【大数据面试】【框架】kafka:组成、台数/参数配置、持久化、ISR队列、宕机、丢数据、重复数据、数据积压、优化各种配置(刷盘、存盘、副本、压缩)、zk、其他
一、基本信息
1、组成
生产者
broker
消费者
zookeeper:brokerid、consumer信息(不包含生产者的信息)
2、需要安装多少台
2 * (生产者的峰值生产速率 * 副本 / 100) + 1 = 3
生产环境下,配置副本的数量为2-3个,2个居多
3、副本的优势和劣势
副本越多,越能提高可靠性
增加了网络IO传输
4、峰值生产速率,一般在百兆左右每秒
需要使用压力测试
如,10T数据,多长时间可以传输完
消费速率也是百兆每秒
5、监控器用的什么
kafka egale、monitor、manager,都是开源的
我们都是自己研发的,怎么回答,仰视大佬
6、kafka数据保存多久
默认保存7天,生产环境下建议保存3天
原因:当天把数据消费完,才能做到T+1模式,消费完数据
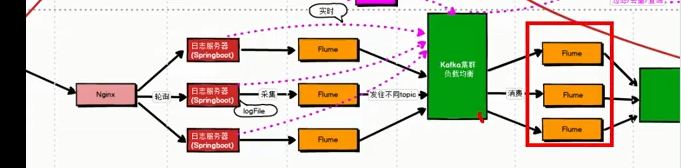
没有必要保存7天
其他原因:
日志服务器已经保存了30天☆(logfile)
7、数据量
条/S M/S
日活是100万时,1人1天100条,一天的日志数为1000000*100=1亿
1亿/(3600*24)=1150条/s
一条日志1k左右,生产环境下的日志大小为0.5K-2K之间
大约1M/S的数据
问:什么时间点数据量最大,最大能达到多少
晚上7-10点数据量达到高峰 =》 20M/S或30M/S左右,不要超过50M/S
原因:2 * (生产者的峰值生产速率 * 副本 / 100) + 1 = 3
2*(60*2/100)>3,三台kafka容易卡顿
8、100w日活对应100G数据量左右,给kafka预留多大的空间
100G*2个副本*保存3天/0.7(预留30%空间,zabbix磁盘报警)
9、设置多少个分区
一般设置3-10个分区
(1)设置1个分区
(2)进行压测:生产者峰值生产速率tp,消费者峰值生产速率cp
(3)有个预期的吞吐量是t
(4)分区数=t/min(tp, tc)
如tp=20M/S,tc=50M/S,t的期望值是100M/S
计算出的分区数=5个分区
分区数影响了并发度
10、ISR队列
解决leader挂了谁当老大,谁在队首就有机会
旧版:根据延迟时间和延迟条数判断
新版:根据延迟时间进行判断
11、分区分配策略
range:默认分区方式,分区特点是10个线程,3个分区,1234/567/8910,除不尽的放入低分区,容易产生数据倾斜
RandRobin:采用哈希的方式把任务随机打散,采用轮询的方式,减少数据倾斜
二、挂了/宕机的解决
1、分析
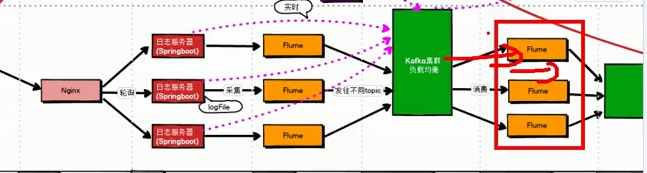
短时间内,数据进入到Flume Channel,长时间的话还有日志服务器存储30天的数据
Flume的非memory Channel都能保存一部分
三、丢失数据
1、看ACK,取值可以为0,1,-1
0:发送过去就不管了,可靠性最差,传输效率最高
1:发送过去,leader应答,可靠性一般,传输效率也一般
-1:发送过去,leader和follower共同应答,可靠性最高,传输效率最低
2、在生产环境下怎么选
0是没人选的
如果是普通日志,通常会选择1
如果是金融、和钱相关的,通常选择-1(上海比较多)
四、重复数据
1、【kafka去重】幂等性 + 事务 + ACK=-1【做到不丢不重:精确一次性消费】
单分区幂等性:只能保证单分区、单会话的数据不重复【单会话校验】
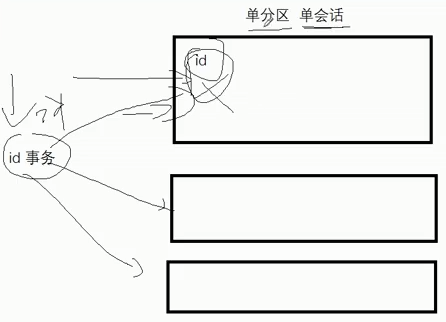
多分区事务:全局维护id,保证各个分区均不重复
两种方式为不同的级别,越增加校验越要求不重复,会带来更大的性能损失
很少同时使用幂等性+事务【精确一致性消费】
2、下一级处理:hive的DWD层 或 sparkstreaming、去重(groupby去重、redis、开窗函数取第一条)
3、不处理
五、数据积压【调参】
数据占满没有消费满
方案:自身找办法,找兄弟
自身找办法:增加并发度(增加分区),下一级消费者也要增加消费线程
(如果下一级是sparkstreaming,需要增加CPU核数,前边几个分区,就设置为几个CPU核数;)
(一次传输的数据是128M,对应1G的内存)
找兄弟:提高下一级消费者的消费能力,都有一个batch size参数 (1000/s---》2000-3000/s)
六、优化
1、配置文件
etc、conf、config
2、server.config
num.network.threads=3 计算线程,线程数=CPU核数+1
nums.io.threads=8 IO线程,线程数=CPU核数*2
CPU核数为8,计算线程为9,IO线程设为16
3、比较
进来后简单进行运算就出去:IO线程【IO密集型任务】
计算并行任务:进入后计算大量矩阵等运算后再出去,占用大量CPU时间,配置的线程数要少一些【计算密集型任务】
4、优化
kafka最终从内存进入磁盘,数据文件刷盘策略
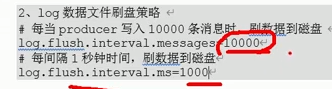
日志保留策略天数,设置为3天

副本数量,设置为2

5、producer.properties
compression.type压缩配置:none/snappy/gzip/lz4/zstd
通常使用zstd,默认是none
压缩的优势:减少磁盘空间、提高网络传输效率
劣势:如果是频繁计算的场景,就不要采用压缩【大量运算、解压缩、压缩,影响CPU效率】
6、kafka的默认内存调整
bin/kafka-server-start.sh

默认为1G,通常情况下会调整为4-6G,不要超过6G
如果6G还不行,增加kafka台数(自己,找兄弟)
七、其他
1、kafka为什么传输效率快
分布式集群、采用分区
采用顺序读写,可以达到600M/S(随机读写只能达到100M/S)
采用零拷贝机制:
配置好压缩后,也可以提高传输效率
2、如果传输的日志文件为2M,kafka会有什么问题
默认传输消息最大值为1M,超过1M,无法消费也无法生产
可以调整参数,server.properties

3、kafka的消息过期后的策略
前提:不被引用,未被消费
删除或压缩

4、其他场景:从之前某一时刻,重新消费数据

可以按照时间戳的形式,来消费数据
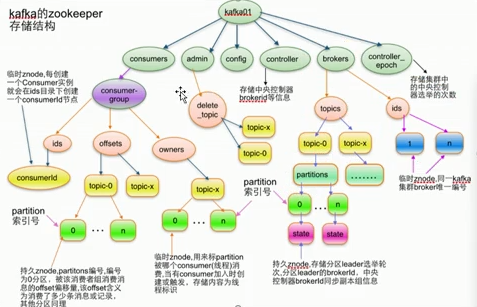
5、zk中存储了kafka的哪些信息
brokerid、topic、分区,里面没有生产者信息
【大数据面试】【框架】kafka:组成、台数/参数配置、持久化、ISR队列、宕机、丢数据、重复数据、数据积压、优化各种配置(刷盘、存盘、副本、压缩)、zk、其他的更多相关文章
- 记一次Kafka服务器宕机的真实经历!!
大家好,我是冰河~~ 估计节前前祭拜服务器不灵了,年后服务器总是或多或少的出现点问题.不知是人的问题,还是风水问题.昨天下班时,跟运维小伙伴交代了好几遍:如果使用Docker安装Kafka集群的话,也 ...
- 宕机了,Redis数据丢了怎么办?
持续原创输出,点击上方蓝字关注我 目录 前言 什么是AOF? 三种写回策略 日志文件太大怎么办? AOF重写会阻塞主线程吗? AOF的缺点 总结 什么是RDB? 给哪些数据做快照? 快照时能够修改数据 ...
- 修复ogg source端意外宕机造成的数据不同步
修复ogg source端意外宕机造成的数据不同步 分类: Oracle2016-04-28 11:50:40原文地址:修复ogg source端意外宕机造成的数据不同步 作者:十字螺丝钉 ogg s ...
- 大数据技术之Kafka
Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 学习大数据基础框架hadoop需要什么基础
什么是大数据?进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB(1 ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- Hadoop大数据面试--Hadoop篇
本篇大部分内容參考网上,当中性能部分參考:http://blog.cloudera.com/blog/2009/12/7-tips-for-improving-mapreduce-performanc ...
随机推荐
- ProxySQL(1):简介和安装
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9278818.html ProxySQL有两个版本:官方版和percona版,percona版是在官方版的基础 ...
- kubeoperator升级步骤
当前kubeoperator版本是3.6.0 官方文档:https://kubeoperator.io/docs/installation/install/ # 离线升级需要提前下载离线安装包,并解压 ...
- Elasticsearch基础但非常有用的功能之一:别名
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484454&idx=1&sn=43e95a2 ...
- netstat -lnp |grep XXX后不显示进程
netstat -lnp |grep XXX后不显示进程,不一定是没有进程,可能是这个命令不好使,换成 ps -ef | grep XXX
- python-函数-统计函数
#(1)amax(),amin() 作用:计算数组中的元素沿指定轴的最大值,最小值 import numpy as np x = np.random.randint(1,11,9).reshape(( ...
- Linux+Proton without Steam玩红警3指南
首先你需要Proton5.13 without Steam,使用说明和下载链接看这里https://www.cnblogs.com/tubentubentu/p/16716612.html 然后在/e ...
- Sun 的 BASE64Encoder替代
可以使用 org.apache.commons.codec.binary.Base64替代 Maven依赖如下 <dependency> <groupId>commons-co ...
- 银行ATM存取款系统(C语言实现)
这里使用的运行工具是DEV C++.老铁们一定要看仔细了.是DEV C++ 仅供借鉴:这个是大一时期写的.大四的时候整理了一下(本人C语言学的也不太好).肯定很多不足和存在漏洞的地方.仅供借鉴.仅供借 ...
- 成功解决:Can‘t find Python executable “python“, you can set the PYTHON env variable.
今天跑公司新项目的时候.运行前端vue.报了一个关于python的错误.就离谱 1.问题报错全部代码 actual version of core-js. npm ERR! code 1 npm ER ...
- 齐博X1-栏目的调用5
本节继续说明栏目的调用父级.同级.子级三层的栏目调用 父级.同级.子级三层的栏目调用 fun('sort@family',$fid,'cms') 比如下面栏目10利用这个函数,就可以调用出 父级9 同 ...