使用jmh框架进行benchmark测试
性能问题
最近在跑flink社区1.15版本使用json_value函数时,发现其性能很差,通过jstack查看堆栈经常在执行以下堆栈
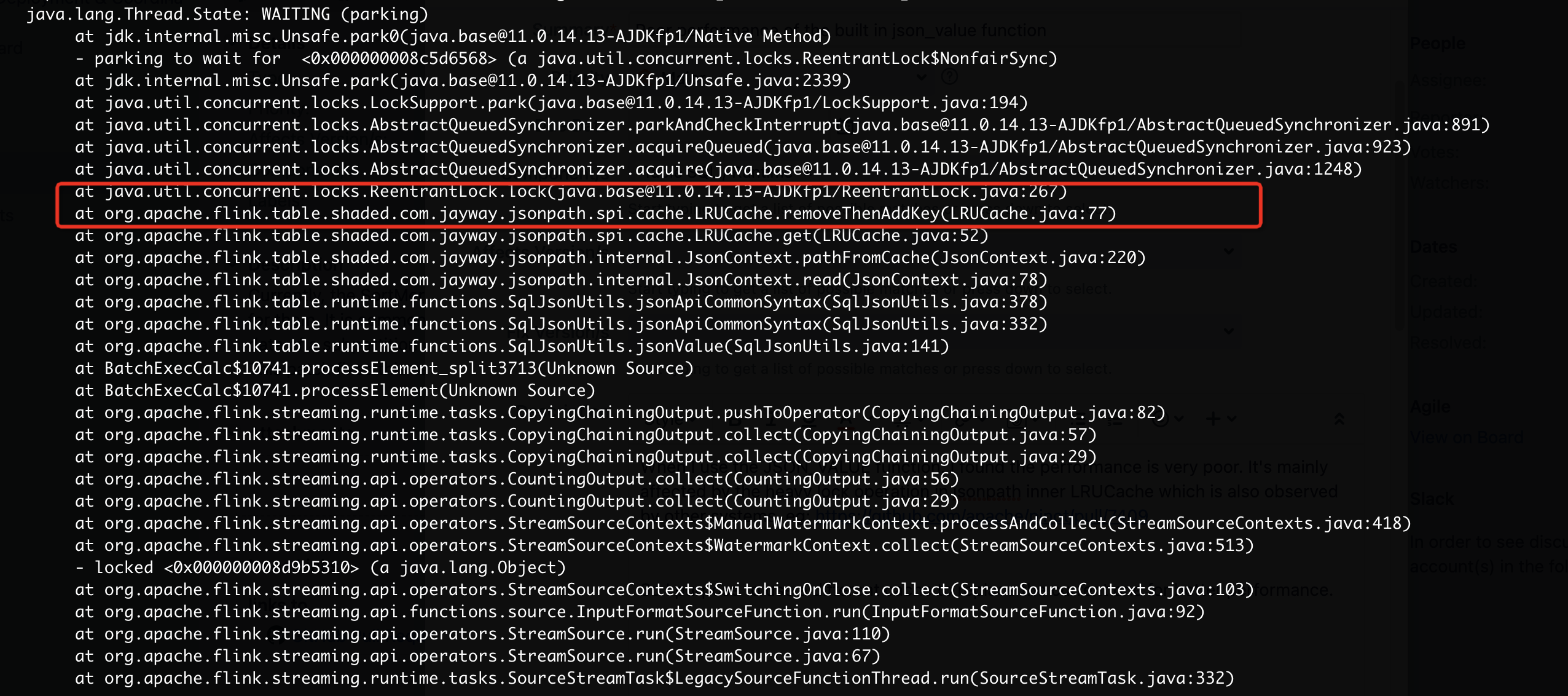
可以看到这里的逻辑是在等锁,查看jsonpath的LRUCache
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.apache.flink.table.shaded.com.jayway.jsonpath.spi.cache;
import java.util.Deque;
import java.util.LinkedList;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReentrantLock;
import org.apache.flink.table.shaded.com.jayway.jsonpath.JsonPath;
public class LRUCache implements Cache {
private final ReentrantLock lock = new ReentrantLock();
private final Map<String, JsonPath> map = new ConcurrentHashMap();
private final Deque<String> queue = new LinkedList();
private final int limit;
public LRUCache(int limit) {
this.limit = limit;
}
public void put(String key, JsonPath value) {
JsonPath oldValue = (JsonPath)this.map.put(key, value);
if (oldValue != null) {
this.removeThenAddKey(key);
} else {
this.addKey(key);
}
if (this.map.size() > this.limit) {
this.map.remove(this.removeLast());
}
}
public JsonPath get(String key) {
JsonPath jsonPath = (JsonPath)this.map.get(key);
if (jsonPath != null) {
this.removeThenAddKey(key);
}
return jsonPath;
}
private void addKey(String key) {
this.lock.lock();
try {
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private String removeLast() {
this.lock.lock();
String var2;
try {
String removedKey = (String)this.queue.removeLast();
var2 = removedKey;
} finally {
this.lock.unlock();
}
return var2;
}
private void removeThenAddKey(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
this.queue.addFirst(key);
} finally {
this.lock.unlock();
}
}
private void removeFirstOccurrence(String key) {
this.lock.lock();
try {
this.queue.removeFirstOccurrence(key);
} finally {
this.lock.unlock();
}
}
...
}
可以看到get操作时,如果获取到的是有值的,那么会更新相应key的数据从双端队列移到首位,借此来实现LRU的功能,但是这样每次get和put操作都是需要加锁的,因此并发情况下吞吐就会比较低,也会导致cpu使用效率较低。
从jsonpath社区查看相应的问题,也有相关的反馈
https://github.com/json-path/JsonPath/issues/740
https://github.com/apache/pinot/pull/7409
比较方便的是,jsonpath 提供了spi的方式可以自定义的设置Cache的实现类,可以通过以下方式来设置新的cache实现。
static {
CacheProvider.setCache(new JsonPathCache());
}
从pinot的实现中,我们看到他是用了guava的cache来替换了默认的LRUCache实现,那么这样实现性能优化有多少呢,这里我们是用java的性能测试框架jmh来测试下性能提升的情况
性能测试
这里为了方便,直接在flink-benchmark工程里添加了两个benchmark的测试类.
GuavaCache
LRUCache
这里面需要注意,因为cache是进程级别共享的,所以我们需要将设置@State(Benchmark)级别,这样我们构建的cache就是进程级别共享,而不是线程级别共享的。
写的测试是4个线程运行,缓存大小均为400
为了避免在本机运行时受本机的其他程序影响,最好是build jar之后放到服务器上跑
java -jar target/benchmarks.jar -rf csv org.apache.flink.benchmark.GuavaCacheBenchmark
得到一个测试结果
Benchmark Mode Cnt Score Error Units
GuavaCacheBenchmark.get thrpt 30 4480.563 ± 203.311 ops/ms
GuavaCacheBenchmark.put thrpt 30 1774.769 ± 119.198 ops/ms
LRUCacheBenchmark.get thrpt 30 441.239 ± 2.812 ops/ms
LRUCacheBenchmark.put thrpt 30 350.549 ± 12.285 ops/ms
可以看到使用guava的cache后,get性能提升8倍左右,put性能提升5倍左右。
这块性能提升的主要来源是cache的实现机制上,和caffeine 的作者在github上也简单了解了下相关的推荐实现
后面会写一篇文章来专门分析下caffeine cache的优化实现。
参考
https://github.com/ben-manes/caffeine/wiki/Benchmarks#read-100-1 caffeine benchmark
https://github.com/ben-manes/caffeine/blob/master/caffeine/src/jmh/java/com/github/benmanes/caffeine/cache/GetPutBenchmark.java caffeine benchmark
https://www.jianshu.com/p/ad34c4c8a2a3 jmh 框架常见参数
http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/ jmh 常见用例
使用jmh框架进行benchmark测试的更多相关文章
- IOS(SystemConfiguration)框架中关于测试连接网络状态相关方法
1. 在SystemConfiguration.famework中提供和联网相关的function, 可用来检查网络连接状态. 2. SC(SystemConfiguration)框架中关于测试连接网 ...
- Spring框架下Junit测试
Spring框架下Junit测试 一.设置 1.1 目录 设置源码目录和测试目录,这样在设置产生测试方法时,会统一放到一个目录,如果没有设置测试目录,则不会产生测试代码. 1.2 增加配置文件 Res ...
- [转帖]TPC-C解析系列01_TPC-C benchmark测试介绍
TPC-C解析系列01_TPC-C benchmark测试介绍 http://www.itpub.net/2019/10/08/3334/ 学习一下. 自从蚂蚁金服自研数据库OceanBase获得TP ...
- <自动化测试>之<使用unittest Python测试框架进行参数化测试>
最近在看视频时,虫师简单提到了简化自动化测试脚本用例中的代码量,而python中本身的参数化方法用来测试很糟糕,他在实际操作中使用了parameterized参数化... 有兴趣就查了下使用的方法,来 ...
- Java8 Stream代码详解+BenchMark测试
Java8 Stream基础.深入.测试 1.基本介绍 1.创建方式 1.Array的Stream创建 1.直接创建 // main Stream stream = Stream.of("a ...
- python实例编写(6)--引入unittest测试框架,构造测试集批量测试(以微信统一管理平台为例)
---恢复内容开始--- 一.python单元测试实例介绍 unittest框架又叫PyUnit框架,是python的单元测试框架. 先介绍一个普通的单元测试(不用unittest框架)的实例: 首先 ...
- 修改testtools框架,将测试结果显示用例注释名字
在之前介绍的测试框架testtool中,发现测试结果中显示的都是测试用例的函数名,并没有将注释显示出来 这很不符合国人使用阿,没办法,自己动手来改改吧 首先,testtools是继承unittest的 ...
- 框架重构:测试中的DateTime.Now
存在的问题 DateTime.Now是C#语言中获取计算机的当前时间的代码: 但是,在对使用了DateTime.Now的方法进行测试时,由于计算机时间的实时性,期望值一直在变化.如:计算年龄. pub ...
- YCSB benchmark测试mongodb性能——和web服务器测试性能结果类似
转自:http://blog.sina.com.cn/s/blog_48c95a190102v9kg.html YCSB(Yahoo! Cloud Serving Benchmark) ...
随机推荐
- Flask框架实现登录注册功能(mysql数据库)
前言: 本例使用Flask框架完成登录和注册操作,包括前端(index.html,regist.html)和后端(app.py)两部分,前端页面不过多介绍,直接进入后端部分: 逻辑思路: 登录部分:运 ...
- .net6.0 初探
概述:大概的了解一下 dotnet 6.0 建立 MVC web项目的过程以及程序调用 结合 EF 框架进行简单 的CRUD 1.选择创建 MVC 的Web项目 2.框架类型选择 6.0 3. 6 ...
- mybatis 转义符号
< <= > >= & ' " < <= > >= & ' "
- Kubernetes client-go DeltaFIFO 源码分析
概述Queue 接口DeltaFIFO元素增删改 - queueActionLocked()Pop()Replace() 概述 源码版本信息 Project: kubernetes Branch: m ...
- 使用Redis实现购物车功能
增加购物车商品 假设ID为1001的向购物车中存放了3个商品,产品ID分别为10021.10025.10079 hset cart:1001 10021 1 hset cart:1001 10025 ...
- sharepoint 配置失败,已引发类型为System.ArgumentException的异常。其他异常信息:domainName参数不支持指定的值。
解决方法:在域控制器中加入sharepoint计算机,设置为administrators组中
- 关于Vue的几个实用知识点(持续更新中……)
前言 排名不分先后,按自己习惯来的. 一.provide.inject 高级组件 总述: provide在父组件中定义,inject 在子孙组件中定义. provide:选项应该是一个对象或返回一个对 ...
- Vue是怎么渲染template内的标签内容的?
我们在使用Vue做项目时,都会用到脚手架,相应的我们会在template写标签内容.那么你知道为什么会在template写标签吗?这当中经过了怎样的处理呢? <template> < ...
- vue 的常用事件
vue 的常用事件 事件处理 1.使用 v-on:xxx 或 @xxx 绑定事件,其中 xxx 是事件名: 2.事件的回调需要配置在 methods 对象中,最终会在 vm 上: 3.methods ...
- 分享|智慧环保-生态文明信息化解决方案(附PDF)
内容摘要: 生态文明建设被提到前所未有的战略高度,我们既要绿水青山,也要金山银山.宁要绿水青山,不要金山银山,而且绿水青山就是金山银山.要正确处理好经济发展同生态环境保护的关系,牢固树立保护生态环境就 ...