最大熵马尔科夫模型(MEMM)及其标签偏置问题
定义:
MEMM是这样的一个概率模型,即在给定的观察状态和前一状态的条件下,出现当前状态的概率。
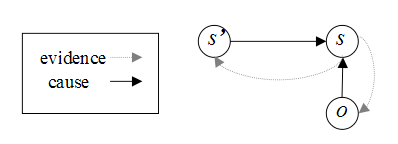
Ø S表示状态的有限集合
Ø O表示观察序列集合
Ø Pr(s|s’,o):观察和状态转移概率矩阵
Ø 初始状态分布:Pr0(s)
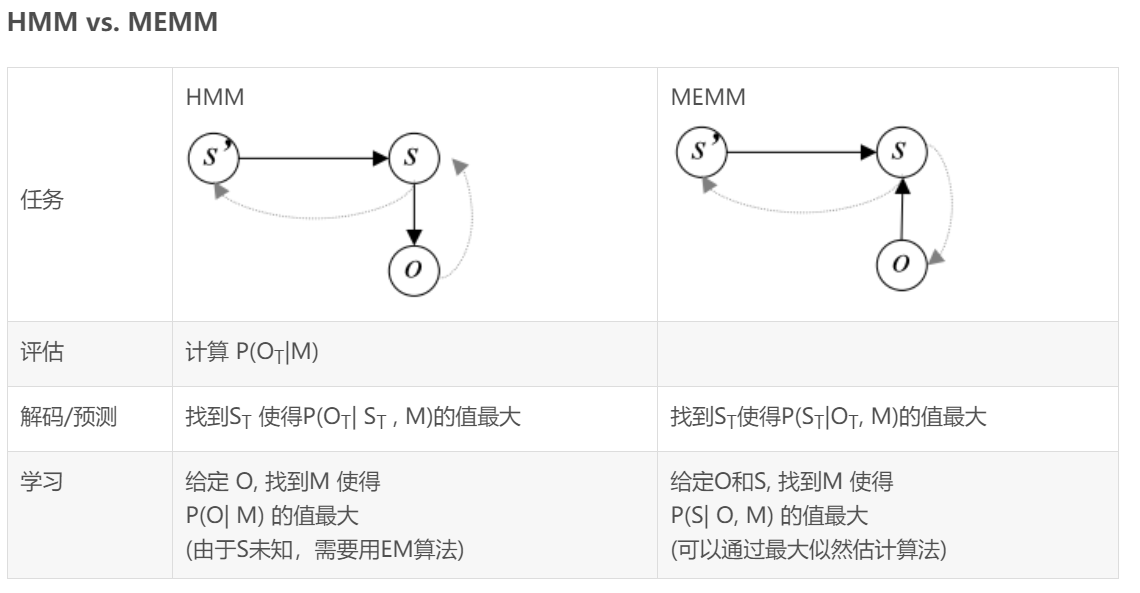
注:O表示观察集合,S表示状态集合,M表示模型
最大熵马尔科夫模型(MEMM)的缺点:
看下图,由观察状态O和隐藏状态S找到最有可能的S序列:
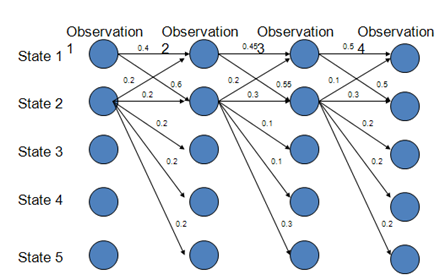
路径s1-s1-s1-s1的概率:0.4*0.45*0.5=0.09
路径s2-s2-s2-s2的概率: 0.2*0.3*0.3=0.018
路径s1-s2-s1-s2的概率: 0.6*0.2*0.5=0.06
路径s1-s1-s2-s2的概率: 0.4*0.55*0.3=0.066
由此可得最优路径为s1-s1-s1-s1

实际上,在上图中,状态1偏向于转移到状态2,而状态2总倾向于停留在状态2,这就是所谓的标注偏置问题,由于分支数不同,概率的分布不均衡,导致状态的转移存在不公平的情况。
由上面的两幅图可知,最大熵隐马尔科夫模型(MEMM)只能达到局部最优解,而不能达到全局最优解,因此MEMM虽然解决了HMM输出独立性假设的问题,但却存在标注偏置问题。
最大熵马尔科夫模型(MEMM)及其标签偏置问题的更多相关文章
- 标记偏置 隐马尔科夫 最大熵马尔科夫 HMM MEMM
隐马尔科夫模型(HMM): 图1. 隐马尔科夫模型 隐马尔科夫模型的缺点: 1.HMM仅仅依赖于每个状态和它相应的观察对象: 序列标注问题不仅和单个词相关,并且和观察序列的长度,单词的上下文,等等相关 ...
- 【中文分词】最大熵马尔可夫模型MEMM
Xue & Shen '2003 [2]用两种序列标注模型--MEMM (Maximum Entropy Markov Model)与CRF (Conditional Random Field ...
- 隐马尔科夫模型python实现简单拼音输入法
在网上看到一篇关于隐马尔科夫模型的介绍,觉得简直不能再神奇,又在网上找到大神的一篇关于如何用隐马尔可夫模型实现中文拼音输入的博客,无奈大神没给可以运行的代码,只能纯手动网上找到了结巴分词的词库,根据此 ...
- HMM基本原理及其实现(隐马尔科夫模型)
HMM(隐马尔科夫模型)基本原理及其实现 HMM基本原理 Markov链:如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程.马尔可夫链是时间和状态 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- HMM 自学教程(四)隐马尔科夫模型
本系列文章摘自 52nlp(我爱自然语言处理: http://www.52nlp.cn/),原文链接在 HMM 学习最佳范例,这是针对 国外网站上一个 HMM 教程 的翻译,作者功底很深,翻译得很精彩 ...
- HMM隐马尔科夫模型
这是一个非常重要的模型,凡是学统计学.机器学习.数据挖掘的人都应该彻底搞懂. python包: hmmlearn 0.2.0 https://github.com/hmmlearn/hmmlearn ...
- 隐马尔科夫模型(HMM)的概念
定义隐马尔科夫模型可以用一个三元组(π,A,B)来定义:π 表示初始状态概率的向量A =(aij)(隐藏状态的)转移矩阵 P(Xit|Xj(t-1)) t-1时刻是j而t时刻是i的概率B =(bij) ...
随机推荐
- 【51nod 1847】奇怪的数学题
题目描述 给出 N,K ,请计算下面这个式子: \(∑_{i=1}^N∑_{j=1}^Nsgcd(i,j)^k\) 其中,sgcd(i, j)表示(i, j)的所有公约数中第二大的,特殊地,如果gcd ...
- Logitech G系鼠标脚本编程,实现鼠标自动定位控制
利用罗技官方提供的API来写一个鼠标自动定位移动脚本 点击脚本编辑器中的帮助选项,查看罗技官方提供的API说明,有很多实现好的鼠标功能 G-series Lua API V8.45 Overview ...
- No server 没有服务器
先本地下载tomcat 参考 https://www.cnblogs.com/limn/p/9358657.html 下载后参考 https://jingyan.baidu.com/article/3 ...
- Flash上传超大文件解决方案
文件夹数据库处理逻辑 public class DbFolder { JSONObject root; public DbFolder() { this.root = new JSONObject() ...
- python-numpy-1
mean() mean() 函数定义: numpy.``mean(a, axis=None, dtype=None, out=None, keepdims=<class numpy._globa ...
- 搞清楚MySQL事务隔离级别
首先创建一个表 account.创建表的过程略过(由于 InnoDB 存储引擎支持事务,所以将表的存储引擎设置为 InnoDB).表的结构如下: 然后往表中插入两条数据,插入后结果如下: 为了说明问题 ...
- Centos7 yum install chrome
一.配置 yun 源 vim /etc/yum.repos.d/google-chrome.repo [google-chrome] name=google-chrome baseurl=http:/ ...
- kvm虚拟机操作相关命令及虚拟机和镜像密码修改
虚拟机生命周期管理 1)查看kvm虚拟机状态 #virsh list --all 2)KVM虚拟机开机 # virsh start oeltest01 3)KVM虚拟机关机或断电 关机 默认情况下vi ...
- UDP打洞原理介绍
NAT穿越模块的设计与实现 Internet的快速发展以及IPv4地址数量的不足使得NAT设备得到了大规模的应用,然而这也给越来越多的端到端通信也带来了不少的麻烦.一般来说,NAT设备允许内网内主机 ...
- Appium移动自动化测试(四)之元素定位
做过UI自动化测试的童鞋都会发现, 在上一篇文章中居然没有万能定位方式Xpath. 是滴, 确实没有! ADT自带的uiautomatorviewer里面并没有属性xpath, 如果我们需要的话,还需 ...