故障案例 | 慢SQL引发MySQL高可用切换排查全过程
作者:梁行 万里数据库DBA,擅长数据库性能问题诊断、事务与锁问题的分析等,负责处理客户MySQL日常运维中的问题,对开源数据库相关技术非常感兴趣。
- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
一、现象说明
在排查问题时发现MySQL主备做了切换,而查看MySQL服务是正常的,DBA也没有做切换操作,服务器也无维护操作,万幸的是业务还没有受到大的波及。这到底是是为什么呢?
假设原主服务器地址为:172.16.87.72,原备主服务器地址为:172.16.87.123。
二、排查思路
通过监控查看MySQL的各个指标
查看双主(keepalived)服务切换日志
MySQL错误日志信息
三、问题排查
3.1 通过监控系统查看MySQL监控指标,判断故障发生的具体时间(通过流量判断大致切换时间点)
通过监控查看现在主库MySQL(支撑业务)的监控指标,看一天的、十五天的 (以每秒查询数量速率为例)
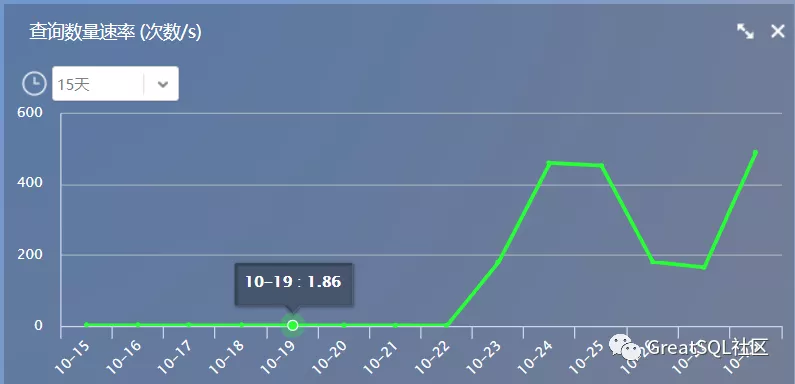
发现从22号开始陡增,初步怀疑,可能22号发生了主备切换,再看一下备库的折线图,进一步确认 查看双主(keepalived)服务切换日志,确定主从切换时间
3.2 查看keepalived判断为什么会做主从切换
先登录87.72查看keepalived的切换日志,日志信息如下:注:系统是ubuntu而且keepalived没有指定输出日志输出,所以keepalived会将日志输出到系统默认日志文件syslog.log中
shell> cat syslog.6|grep "vrrp"
Oct 23 15:50:34 bjuc-mysql1 Keepalived_vrrp: VRRP_Script(check_mysql) failed
Oct 23 15:50:34 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)'
Oct 23 15:50:35 bjuc-mysql1 Keepalived_vrrp: VRRP_Instance(VI_74) Received higher prio advert
Oct 23 15:50:35 bjuc-mysql1 Keepalived_vrrp: VRRP_Instance(VI_74) Entering BACKUP STATE
Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)'
Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)'
Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)'
Oct 23 15:50:35 bjuc-mysql1 syslog-ng[31634]: Error opening file for writing; filename='/var/log/tang/Keepalived_vrrp.log', error='No such file or directory (2)'
Oct 23 15:50:56 bjuc-mysql1 Keepalived_vrrp: VRRP_Script(check_mysql) succeeded
日志分析结果
从日志中可以发现,在Oct 23 15:50:34 因为检测脚本检测MySQL服务失败,导致了vip切换 再去87.123上查看keepalvied的切换,确定一下切换时间
Oct 23 15:50:35 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) forcing a new MASTER election
Oct 23 15:50:36 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) Transition to MASTER STATE
Oct 23 15:50:37 prod-UC-yewu-db-slave2 Keepalived_vrrp: VRRP_Instance(VI_74) Entering MASTER STATE
通过以上日志信息,我们发现双主是在Oct 23 15:50:35发生了切换
3.3 疑问?那么检测脚本为什么会检测失败呢?
查看检测脚本内容
shell> cat check_mysql.sh
#!/bin/bash
export PATH=$PATH:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
USER=xxx
PASSWORD=xxx
PORT=3306
IP=127.0.0.1
mysql --connect-timeout=1 -u$USER -p$PASSWORD -h$IP -P$PORT -e "select 1;"
exit $?
我们发现,检测脚本很简单,执行“select 1”命令,超时时间为1s,这个sql不影响MySQL任何操作,耗费性能很小,那为什么还会失败呢?我们去MySQL查看一下日志,看看有没有发现
3.4 查看MySQL日志
191023 15:50:54 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:55 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:55 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:56 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:56 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:57 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:58 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:58 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:50:59 [ERROR] /usr/sbin/mysqld: Sort aborted: Server shutdown in progress
191023 15:51:28 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE ticket SET max_id=max_id+step WHERE biz_tag='p2p_file'', Error_code: 1205
191023 15:54:43 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable.
191023 15:54:43 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205
191023 15:54:43 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.001432' position 973809430
191023 16:04:13 [ERROR] Error reading packet from server: Lost connection to MySQL server during query ( server_errno=2013)
191023 16:04:13 [Note] Slave I/O thread killed while reading event
191023 16:04:13 [Note] Slave I/O thread exiting, read up to log 'mysql-bin.001432', position 998926454
191023 16:04:20 [Note] Slave SQL thread initialized, starting replication in log 'mysql-bin.001432' at position 973809430, relay log './mysql-relay-bin.000188' position: 54422
191023 16:04:20 [Note] 'SQL_SLAVE_SKIP_COUNTER=1' executed at relay_log_file='./mysql-relay-bin.000188', relay_log_pos='54422', master_log_name='mysql-bin.001432', master_log_pos='973809430' and new position at relay_log_file='./mysql-relay-bin.000188', relay_log_pos='54661', master_log_name='mysql-bin.001432', master_log_pos='973809669'
191023 16:04:20 [Note] Slave I/O thread: connected to master 'zhu@x:3306',replication started in log 'mysql-bin.001432' at position 998926454
从日志中可以发现,MySQL在15:50:54报 Server shutdown in progress错误,在15:54:43 主从关系挂了,在16:04:20的时候主从关系自动恢复正常。那么这个报错是什么呢,Server shutdown in progress是什么意思呢?这个报错信息是因为在MySQL 5.5时,如果主动kill一个长的慢查询,而且这个sql还用到了sort buffer,就会出现类似MySQL重启的情况,连接也会关闭。
官方bug地址:https://bugs.mysql.com/bug.php?id=18256
赶紧去线上环境看看自己的环境是不是MySQL 5.5
mysql> \s
--------------
mysql Ver 14.14 Distrib 5.5.22, for debian-linux-gnu (x86_64) using readline 6.2
Connection id: 76593111
Current database:
Current user: xxx@127.0.0.1
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.5.22-0ubuntu1-log (Ubuntu)
Protocol version: 10
Connection: 127.0.0.1 via TCP/IP
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
TCP port: 3306
Uptime: 462 days 11 hours 50 min 11 sec
Threads: 9 Questions: 14266409536 Slow queries: 216936 Opens: 581411 Flush tables: 605 Open tables: 825 Queries per second avg: 357.022
我们看到线上环境是MySQL 5.5版本,运行时间为462 days 11 hours 50 min 11 sec,证明MySQL进程没有重启,那么通过刚才error日志(主从关系重启)验证了MySQL的这个bug so,keepalived在这一个发现MySQL不可用,就产生了failed。
3.5 那么我们再深挖一下,是什么慢sql导致被kill呢?
我们继续查找相应时间点的slow日志
# Time: 191023 15:50:39
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 35.571088 Lock_time: 0.742899 Rows_sent: 1 Rows_examined: 72
SET timestamp=1571817039;
SELECT g.id,g.group_pinyin, g.external_type,g.external_group_id,g.mount_id,g.is_display as group_type,g.nickname,g.site_id,g.group_logo,g.created,g.modified,g.misc,g.name_update_flag as name_flag, g.logo_level,g.group_status,g.conversation, g.only_admin_invite,g.reach_limit_count,g.water_mark FROM user_group AS g LEFT JOIN group_member as gm ON g.id = gm.group_id WHERE g.is_display in (1,2,3) AND gm.profile_id = 7382782 AND gm.join_state != 2 AND UNIX_TIMESTAMP(g.modified) > 1571722305 ORDER BY g.modified ASC LIMIT 0, 1000;
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 34.276504 Lock_time: 8.440094 Rows_sent: 1 Rows_examined: 1
SET timestamp=1571817039;
SELECT conversation, is_display as group_type, group_status FROM user_group WHERE id=295414;
# Time: 191023 15:50:40
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 31.410245 Lock_time: 0.561083 Rows_sent: 0 Rows_examined: 7
SET timestamp=1571817040;
SELECT id, clientScope, msgTop FROM uc_application where site_id=106762 AND msgTop=1;
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 38.442446 Lock_time: 2.762945 Rows_sent: 2 Rows_examined: 38
SET timestamp=1571817040;
SELECT g.id,g.group_pinyin, g.external_type,g.external_group_id,g.mount_id,g.is_display as group_type,g.nickname,g.site_id,g.group_logo,g.created,g.modified,g.misc,g.name_update_flag as name_flag, g.logo_level,g.group_status,g.conversation, g.only_admin_invite,g.reach_limit_count,g.water_mark FROM user_group AS g LEFT JOIN group_member as gm ON g.id = gm.group_id WHERE g.is_display in (1,2,3) AND gm.profile_id = 9867566 AND gm.join_state != 2 AND UNIX_TIMESTAMP(g.modified) > 1571796860 ORDER BY g.modified ASC LIMIT 0, 1000;
# Time: 191023 15:50:46
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 40.481602 Lock_time: 8.530303 Rows_sent: 0 Rows_examined: 1
SET timestamp=1571817046;
update heartbeat set modify=1571817004 where session_id='89b480936c1384305e35b531221b705332a4aebf';
# Time: 191023 15:50:41
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 32.748755 Lock_time: 0.000140 Rows_sent: 0 Rows_examined: 3
SET timestamp=1571817041;
SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(1316262,1352179,1338753) AND UNIX_TIMESTAMP(modified) > 1571023021 ORDER BY created ASC;
# Time: 191023 15:50:46
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 40.764872 Lock_time: 4.829707 Rows_sent: 0 Rows_examined: 7
SET timestamp=1571817046;
SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(673950,1261923,1261748,1262047,1038545,1184675,1261825) AND UNIX_TIMESTAMP(modified) > 1571744114 ORDER BY created ASC;
如上所示: 发现在这个时间段这条sql被执行了多次,时间都超过了30~60s,这个属于严重慢sql了
3.6 那么是什么操作执行了kill呢?
经过询问及排查,发现我们通过pt-kill用到了自动查杀功能,配置的查询超时时间为30s
shell> ps -aux|grep 87.72
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 3813 0.0 0.0 218988 8072 ? Ss Oct19 9:54 perl /usr/bin/pt-kill --busy-time 30 --interval 10 --match-command Query --ignore-user rep|repl|dba|ptkill --ignore-info 40001 SQL_NO_CACHE --victims all --print --kill --daemonize --charset utf8 --log=/tmp/ptkill.log.kill_____xxx_____172.16.87.72 -h172.16.87.72 -uxxxx -pxxxx
shell> cat /tmp/ptkill.log.kill_____xxx_____172.16.87.72
2019-10-23T15:45:37 KILL 75278028 (Query 39 sec) statusnet SELECT t.conv_id, t.notice_id, t.thread_type, t.parent_conv_id, t.seq, t.reply_count, t.last_reply_seq1, t.last_reply_seq2, t.revocation_seq, t.creator_id, t.status, t.operator_id, t.extra1 FROM notice_thread t WHERE parent_conv_id = 3075773 and notice_id in (1571816367355,1571814620251,1571814611880,1571814601809,1571814589604,1571814578823,1571814568507,1571814559399,1571812785487,1571812769810)
2019-10-23T15:45:37 KILL 75277932 (Query 39 sec) statusnet SELECT t.conv_id, t.notice_id, t.thread_type, t.parent_conv_id, t.seq, t.reply_count, t.last_reply_seq1, t.last_reply_seq2, t.revocation_seq, t.creator_id, t.status, t.operator_id, t.extra1 FROM notice_thread t WHERE parent_conv_id = 6396698 and notice_id in (18606128)
2019-10-23T15:45:37 KILL 75191686 (Query 39 sec) statusnet SELECT id,nickname,mount_id,is_display,external_type,misc,site_id,conversation as conv_id,only_admin_invite,reach_limit_count,water_mark, group_logo,logo_level,created,modified,name_update_flag as name_flag, group_pinyin, group_status,external_group_id,event_id FROM user_group WHERE id in(988091,736931,843788,739447,737242,1252702,736180,1150776) AND UNIX_TIMESTAMP(modified) > 1571740050 ORDER BY created ASC
发现果然是pt-kill主动去干掉了,结合之前的发现,真相已经在我们眼前了
3.7 那为什么这个sql跑了这么长时间,就单单这个时间报了呢?
我们结合其他时间的slow日志和当前的时间做个对比
# User@Host: dstatusnet[dstatusnet] @ [x]
# Query_time: 2.046068 Lock_time: 0.000079 Rows_sent: 1 Rows_examined: 1
SET timestamp=1572306496;
SELECT ... FROM user_group WHERE id in(693790) AND UNIX_TIMESTAMP(modified) > 0 ORDER BY created ASC;
我们发现一个规律,当where id in(单个值时)时,基本上是两秒,多个值时,时间就不固定了,这个结论有待其他证据进行进一步确认
四、那么我们如何解决呢?
解决及避免办法:
可以选择升级MySQL的版本(5.7的最高版本)
结合业务优化sql
Enjoy GreatSQL
本文由博客一文多发平台 OpenWrite 发布!
故障案例 | 慢SQL引发MySQL高可用切换排查全过程的更多相关文章
- MySQL高可用方案--MHA部署及故障转移
架构设计及必要配置 主机环境 IP 主机名 担任角色 192.168.192.128 node_master MySQL-Master| ...
- MySQL高可用架构故障自动转移插件MHA
mha高可用架构是目前mysql高可用故障转移比较成熟的解决方案.MHA插件复杂监控mysql主节点的健康情况.在主节点宕机后,MHA把binlog通过ssh传到从节点进行重做补齐.并提升其中一个从节 ...
- MySQL 高可用:mysql+Lvs+Keepalived 负载均衡及故障转移
系统信息: mysql主库 mysql从库 VIP 192.168.1.150 mysql 主主同步都设置 auto-increment-offset,auto-increment-increment ...
- MySQL 高可用架构在业务层面的应用分析
MySQL 高可用架构在业务层面的应用分析 http://mp.weixin.qq.com/s?__biz=MzAxNjAzMTQyMA==&mid=208312443&idx=1&a ...
- (5.8)mysql高可用系列——MySQL中的GTID复制(实践篇)
一.基于GTID的异步复制(一主一从)无数据/少数据搭建 二.基于GTID的无损半同步复制(一主一从)(mysql5.7)基于大数据量的初始化 正文: [0]概念 [0.5]GTID 复制(mysql ...
- (5.1)mysql高可用系列——高可用架构方案概述
关键词:mysql高可用概述,mysql高可用架构 常用高可用方案 20190918 现在业内常用的MySQL高可用方案有哪些?目前来说,用的比较多的开源方案分内置高可用与外部实现,内置高可用有如下: ...
- MySQL高可用集群方案
一.Mysql高可用解决方案 方案一:共享存储 一般共享存储采用比较多的是 SAN/NAS 方案. 方案二:操作系统实时数据块复制 这个方案的典型场景是 DRBD,DRBD架构(MySQL+DRBD+ ...
- MySQL高可用架构之MHA
简介: MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是 ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
随机推荐
- 通过CSS让图片变的清楚
image { width: 100%; height: 100%; border-radius: 10upx; //让图片变清楚 image-rendering: -moz-crisp-edges; ...
- Fast-Rcnn学习笔记
Fast-Rcnn学习笔记 paper code Fast-RCNN总览 step1:图片先放进卷积层 step2:再卷积层的特征图谱上回映射出对应的感兴趣区域 step3:集过一层ROI Pooli ...
- 【AC自动机】背单词
题意: 0 s v:添加价值为v的字符串s 1 t:查询t中含的s的权值和.(不停位置算多次) 思路: 在线AC自动机. 同学用过一个妙妙子的分块算法. 这里用二进制分组:通常用作把在线数据结构问题转 ...
- AcWing 4378. 选取数对
y总分析:这种题(我也不知道说的是哪种题hh)一般解法为贪心或dp,而本题用的是dp. 其实个人感觉题目不是很严谨,从y总讲解和题解分析得知各个数对区间是不能重叠的,但是题目使用的是≤,感觉数对的区间 ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- 渗透测试之sql注入验证安全与攻击性能
由于渗透测试牵涉到安全性以及攻击性,为了便于交流分享,本人这里不进行具体网址的透露了. 我们可以在网上查找一些公司官方网站如(http://www.XXXXXX.com/xxxx?id=1) 1.拿到 ...
- easyui combobox重复渲染问题
当一个页面有两个easyui combobox存在时,并且同时给两个combobox赋相同值,某些easyui的版本会导致其中一个无法切换选项. 解决办法,分两步赋值,可解决问题
- sed基本使用
1. 删除由空格组成的空白行 sed '/^ *$/d' test.txt sed '/[ ][ ]/d' test.txt 2. 删除空白行 sed '/^[[:space:]]*$/d' test ...
- bat-配置环境变量2-给PATH追加环境变量
使用setx /M path "%path%;%%winrar%%"这种方式修改环境变量存在的问题 对于 path 这种 既有用户级变量和系统级变量的变量 直接使用setx /M ...
- mysql备份数据库linux
备份数据库 问题描述: 我们用的是mysql,以今天遇到的情况为例,我们是在两台服务器上要搭相同的平台,部署完成后页面报错,发现是数据库的问题,我们打开数据库查看,确实数据库中少建一个wind数据 ...