拒绝“爆雷”!GaussDB(for MySQL)新上线了这个功能
摘要:智能把控大数据量查询,防患系统奔溃于未然。
本文分享自华为云社区《拒绝“爆雷”!GaussDB(for MySQL)新上线了这个功能》,作者:GaussDB 数据库。
什么是最大读取行
一直以来,大数据量查询是数据库DBA们调优的重点,DBA们通常十八般武艺轮番上阵以期提升大数据查询的性能:例如分库分表、给表增加索引、设定合理的WHERE查询条件、限定单次查询的条数……
然而,DBA再厉害,应用程序千千万,写代码的程序员万码奔腾,大数据量的查询像地雷,不定什么时候就爆了。比如隐藏在某段代码里的查询,因为一个新手程序员的经验不足,查询代码写得欠佳,没有WHERE子句或缺少索引引发了不必要的多行读取,甚至全表扫描,给服务器带来了过度的压力,导致业务执行缓慢,甚至最后服务器OOM崩溃。
为了避免这种“爆雷”,GaussDB(for MySQL)近期上线了最大读取行特性。优化器产生执行计划后,如果优化器预估的读取行数超过了所设置的最大读取行阈值,则自动中止查询,将雷的导火索切断。
这种机制的优点在于:执行计划阶段就对查询进行了干预,而不是语句开始执行后在执行过程中进行中断。既杜绝了劣质查询对服务器和业务运行造成的风险,又大大节省了时间和资源。
如何设置最大读取行
在GaussDB(for MySQL)中,设置rds_max_row_read,指定查询允许读取的最大行数。GaussDB(for MySQL)收到查询指令,执行查询之前,会对查询要读取的行数进行估计。当估值超过所设置的最大读取行时,将中止查询,即查询没有机会运行,提前规避不必要的资源消耗。
下面是一份测试数据,说明了开启最大读取行前后的差异。
假设表t1有4M大小的行,当开发人员或应用程序尝试运行以下查询时,运行需要7分钟。
mysql> SELECT * FROM t1;
WHERE子句的缺失致使需要全表扫描,查询耗时长。对于更大的表,这类查询将需要更多的耗时,使服务器消耗更多资源,查询耗时甚至可能高达数小时。
最大读取行特性的使用,可以节省宝贵的时间和资源。比如假设将最大读取行数指定为1000000:
mysql> set rds_max_row_read =1000000;
Query OK, 0 rows affected (0.00 sec)
修改后,重新运行不含WHERE子句的查询,收到了读取行超限的提示,查询被停止。
mysql> SELECT * FROM t1;
ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
通过最大读取行,相当于拥有了一个工具,DBA或者软件工程师根据业务情况可以自如设置和调整限制规则,保证业务正常运行的同时,限制次优查询,避免性能异常。
适用范围
适用于SELECT、CREATE SELECT和INSERT SELECT。
功能开启
默认情况下,该功能是禁用的,只有当rds_max_row_read设置了值时,该功能才会被激活。
为了功能的稳定,避免无心的错误设置对业务造成不必要的影响,rds_max_row_read做了最低值限制,不允许用户设置比最低值更低的值。
实现原理
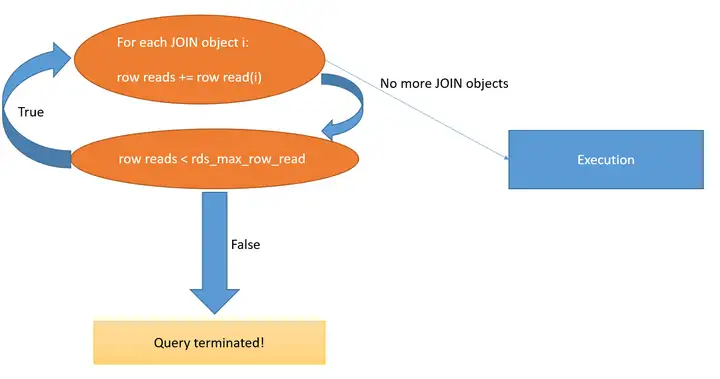
GaussDB(for MySQL)通过遍历每个查询块并聚合各查询块的贡献来整体评估查询的读取行数:也就是对各join对象的读取行数评估后累加。
如果在累加评估过程中的某一刻,估计值超过了所设置的限制,查询将被终止。
对于关联子查询,评估办法为:评估子查询的读取行数,然后乘以查询被执行的次数。
需要特别说明的是,对每个JOIN对象的估计是执行计划预估返回的行数,可能与真实执行返回的行数有偏差。这虽然是一个相对简单的评估模型,但是我们坚信其具有足够的鲁棒性。
对于复杂查询,GaussDB(for MySQL)还通过optimizer trace提供了更多信息以帮助您确定优化器做决策的原因及如何优化查询。
示例
示例1
mysql> EXPLAIN format=tree SELECT * FROM table_1, table_2;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (no condition) (cost=6.50 rows=54)
-> Table scan on table_1 (cost=0.19 rows=9)
-> Hash
-> Table scan on table_2 (cost=0.85 rows=6)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SET rds_max_row_read =20;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM table_1, table_2;
ERROR 1888 (HY000): The expected number of read rows exceeds the allowed maximum (see @@rds_max_row_read)
查询读取的行太多,我们尝试在optimizer trace的帮助下寻找原因:
SET optimizer_trace="enabled=on";
SELECT * from table_1, table_2;
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
在optimizer trace中,可以找到:
{
"Max_row_read": {
"select#": 1,
"current_estimate_of_rows": 54,
"rows_contributed_by_this_query_block": 54
}
}
这表示此查询中的唯一查询块,行读取数为54。
执行计划中的这个评估有多准确呢?
执行如下查询查看语句实际被执行的次数:
mysql> show status like "handler_read_rnd_next";
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_read_rnd_next | 17 |
+----------------------------+-------+
1 rows in set (0.00 sec)
handler_read_rnd_next显示实际上的读取是17行,而不是54行。
这个17是怎么来的呢?
这是一个哈希连接:
-遍历整张表时,左表有9行数据+1行额外行。
-右表有6行+1行额外行。
优化器中会预估返回读取行,例如,54。在这个示例中,它并没有很好地猜测到返回的行数,它高估了行读取的数量。在大多数情况下,读取行数的估计不够精确,但可以肯定的是,它是足够稳健的,能达到相应的目的。
示例2
创建例表t1:
mysql> CREATE TABLE t1(a INT);
在表中填充1536行数据后。将rds_max_row_read设置为500,进行以下测试查询:
mysql> SELECT * FROM t1 WHERE a>6;
ERROR HY000: Expected number of read rows exceeds the maximum allowed (see @@rds_max_row_read)
在optimizer trac的帮助下,可以看到优化器估计的读取行数是512行,因此查询被终止。如果在a字段上添加索引(这是一件明智的事情),同一查询的估计读取行数是1,查询检测顺利通过。
这个简单的示例说明:最大读取行能帮助您编写更加优质的查询语句。
结论
最大读取行特性针对读取过多行的查询,识别和过滤出效率低下的查询。用户可以为读取行数设置阈值,超过该阈值则终止查询。为了识别此类查询,GaussDB(for MySQL)在优化器中进行了读取总行数的粗略估计。当查询终止时,可以检查optimizer trace,从中收集线索,以帮助重写更高效的查询。
简而言之,最大读取行为用户提供了一个工具,使他们可以更充分地利用手上的资源。
拒绝“爆雷”!GaussDB(for MySQL)新上线了这个功能的更多相关文章
- 新上线MySQL数据库规划
新上线MySQL数据库规划1.删除test库2.删除root用户或者让root用户只可在本机登陆而对于有业务访问的数据库,在做删除root用户前需要依次确认 function.procedure.ev ...
- 不想业务被中断?快来解锁华为云RDS for MySQL新特性
摘要:新特性上线!华为云RDS for MySQL又添新技能,实力保障业务连续性. 本文分享自华为云社区<不想业务被中断?快来解锁华为云RDS for MySQL新特性>,作者:Gauss ...
- GaussDB(for MySQL) :Partial Result Cache,通过缓存中间结果对算子进行加速
摘要:华为云数据库高级内核技术专家详解GaussDB(for MySQL)Partial Result Cache特性,如何通过缓存中间结果对算子进行加速? 本文分享自华为云社区<GaussDB ...
- 【经验】GaussDB(for MySQL)性能优化 —— 日志的“快递驿站”
GaussDB(for MySQL)数据库在写入性能上,在业界同类产品中是最好的,这主要得益于GaussDB(for MySQL)在MySQL内核方面的诸多优化.其中有一项从“送快递”得来灵感的优化— ...
- 海量数据分析更快、更稳、更准。GaussDB(for MySQL) HTAP只读分析特性详解
本文作者康祥,华为云数据库内核开发工程师,研究生阶段主要从事SPARQL查询优化相关工作.目前在华为公司参与华为云GaussDB(for MySQL) HTAP只读内核功能设计和研发. 1. 引言 H ...
- P2P平台爆雷不断到底是谁的过错?
早在此前,范伟曾经在春晚上留下一句经典台词,"防不胜防啊".而将这句台词用在当下的P2P行业,似乎最合适不过了.就在这个炎热夏季,P2P行业却迎来最冷冽的寒冬. 引发爆雷潮的众多P ...
- P2P平台疯狂爆雷后,你的生活受到影响了吗?
最近这段时间P2P爆雷的新闻和报道一直占据着各大财经和科技媒体的重要位置.而据网贷之家数据显示,截至2018年7月底,P2P网贷行业累计平台数量达到6385家(含停业及问题平台),其中问题平台累计为2 ...
- MySQL新密码机制介绍caching_sha2_password
MySQL添加了对身份验证插件的支持,该插件现在称为mysql_native_password.该mysql_native_password插件使用SHA1哈希 将密码(SHA1(SHA1(passw ...
- 详解GaussDB(for MySQL)服务:复制策略与可用性分析
摘要:本文通过介绍GaussDB(for MySQL)读写路径,分析其可用性. 简介 数据持久性和服务可用性是数据库服务的关键特征. 在实践中,通常认为拥有 3 份数据副本,就足以保证持久性. 但是 ...
- 详解MySQL的用户密码过期功能
这篇文章主要为大家详细介绍了MySQL的用户密码过期功能的相关资料,需要的朋友可以参考下 Payment Card Industry,即支付卡行业,PCI行业表示借记卡.信用卡.预付卡.电子钱包. ...
随机推荐
- 标准c++中string类函数介绍
之所以抛弃char*的字符串而选用C++标准程序库中的string类,是因为他和前者比较起来,不必担心内存是否足够.字符串长度等等,而且作为一个类出现,他集成的操作函数足以完成我们大多数情况下(甚至是 ...
- mysql大小写无法区分问题
1.在创建表时设置编码格式 ALTER TABLE `test`.`t_test` COLLATE=utf8mb4_bin; 只能在建表或者没有数据时设置. 还有其他比如改字段格式,比如将varcha ...
- 1903021126 申文骏 Java 第六周作业 类与对象
项目 内容 课程班级博客链接 19级信计班(本) 作业要求链接 第六周作业 博客名称 1903021126 申文骏 Java 第六周作业 类与对象 要求 每道题要有题目,代码(使用插入代码,不会 ...
- [杂谈吐槽]UE国内社区环境
此篇博客是我个人想法,当然也是不争的事实,如果您有意见,那您也是我说那些人其中的一员. --此部分为社区环境差最恶劣的原因-- 国内的虚幻社区环境可以说不能再烂了,虚幻商城和虚幻引擎的蓝图是非常强大的 ...
- 【相邻父元素选择器】为啥p元素里面的h3也被选择了呢?求赐教
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>& ...
- OSIDP-多处理器和实时调度-10
多处理器调度 多处理器系统分类: 1.松耦合.分布式多处理器(集群):一系列相对自治的系统组成,每个处理器有属于自己的内存和I/O通道. 2.专用处理器:有一个通用的主处理器,专用处理器由主处理器控制 ...
- AJAX请求的基本操作
1 const { request, response } = require('express'); 2 //引入express 3 const express = require('express ...
- JSP中动态include和静态include的区别
a.静态include:语法:<%@ include file="文件名" %>,相当于复制,编辑时将对应的文件包含进来,当内容变化时,不会再一次对其编译,不易维护. ...
- 持续集成环境(2)-Jenkins插件管理
Jenkins本身不提供很多功能,我们可以通过使用插件来满足我们的使用.例如从Gitlab拉取代码,使用 Maven构建项目等功能需要依靠插件完成.接下来演示如何下载插件. 修改Jenkins插件下载 ...
- 2020.11.14 typeScript声明空间
在ts中存在两种声明空间: 类型声明空间和变量声明空间. 类型声明空间: 1. class People {} 2. interface People {} 3. type People = {} 变 ...