推荐系统系列(五):Deep Crossing理论与实践
背景
特征工程是绕不开的话题,巧妙的特征组合也许能够为模型带来质的提升。但同时,特征工程耗费的资源也是相当可观的,对于后期模型特征的维护、模型线上部署不太友好。2016年,微软提出Deep Crossing模型,旨在解决特征工程中特征组合的难题,降低人力特征组合的时间开销,通过模型自动学习特征的组合方式,也能达到不错的效果,且在各种任务中表现出较好的稳定性。
与之前介绍的FNN、PNN不同的是,Deep Crossing并没有采用显式交叉特征的方式,而是利用残差网络结构挖掘特征间的关系。本文将对DeepCrossing从原理到实现细节进行详细分析。
分析
1. DeepCrossing模型结构

整个模型包含四种结构:Embedding,Stacking,Residual Unit,Scoring Layer。
论文中使用的目标函数为 \(logloss\) :\(logloss=-\frac{1}{N}\sum_{i=1}^{N}(y_ilog(p_i)+(1-y_i)log(1-p_i))\) ,在实际应用中,可以灵活替换为其他目标函数。
下面对各层结构进行分析:
1.1 Embedding & Stacking
Embedding的主要目的是将高维稀疏特征转化为低维稠密特征,其公式化定义为:\(X_j^O=max(0,W_jX_j^I+b_j)\) ,其中 \(X_j^I\) 代表输入的第 \(j\) 个特征Field,并且已经过one-hot编码表示,\(Wb\) 分别表示对应的模型参数。与前几篇paper介绍的Embedding过程不同的是,DeepCrossing加上了偏置项 \(b\) 。公式中的 \(max\) 操作等价于使用 \(relu\) 激活函数。
尽管可以通过分Field的操作,减少Embedding层的参数量,但是由于某些 高基数特征 的存在,如paper中提到的CampaignID,其对应的 \(W_j\) 仍然十分庞大。为此作者提出,针对这些高基数特征构造衍生特征,具体操作如下。根据CampaignID的历史点击率从高到低选择Top1000个,编号从0到999,将剩余的ID统一编号为1000。同时构建其衍生特征,将所有ID对应的历史点击率组合成1001维的稠密矩阵,各个元素分别为对应ID的历史CTR,最后一个元素为剩余ID的平均CTR。通过降维引入衍生特征的方式,可以有效的减少高基数特征带来的参数量剧增问题。
经过Embedding之后,直接对所有的 \(X_j^O\) 进行拼接Stacking,\(X^O=[X_0^O,X_1^O,\dots,X_K^O]\) 。作者将特征embedding为256维,但是对于本身维度低于256的特征Field,无需进行Embedding,直接送入Stacking层,如上图中的 \(Feature\#2\) 所示。
1.2 Residual Unit
残差的网络结构如下:
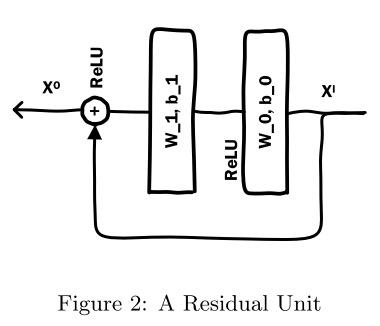
公式定义为:$X^O=F(X^I,\{W_0,W_1\},\{b_0,b_1\})+X^I$
将 \(X^I\) 移项到等式左侧,可以看出 \(F\) 函数拟合的是输入与输出之间的残差。对输入进行全连接变换之后,经过 \(relu\) 激活函数送入第二个全连接层,将输出结果与原始输入进行 element-wise add 操作,再经过 \(relu\) 激活输出。有分析说明,残差结构能更敏感的捕获输入输出之间的信息差 [2]。
作者通过各种类型各种大小的实验发现,DeepCrossing具有很好的鲁棒性,推测可能是因为残差结构能起到类似于正则的效果,但是具体原因是如何的并未明确指出,如果有同学了解具体原因,欢迎交流。
1.3 Scoring Layer
使用 \(logloss\) 作为目标函数,可以灵活改用其他函数表示。
2. Early Crossing vs. Late Crossing
在paper中,作者针对特征交叉的时间点先后的问题进行试验对比。在DeepCrossing中,特征是在Embedding之后就开始进行交叉,但是有一些模型如DSSM,是在各类特征单独处理完成之后再进行交叉计算,这类模型的结构如下所示:
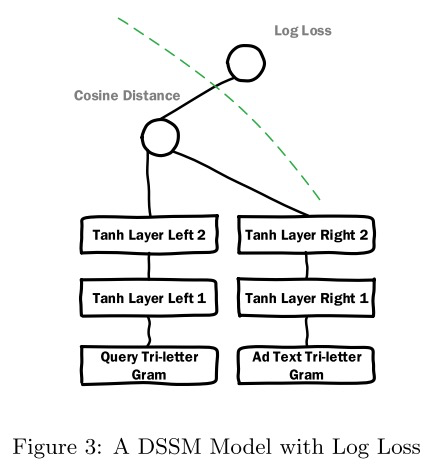
文中提到,DSSM更擅长文本处理,设计文本处理相关实验,DeepCrossing比DSSM表现更优异。作者认为,DeepCrossing表现优异主要来源于:1)残差结构;2)及早的特征交叉处理;
3. 性能分析
3.1 文本输入
输入特征相同,以DSSM作为baseline,根据Table 3可以看出DeepCrossing相对AUC更高。
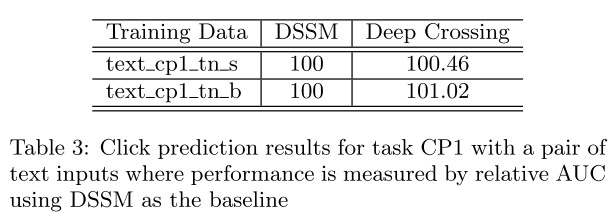
将生产环境的已有模型Production作为baseline进行对比,虽然DeepCrossing比DSSM表现更好,但稍逊Production。这是因为Production的训练数据集不同,且有更为丰富的特征。

### 3.2 其他对比
1)衍生特征Counting Feature的重要性比较
在1.1节中讨论过,为了对高基数特征进行降维处理,引入了统计类衍生特征(称之为Counting Feature)。对比此类特征对于模型的影响,从实验结果可以看出衍生特征能够带来较大提升。

2)与生产环境模型Production进行比较
使用Production训练特征的子集,使用22亿条数据进行训练。最终DeepCrossing表现超过了Production。

实验
使用 \(MovieLens100K dataset\) ,核心代码如下。
class DeepCrossing(object):
def __init__(self, vec_dim=None, field_lens=None, lr=None, residual_unit_num=None, residual_w_dim=None, dropout_rate=None, lamda=None):
self.vec_dim = vec_dim
self.field_lens = field_lens
self.field_num = len(field_lens)
self.lr = lr
self.residual_unit_num = residual_unit_num
self.residual_w_dim = residual_w_dim
self.dropout_rate = dropout_rate
self.lamda = float(lamda)
self.l2_reg = tf.contrib.layers.l2_regularizer(self.lamda)
self._build_graph()
def _build_graph(self):
self.add_input()
self.inference()
def add_input(self):
self.x = [tf.placeholder(tf.float32, name='input_x_%d'%i) for i in range(self.field_num)]
self.y = tf.placeholder(tf.float32, shape=[None], name='input_y')
self.is_train = tf.placeholder(tf.bool)
def _residual_unit(self, input, i):
x = input
in_node = self.field_num*self.vec_dim
out_node = self.residual_w_dim
w0 = tf.get_variable(name='residual_w0_%d'%i, shape=[in_node, out_node], dtype=tf.float32, regularizer=self.l2_reg)
b0 = tf.get_variable(name='residual_b0_%d'%i, shape=[out_node], dtype=tf.float32)
residual = tf.nn.relu(tf.matmul(input, w0) + b0)
w1 = tf.get_variable(name='residual_w1_%d'%i, shape=[out_node, in_node], dtype=tf.float32, regularizer=self.l2_reg)
b1 = tf.get_variable(name='residual_b1_%d'%i, shape=[in_node], dtype=tf.float32)
residual = tf.matmul(residual, w1) + b1
out = tf.nn.relu(residual+x)
return out
def inference(self):
with tf.variable_scope('emb_part'):
emb = [tf.get_variable(name='emb_%d'%i, shape=[self.field_lens[i], self.vec_dim], dtype=tf.float32, regularizer=self.l2_reg) for i in range(self.field_num)]
emb_layer = tf.concat([tf.matmul(self.x[i], emb[i]) for i in range(self.field_num)], axis=1) # (batch, F*K)
x = emb_layer
with tf.variable_scope('residual_part'):
for i in range(self.residual_unit_num):
x = self._residual_unit(x, i)
x = tf.layers.dropout(x, rate=self.dropout_rate, training=self.is_train)
w = tf.get_variable(name='w', shape=[self.field_num*self.vec_dim, 1], dtype=tf.float32, regularizer=self.l2_reg)
b = tf.get_variable(name='b', shape=[1], dtype=tf.float32)
self.y_logits = tf.matmul(x, w) + b
self.y_hat = tf.nn.sigmoid(self.y_logits)
self.pred_label = tf.cast(self.y_hat > 0.5, tf.int32)
self.loss = -tf.reduce_mean(self.y*tf.log(self.y_hat+1e-8) + (1-self.y)*tf.log(1-self.y_hat+1e-8))
reg_variables = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
if len(reg_variables) > 0:
self.loss += tf.add_n(reg_variables)
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
reference
[1] Shan, Ying, et al. "Deep crossing: Web-scale modeling without manually crafted combinatorial features." Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2016.
[2] https://zhuanlan.zhihu.com/p/72679537
[3] https://www.zhihu.com/question/20830906/answer/681688041
知识分享
个人知乎专栏:https://zhuanlan.zhihu.com/c_1164954275573858304
欢迎关注微信公众号:SOTA Lab
专注知识分享,不定期更新计算机、金融类文章

推荐系统系列(五):Deep Crossing理论与实践的更多相关文章
- 推荐系统系列(四):PNN理论与实践
背景 上一篇文章介绍了FNN [2],在FM的基础上引入了DNN对特征进行高阶组合提高模型表现.但FNN并不是完美的,针对FNN的缺点上交与UCL于2016年联合提出一种新的改进模型PNN(Produ ...
- 推荐系统实践 0x10 Deep Crossing
这一篇,我们将介绍微软BING AD团队提出的Deep Crossing模型,用来解决大规模特征组合问题的模型,这些特征可以是稠密的,也可以是稀疏的,从而避免了人工进行特征组合,并使用了当年提出的残差 ...
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- Java 理论与实践: 流行的原子
Java 理论与实践: 流行的原子 新原子类是 java.util.concurrent 的隐藏精华 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 ...
- ARM NEON指令集优化理论与实践
ARM NEON指令集优化理论与实践 一.简介 NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bi ...
- paper 8:支持向量机系列五:Numerical Optimization —— 简要介绍求解求解 SVM 的数值优化算法。
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
- Java 理论和实践: 了解泛型
转载自 : http://www.ibm.com/developerworks/cn/java/j-jtp01255.html 表面上看起来,无论语法还是应用的环境(比如容器类),泛型类型(或者泛型) ...
随机推荐
- 更改:把redis替换成kafka
之前的流程是:filebeat,redis,logstash,elasticsearch 现在的流程是:filebeat,Kafka(zookeeper),logstash,elasticsearch ...
- Lua的API函数
1. 基础库 我们在整个教程中使用了各种主题下的基本库. 下表提供了相关页面的链接,并列出了本Lua教程各部分所涵盖的功能. 编号 库/方法 作用 1 错误处理 包括错误处理函数,如断言, 错误,如L ...
- dev grid的一些使用
保留选中数据,其他数据删除,不操作数据库 private void butnoremove_Click(object sender, EventArgs e) { int iSelectRowCoun ...
- rsync 文件同步 linux
3.rsync+sersync更快更节约资源实现web数据同步4.unison+inotify实现web数据双向同步
- JavaScript中变量声明效率问题
1 var theString1 = "字符串1"; var theString2 = "字符串1"; var theString3 = "字符串1& ...
- Databus&canal对比
Databus和canal都能够提供实时从数据库获取变更,并提供给下游的实时消费流的功能. 本文针对两个系统实现和应用上的不同点,做了一个简单的对比: 对比项 Databus canal 结论 支持的 ...
- Shiro学习笔记总结,附加" 身份认证 "源码案例(一)
Shiro学习笔记总结 内容介绍: 一.Shiro介绍 二.subject认证主体 三.身份认证流程 四.Realm & JDBC reaml介绍 五.Shiro.ini配置介绍 六.源码案例 ...
- Odoo的菜单项
用户界面的入口是菜单项,菜单项形成一个层级结构,最顶级项为应用,其下一级为每个应用的主菜单.还可以添加更深的子菜单.可操作菜单与窗口操作关联,它告诉客户端在点击了菜单项后应执行什么操作. 菜单项存储在 ...
- Delphi MSComm控件的错误消息
- 利用openssl完成自签发证书步骤--精华版
#CentOS 7 CA目录 cd /etc/pki/CA #建立 demoCA 目录结构mkdir -p ./demoCA/{private,newcerts}touch ./demoCA/inde ...