CUDA基础2
二、
1、指令调度,对于多条指令怎样调度让他们运行更快。
对于有冲突的两条指令,采用寄存器重命名技术。
2、指令重排 乱序执行,为了获取最大的吞吐率。 增大功耗 增加芯片面积。
3、缓存,容量越大速度越慢。把数据放在尽可能接近的位置。时间邻近性 空间邻近性。CPU芯片里,缓存就占了很大位置。
4、CPU内部的并行
指令级并行、数据级并行(矢量)、线程级并行。
三、
scalability 可扩展性 在100核心的基础上设计的程序,放在1000核心上,是不是有更好的加速。
五、GPU体系结构
GPU型的核心 和 CPU型的核心 有啥区别?
GPU小处理器
1、取址译码器 2、ALU 3、上下文
延迟隐藏:等待的过程中,切换到其他的线程执行。切换无成本。
上下文要存储起来,GPU提供一块128kb的上下文存储空间。
上下文的切换,可以软件也可以硬件。GPU是硬件管理,上下文贼多。
1、把分支预测 乱序执行之类的部件精简掉
2、多个core 多个ALU
3、大量任务、延迟隐藏
480个 Stream Processor 就是ALU 也叫CUDA Core
分成了15个 cores,每个core分成2组 16个 ALU。15个core,每个叫做一个SM。
另一个架构:
每个SM里有192个CUDA core,
CPU的缓存巨大,多级缓存。
GPU访存带宽非常宝贵。150GB/s,大概是CPU的6倍。但是GPU的吞吐比CPU高出数量级的。
一个SM里分好几组的处理单元,每个处理单元内是32个ALU。
warp是一个线程束。一个warp = 32个连续线程。
grid block warp都是软件层面的概念。都是线程的划分。
同一个block内的线程可以共享shared memory.
线程有local memory,当寄存器不够的时候,就放在local memory,local memory实际上在Global memory。
CPU 缓存 + 控制 + ALU,主要是缓存控制
GPU 主要是ALU
GPU通过硬件创建线程和管理。
问题:线程是怎么排布的?
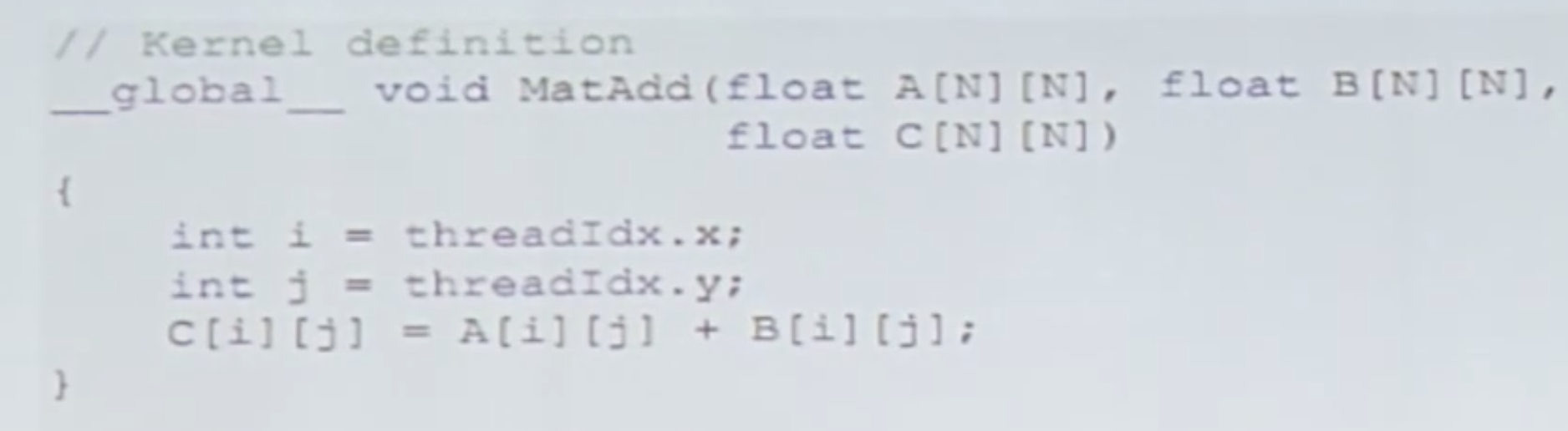
你怎么知道这是对齐访问的?
SM是硬件层面的概念。

会导致死锁
有的人在楼前门集合,有的在后门集合。这样永远没法集合。
SM中有ALU、上下文的存储空间、shared memory
每个SM可以驻扎巨多的线程,这些线程放在哪里?放在上下文空间里。warp调度,零开销。
SM上同一时刻只有一个warp在执行???一个SM有多少个cuda core?
一个SM里如果只有8个cuda core, 怎么办?每个warp分四批上去
每个SM有几千个寄存器。


local memory 每个thread 都有,用于存储自动变量数组。
第九集,有个矩阵乘,要写一下。 矩阵乘 用shared memory 怎么写,居然忘了都!!
第11集。并行规约,求和的运算,基础的CUDA并行算法,需要补充。
Global Memory访问 有几百个时钟周期。
half warp的所有线程 访问同一地址,有广播。没有冲突。
第12集,矩阵转置,要写代码。23分钟。记得补上。
Occupancy:激活的warp数与最大可容纳warp数的比值?没懂什么意思。

P12, 57分钟的优化
从13集以后不用看了 Fortran 和 cudnn
CUDA基础2的更多相关文章
- CUDA基础介绍
一.GPU简介 1985年8月20日ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年4月ATi发布了Mach32图形卡集成了图形加速功能,1998年4月ATi ...
- 【CUDA 基础】6.5 流回调
title: [CUDA 基础]6.5 流回调 categories: - CUDA - Freshman tags: - 流回调 toc: true date: 2018-06-20 21:56:1 ...
- 【CUDA 基础】6.3 重叠内和执行和数据传输
title: [CUDA 基础]6.3 重叠内和执行和数据传输 categories: - CUDA - Freshman tags: - 深度优先 - 广度优先 toc: true date: 20 ...
- 【CUDA 基础】6.1 流和事件概述
title: [CUDA 基础]6.1 流和事件概述 categories: - CUDA - Freshman tags: - 流 - 事件 toc: true date: 2018-06-10 2 ...
- 【CUDA 基础】6.2 并发内核执行
title: [CUDA 基础]6.2 并发内核执行 categories: - CUDA - Freshman tags: - 流 - 事件 - 深度优先 - 广度优先 - 硬件工作队列 - 默认流 ...
- 【CUDA 基础】6.0 流和并发
title: [CUDA 基础]6.0 流和并发 categories: - CUDA - Freshman tags: - 流 - 事件 - 网格级并行 - 同步机制 - NVVP toc: tru ...
- 【CUDA 基础】5.6 线程束洗牌指令
title: [CUDA 基础]5.6 线程束洗牌指令 categories: - CUDA - Freshman tags: - 线程束洗牌指令 toc: true date: 2018-06-06 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- 【CUDA 基础】5.2 共享内存的数据布局
title: [CUDA 基础]5.2 共享内存的数据布局 categories: - CUDA - Freshman tags: - 行主序 - 列主序 toc: true date: 2018-0 ...
随机推荐
- .NET在单台Windows2008下百万TCP连接测试
测试客户端: 客户端程序建立TCP连接,发送一条几个字节的数据. 虚拟机8台,PC机8台,服务器1台. 设置MaxUserPort=60000,有一台机没有设置约在1.5万左右.最后因为差一点到100 ...
- Flink 同时按照计数和时间触发窗口计算
自定义trigger 继承 抽象类 Trigger<T, TimeWindow> 主要实现 Trigger类的四个方法(onElement.onEventTime.onProcessin ...
- Python request模块 携带cookie
# _*_coding:utf-8 _*_ import time import requests import json import sys import random import string ...
- Taro 弹窗阻止小程序滑动穿透(亲测有效) tabbar数据缓存不更新 入口场景值不同
v3.0 推出后反馈最多的问题之一,就是在 touchmove 事件回调中调用 e.stopPropagation() 并不能阻止滑动穿透. 这是因为 Taro 3 的事件冒泡机制是单独在小程序逻辑层 ...
- 在安装SDK8.1和Visual Studio 2017时,提示“已停止工作”
解决办法:在微软官网下载 .net framework 的最新的开发包(Build apps - Dev Pack),重新安装后问题得到解决. https://dotnet.microsoft.com ...
- 12. Redis 安装
参考http://www.runoob.com/redis/redis-install.html Window 下安装 下载地址:https://github.com/MSOpenTech/redis ...
- PWM脉宽调制
PWM(pulse width modulation) .由微处理器输出一系列占空比不同的矩形脉冲(单个周期相同),应用在测量,通信,功率控制与变换的许多领域.优点是从微处理器到被控系统的信号都是数字 ...
- Windows相关产品密钥
Win7/Win8/Win10系统下Visual Studio 2013各个版本的密钥:Visual Studio Ultimate 2013: BWG7X-J98B3-W34RT-33B3R-JVY ...
- python 安装步骤
1.这个安装方法不需要配置环境变量 2. 3. 4.进入cmd,输入python -v
- 基于LabVIEW的计时器
前言: 最近有人问我,怎么实现一个计时器计时,可以做到启动.停止.重新开始等功能,好久没关于LABVIEW的博文,借这个写个计时器相关内容. 一.Labview时间计时器介绍: 这里采用时间计时器计算 ...