redis底层数据结构之压缩列表(ziplist)
压缩列表(ziplist)
压缩列表(ziplist)是redis 为了节约内存而开发的,由连续内存块组成的顺序型数据结构,适用于长度较小的值
存取的效率高,内存占用小,但由于内存是连续的,在修改的时候要重新分配内存
同时满足以下两个条件时,使用ziplist:
1) 元素长度都小于64Byte
2) 元素数量小于512个
1 压缩列表结构
struct ziplist<T> {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
其中:
zlbytes:整个压缩列表占用的字节数,占4Byte
zltail_offset:最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个元素,占4Byte
zllength:压缩列表的元素个数,占2Byte
entries:压缩列表的元素,可以包含多个节点,每个节点可以保存一个字节数组或者一个整数值
zlend:压缩列表结束标志,值等于 0xFF,占1Byte
2 压缩列表节点结构
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize, len;
unsigned int headersize;
unsigned char encoding;
unsigned char *p;
} zlentry;
其中:
prevrawlen:前一个节点的长度
prevrawlensize:存储前一个节点长度(prevrawlen属性)所需的字节数
len:当前节点长度
lensize:储当前节点长度(len属性)所需的字节数
headersize:当前节点的header大小
encoding:节点的编码方式
p:指向节点的指针
虽然redis定义了节点zlentry结构体,但是redis却没有用zlentry结构来存储节点,因为,这个结构存小整数或短字符串太浪费空间
zlentry结构体在32位系统占用28Byte,在64位系统占用32Byte,这不符合压缩列表提高内存利用率的设计目的,因此,在redis中,并没有使用zlentry结构,而是定义了宏来表示压缩列表的节点
压缩列表的节点真正的结构如下图所示:
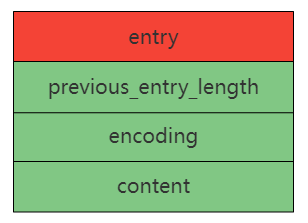
其中:
previous_entry_length:前一个节点的长度,占1Byte或5Byte
如果前一个节点的长度小于254Byte,则需要1Byte来保存前一个节点的长度
如果前一个节点的长度大于等于254Byte,则需要5Byte来保存前一个节点的长度,第一个Byte固定为0xfe(254),后四个Byte表示前一个节点的长度
encoding:编码类型(字节数组,整数),保存了content的数据类型和长度,占用1Byte、2Byte或者5Byte
content:节点数据,节点数据类型和长度由encoding决定
当前entry的总字节数 = 下一个entry的previous_entry_length的值 = previous_entry_length字节数 + encoding字节数 + content字节数
3 encoding编码类型
1) 字节数组类型
| encoding | encoding长度 | content字节数组长度 | 说明 |
| 00xxxxxx | 1Byte | 小于等于63(2^6-1)Byte | encoding的第一个字节最高两位是00,剩余的6位用来表示字节数组的长度 |
| 01xxxxxx|xxxxxxxx | 2Byte | 小于等于16383(2^14-1)Byte | encoding的第一个字节最高两位是01,剩余的14位用来表示字节数组的长度 |
| 10xxxxxx|xxxxxxxx|xxxxxxxx|xxxxxxxx|xxxxxxxx | 5Byte | 小于等于4294967295(2^32-1)Byte | encoding的第一个字节最高两位是10,剩余的4Byte共32位(第一个字节剩余的6位舍弃)用来表示字节数组的长度 |
保存"redis"和"ab"两个字符串的示意图
其中:
字符串"redis"占7Byte = (previous_entry_length = 1Byte) + (encoding = 1Byte) + (content = 5Byte)
字符串"ab"占4Byte = (previous_entry_length = 1Byte) + (encoding = 1Byte) + (content = 2Byte)

2) 整数类型
| encoding | encoding长度 | content整数类型 | 说明 |
| 11000000 | 1Byte | 2Byte的int16_t类型, -2^15~2^15-1 | encoding的值恒为0xC0 |
| 11010000 | 1Byte | 4Byte的int32_t类型,-2^31~2^31-1 | encoding的值恒为0xD0 |
| 11100000 | 1Byte | 8Byte的int64_t类型,-2^63~2^63-1 | encoding的值恒为0xE0 |
| 11110000 | 1Byte | 3Byte的整数,-2^23~2^23-1 | encoding的值恒为0xF0 |
| 11111110 | 1Byte | 1Byte的整数,-2^6~2^6-1 | encoding的值恒为0xFE |
| 1111xxxx | 1Byte | 无content字段 | xxxx只能取0001~1101,表示0~12的整数,4位之和减去1表示真正的整数,此时不需要content |
| 11111111 | 1Byte | 无content字段 | ziplist结束标志 |
保存2,10,1024三个整数的示意图
2,10的content不占用空间,1024的content占2字节
其中:
整数2占2Byte = (previous_entry_length = 1Byte) + (encoding = 1Byte) + (content = 0Byte)
整数10占2Byte = (previous_entry_length = 1Byte) + (encoding = 1Byte) + (content = 0Byte)
整数1024占4Byte = (previous_entry_length = 1Byte) + (encoding = 1Byte) + (content = 2Byte)

4 压缩列表示意图
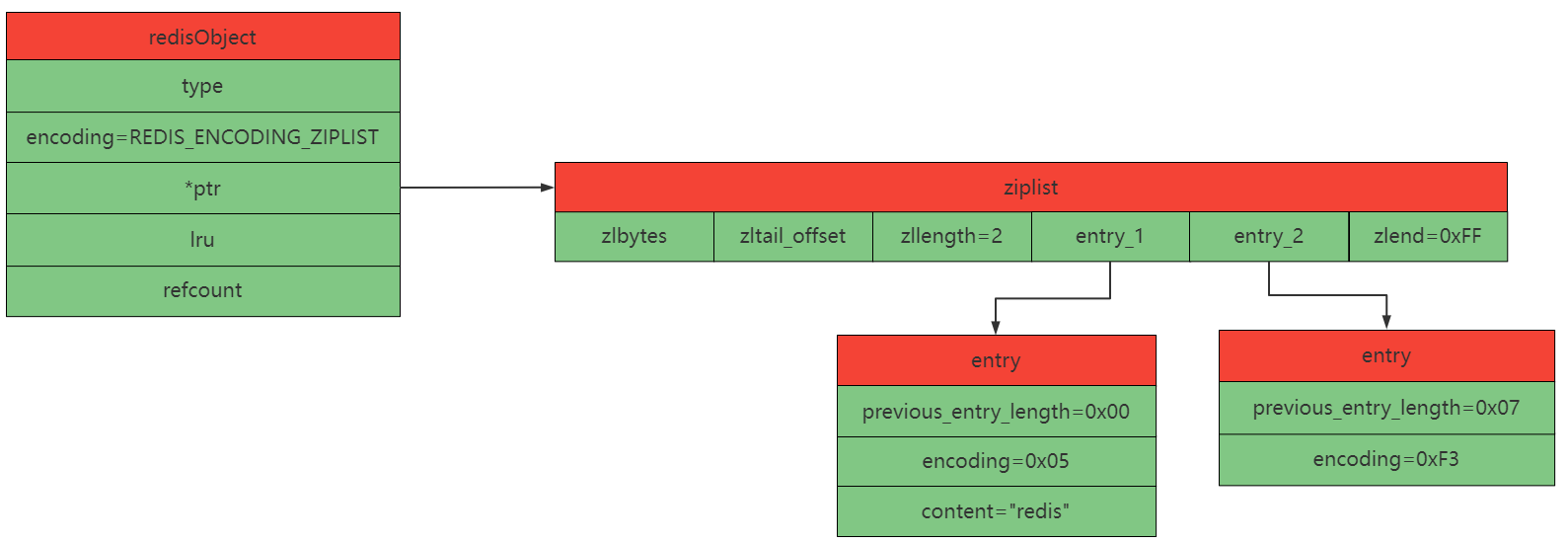
存有字符串"redis"和整数2共2个节点的ziplist示意图如下:
type = REDIS_LIST 或 REDIS_ZSET
5 连锁更新现象
previous_entry_length 记录了上一个entry 的长度,极端情况下: 如果每个entry的长度都是250~253Byte,那么如果在头部插一个节点的长度大于254Byte的entry节点,那么后一个节点的previous_entry_length值就从1Byte变为 5Byte,那么后一个entry节点的长度就大于了254Byte,再后面一个entry节点的previous_entry_length值也需要更新,引发连锁反应,后面所有的entry节点变大,previous_entry_length也变大,此时会频繁的进行数据迁移,申请内存,销毁动作,使性能受到很大影响
连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作,而每次空间重分配的最坏复杂度为 O(N),所以连锁更新的最坏复杂度为 O(N^2)
尽管连锁更新的复杂度较高,但它触发的概率很低
redis底层数据结构之压缩列表(ziplist)的更多相关文章
- Redis 底层数据结构之压缩列表
文章参考:<Redis 设计与实现>黄建宏 压缩列表 压缩列表 ziplist 是列表键和哈希键的底层实现之一.当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比 ...
- Redis数据结构之压缩列表-ziplist
为了节约内存,在zset和hash容器对象元素个数较少时,Redis会采用压缩列表(ziplist)进行存储. 压缩列表是一块连续的内存空间,元素之间紧挨着存储,不存在冗余 一个压缩列表可以包含任意多 ...
- redis源码之压缩列表ziplist
压缩列表ziplist1.简介连续,无序的数据结构.压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构. 2.组成 属性 类型 长 ...
- Redis 的底层数据结构(压缩列表)
上一篇我们介绍了 redis 中的整数集合这种数据结构的实现,也谈到了,引入这种数据结构的一个很大的原因就是,在某些仅有少量整数元素的集合场景,通过整数集合既可以达到字典的效率,也能使用远少于字典的内 ...
- redis 底层数据结构 压缩列表 ziplist
压缩列表是列表键和哈希键的底层实现之一.当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,redis就会使用压缩列表来做列表键的底层实现 当一个哈希键只包含少量键 ...
- Redis数据结构之压缩列表
压缩列表是Redis为了节约内存而开发的,由一系列特殊编码的连续内存块组成的顺序型数据结构.一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值. 一.压缩列表结构1. 压缩列 ...
- redis 5.0.7 源码阅读——压缩列表ziplist
redis中压缩列表ziplist相关的文件为:ziplist.h与ziplist.c 压缩列表是redis专门开发出来为了节约内存的内存编码数据结构.源码中关于压缩列表介绍的注释也写得比较详细. 一 ...
- Redis 底层数据结构介绍
Redis 底层数据结构 版本:2.9 支持的数据类型: 字符串 散列 列表 集合 有序集合 字符串 Redis 利用原生的 c 字符串进行了一次封装.封装的字符串叫做简单动态字符串:SDS(simp ...
- Redis底层数据结构详解
上一篇说了Redis有五种数据类型,今天就来聊一下Redis底层的数据结构是什么样的.是这一周看了<redis设计与实现>一书,现来总结一下.(看书总是非常烦躁的!) Redis是由C语言 ...
- Redis学习笔记(二)redis 底层数据结构
在上一节提到的图中,我们知道,可以通过 redisObject 对象的 type 和 encoding 属性.可以决定Redis 主要的底层数据结构:SDS.QuickList.ZipList.Has ...
随机推荐
- AtCoder Beginner Contest 285 解题报告
AtCoder Beginner Contest 285 解题报告 \(\text{DaiRuiChen007}\) Contest Link A. Edge Checker 2 假设 \(a\ge ...
- 【Redis技术专区】「优化案例」谈谈使用Redis慢查询日志以及Redis慢查询分析指南
前提介绍 本篇文章主要介绍了Redis的执行的慢查询的功能的查询和配置功能,从而可以方便我们在实际工作中,进行分析Redis的性能运行状况以及对应的优化Redis性能的佐证和指标因素. 在我们5.0左 ...
- 超简单的图文并茂Linux上使用yum安装Mysql(Aliyun Linux release 2.1903 LTS)
首先登录进入你的Linux服务器 查看是否已安装mysql rpm -qa|grep mysql 查看自己的服务器版本 cat /etc/redhat-release 打开MySQL Yum存储库下载 ...
- Zabbix“专家坐诊”第180期问答汇总
问题一 Q:老师,请教个问题,zabbix通过自动发现扫描网段,然后添加主机,有没有什么办法区分路由器或者交换机类型的方法,这样才能把交换机模板或者路由器模板挂给对应的主机A:不多的话, 批量加2次模 ...
- Hangfire .NET任务调度框架实例
1.介绍 Hangfire是一个开源的.NET任务调度框架,提供了内置集成化的控制台(后台任务调度面板),可以直观明了的查看作业调度情况. 2.Nuget安装 3.编写代码 1)测试服务:FirstS ...
- Docker挂载
1.挂载的概念 预备:你需要了解docker的基本知识 docker实现了容器部署,那当我们需要配置或者查看容器生成的日志文件怎么办? docker提供了挂载机制:挂载能够将容器内的目录/文件和外部的 ...
- Python GDAL读取栅格数据并基于质量评估波段QA对指定数据加以筛选掩膜
本文介绍基于Python语言中gdal模块,对遥感影像数据进行栅格读取与计算,同时基于QA波段对像元加以筛选.掩膜的操作. 本文所要实现的需求具体为:现有自行计算的全球叶面积指数(LAI).t ...
- JZOJ 3737. 【NOI2014模拟7.11】挖宝藏
\(\text{Solution}\) 当 \(h=1\) 时显然是斯坦纳树板子,最方案必然是树形的 \(h > 1\) 时,考虑在每一层新建一个状态表示上一层宝藏全部挖完到这层某个点的答案 同 ...
- 数位 dp,但是做题笔记
这玩意儿还要学自己推不出来的 SX 是屑. 数位 dp,顾名思义,是根据数位做 dp,每个数位每个数位转移,炒个例子 windy 数. 求 \([l, r]\),我们改成求 \(1\sim r\) 与 ...
- ubuntu20.04虚拟机无法自动获取IP地址
具体操作 # ens33 为网卡名称 sudo dhclient ens33