统计学习方法 | 第1章 统计学习方法概论 | np.random.rand()函数
np.random.rand()函数
语法:
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
应用:在深度学习的Dropout正则化方法中,可以用于生成dropout随机向量(dl),例如(keep_prob表示保留神经元的比例):dl = np.random.rand(al.shape[0],al.shape[1]) < keep_prob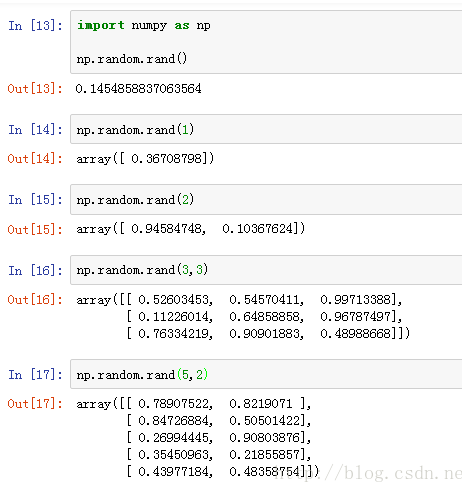
np.random.randn()函数
语法:
np.random.randn(d0,d1,d2……dn)
1) 当函数括号内没有参数时,则返回一个浮点数;
2)当函数括号内有一个参数时,则返回秩为1的数组,不能表示向量和矩阵;
3)当函数括号内有两个及以上参数时,则返回对应维度的数组,能表示向量或矩阵;
4)np.random.standard_normal()函数与np.random.randn()类似,但是np.random.standard_normal()
的输入参数为元组(tuple).
5)np.random.randn()的输入通常为整数,但是如果为浮点数,则会自动直接截断转换为整数。
作用:
通过本函数可以返回一个或一组服从标准正态分布的随机样本值。
特点:
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。对应的正态分布曲线如下所示,即
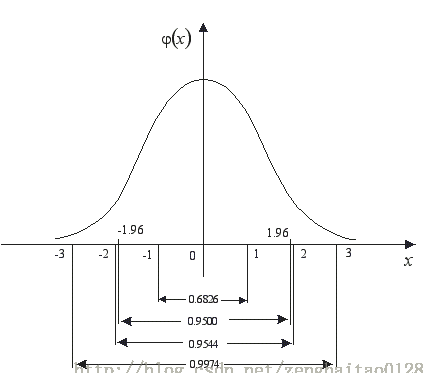
标准正态分布曲线下面积分布规律是:
在-1.96~+1.96范围内曲线下的面积等于0.9500(即取值在这个范围的概率为95%),在-2.58~+2.58范围内曲线下面积为0.9900(即取值在这个范围的概率为99%).
因此,由 np.random.randn()函数所产生的随机样本基本上取值主要在-1.96~+1.96之间,当然也不排除存在较大值的情形,只是概率较小而已。
用例:

统计学习方法 | 第1章 统计学习方法概论 | np.random.rand()函数的更多相关文章
- 统计学习方法 | 第1章 统计学习方法概论 | Scipy中的Leastsq()
Scipy是一个用于数学.科学.工程领域的常用软件包,可以处理插值.积分.优化.图像处理.常微分方程数值解的求解.信号处理等问题.它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解 ...
- 统计学习方法 | 第1章 统计学习方法概论 | numpy.linspace()
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) 在指定的间隔内返回均匀间隔的数字. 返回nu ...
- 部分具有统计功能的TSQL语句(例如DBCC语句,全局函数,系统存储过程)
部分具有统计功能的TSQL语句(例如DBCC语句,全局函数,系统存储过程) 这些功能也能帮助用户了解和监控SQLSERVER的运行情况 DBCC语句,DBCC语句是SQL2005的数据库控制台命令 D ...
- 全废话SQL Server统计信息(2)——统计信息基础
接上文:http://blog.csdn.net/dba_huangzj/article/details/52835958 我想在大地上画满窗子,让所有习惯黑暗的眼睛都习惯光明--顾城<我是一个 ...
- 全废话SQL Server统计信息(1)——统计信息简介
当心空无一物,它便无边无涯.树在.山在.大地在.岁月在.我在.你还要怎样更好的世界?--张晓风<我在> 为什么要写这个内容? 随着工作经历的积累,越来越感觉到,大量的关系型数据库的性能问题 ...
- 先序遍历创建二叉树,对二叉树统计叶子节点个数和统计深度(创建二叉树时#代表空树,序列不能有误)c语言
#include "stdio.h" #include "string.h" #include "malloc.h" #define NUL ...
- 统计学习方法 | 第3章 k邻近法
第3章 k近邻法 1.近邻法是基本且简单的分类与回归方法.近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例 ...
- 统计学习方法 | 第3章 k邻近法 | 补充
namedtuple 不必再通过索引值进行访问,你可以把它看做一个字典通过名字进行访问,只不过其中的值是不能改变的. sorted()适用于任何可迭代容器,list.sort()仅支持list(本身就 ...
- 统计学习方法——第四章朴素贝叶斯及c++实现
1.名词解释 贝叶斯定理,自己看书,没啥说的,翻译成人话就是,条件A下的bi出现的概率等于A和bi一起出现的概率除以A出现的概率. 记忆方式就是变后验概率为先验概率,或者说,将条件与结果转换. 先验概 ...
随机推荐
- HDU 6050 - Funny Function | 2017 Multi-University Training Contest 2
/* HDU 6050 - Funny Function [ 公式推导,矩阵快速幂 ] 题意: F(1,1) = F(1, 2) = 1 F(1,i) = F(1, i-1) + 2 * F(1, i ...
- Centos7搭建CDH6.0.1(单机版)
一.前言. 学习大数据组件,最好的方式是直接参照官网.不过官网的教程也让我吃了一坑,在此记录一下.因在个人笔记本资源有限,在此安装为单机版安装 二.搭建. 1.1配置主机名 hostnamectl s ...
- (转载)Google 发布 Android 性能优化典范
2015年伊始,Google发布了关于Android性能优化典范的专题, 一共16个短视频,每个3-5分钟,帮助开发者创建更快更优秀的Android App.课程专题不仅仅介绍了Android系统中 ...
- MessagePack Java Jackson Dataformat - Map 的序列化和反序列化
本测试方法,可以在 https://github.com/cwiki-us-demo/serialize-deserialize-demo-java/blob/master/src/test/java ...
- Codevs 1017 乘积最大 2000年NOIP全国联赛普及组NOIP全国联赛提高组
1017 乘积最大 2000年NOIP全国联赛普及组NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 今年是国 ...
- 浅淡数据仓库(二)星型模式与OLAP多维数据库
在关系数据库管理系统中实现的维度模型称为星型模型模式,因为其结构类似星型结构.在多为数据库环境中实现的维度模型通常称为联机分析处理(OLAP)多维数据库
- iPhone/iPad调整事件递交
UIKit 为应用程序提供了编程手段来简化事件处理或者完全关闭事件流.下面的列表总结了这些方法: 关闭触摸事件的递交. 缺省情况下,视图接收触摸事件,但是你可以设置它的userInteractionE ...
- 快速理解arguments对象
在js中一切都是对象,连函数也是对象,函数名其实是引用函数定义对象的变量. 1.什么是arguments? 这个函数体内的arguments非常特殊,实际上是所在函数的一个内置类数组对象,可以用数组的 ...
- [转]基于java的程序OutOfMemory问题的解决及Xms/Xmx/Xss的解释和应用
长期以来一直都是做java应用的开发,所使用的开发工具基本上也都是基于java的,经常用的有eclipse, netbeans, ant, maven, cruisecontrol, tomcat, ...
- 石川es6课程---9、面向对象-基础
石川es6课程---9.面向对象-基础 一.总结 一句话总结: js老版本的面向对象和继承都不是很方便,新版的面向对象向其它语言靠拢,有了class,extends,constructor等关键字,用 ...