblogs.com/zengqs/archive/2009/02/12/1389208.html OpenCV训练分类器 OpenCV训练分类器 一.简介 目标检测方 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
随机推荐
- 算法 Tricks(六)— if 条件分支的简化
考虑下面的三分支的定义式: f=⎧⎩⎨⎪⎪a,b,a+b,x>yx<yx=y int f = 0; if (x >= y) f += a; if (x <= y) f += b ...
- Android系统开发(7)——标准I/O与文件锁
一.常用函数 fopen: FILE *fopen(const char *filename, const char *mode); fread: size_t fread(void *ptz, s ...
- python课程:python3的输入输出
输出函数用法 (话说python3的输出好像没有python2的灵活了) print('hello,world') #单引号和双引号都可以输出print("hello,world&quo ...
- ArcGIS IQueryFilter接口
樱木 原文IQueryFilter 1.IQueryFilter::SubFields (1)默认值为“*”,即查询时返回整行数据,如果只需要某一个字段数据(比如“Country”字段),则可以指定 ...
- 贝叶斯统计(Bayesian statistics) vs 频率统计(Frequentist statistics):marginal likelihood(边缘似然)
1. Bayesian statistics 一组独立同分布的数据集 X=(x1,-,xn)(xi∼p(xi|θ)),参数 θ 同时也是被另外分布定义的随机变量 θ∼p(θ|α),此时: p(X|α) ...
- Android 各个版本号WebView
转载请注明出处 http://blog.csdn.net/typename/ powered by miechal zhao : miechalzhao@gmail.com 前言: 依据Googl ...
- inflate, findViewById与setContentView的区别与联系 分类: H1_ANDROID 2014-04-18 22:54 1119人阅读 评论(0) 收藏
protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentV ...
- 【读书笔记与思考】Andrew 机器学习课程笔记
Andrew 机器学习课程笔记 完成 Andrew 的课程结束至今已有一段时间,课程介绍深入浅出,很好的解释了模型的基本原理以及应用.在我看来这是个很好的入门视频,他老人家现在又出了一门 deep l ...
- HPE Comware Lab - Simulator
http://h20565.www2.hpe.com/hpsc/swd/public/readIndex?sp4ts.oid=7107838&ac.admitted=1405352934644 ...
- 【u018】电车
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 在一个神奇的小镇上有着一个特别的电车网络,它由一些路口和轨道组成,每个路口都连接着若干个轨道,每个轨道 ...