spark 机器学习 knn原理(一)
1.knn
K最近邻(k-Nearest Neighbor,KNN)分类算法,在给定一个已经做好分类的数据集之后,k近邻可以学习其中的分类信息,并可以自动地给未来没有分类的数据分好类。
我们可以把用户分为两类:“高信誉用户”和“低信誉用户”,酒店则可以分为:“五星”,“四星”,“三星”,“两星”,“一星”。
这些可以使用线性回归做分类吗?
答案:能做,但不建议使用,线性模型的输出值是连续性的实数值,而分类模型的任务要求是得到分类型的模型输出结果。从这一点上看,线性模型不适合用于分类问题。
我们换一个思路,这里用“阈值”概念,也就是将连续性数值离散化,比如信誉预测中,我们可以把阈值定为700,高于700的为高信誉用户,低于700的为低信誉用户,这里我们把连续性变量转换成一个“二元变量”,当然也可以使用更多“阈值”,比如可以分为,低信誉,中等信誉,高信誉。
###############################################################
回归与分类的不同
1.回归问题的应用场景(预测的结果是连续的,例如预测明天的温度,23,24,25度)
回归问题通常是用来预测一个值,如预测房价、未来的天气情况等等,例如一个产品的实际价格为500元,通过回归分析预测值为499元,我们认为这是一个比较好的回归分析。一个比较常见的回归算法是线性回归算法(LR)。另外,回归分析用在神经网络上,其最上层是不需要加上softmax函数的,而是直接对前一层累加即可。回归是对真实值的一种逼近预测。
2.分类问题的应用场景(预测的结果是离散的,例如预测明天天气-阴,晴,雨)
分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一幅图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上,分类的最后一层通常要使用softmax函数进行判断其所属类别。分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。最常见的分类方法是逻辑回归,或者叫逻辑分类。
############################################################
如下图所示,我们想要知道绿色点要被决定赋予哪个类,是红色三角形还是蓝色正方形?我们利用KNN思想,如果假设K=3,选取三个距离最近的类别点,由于红色三角形所占比例为2/3,因此绿色点被赋予红色三角形类别。如果假设K=5,由于蓝色正方形所占比例为3/5,因此绿色点被赋予蓝色正方形类别。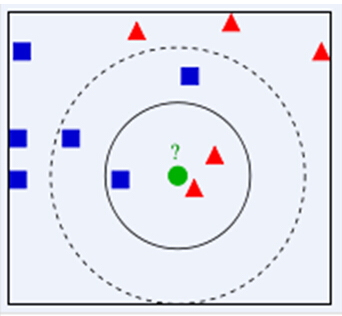
从上面实例,我们可以总结下KNN算法过程
1.1. 计算测试数据与各个训练数据之间的距离。
1.2. 按照距离的递增关系进行排序,选取距离最小的K个点。
1.3. 确定前K个点所在类别的出现频率,返回前K个点中出现频率最高的类别作为测试数据的预测分类。
从KNN算法流程中,我们也能够看出KNN算法三个重要特征,即距离度量方式、K值的选取和分类决策规则。
1.1距离:
KNN算法常用欧式距离度量方式,当然我们也可以采用其他距离度量方式,如曼哈顿距离
欧氏距离是最容易直观理解的距离度量方法,两个点在空间中的距离一般都是指欧氏距离。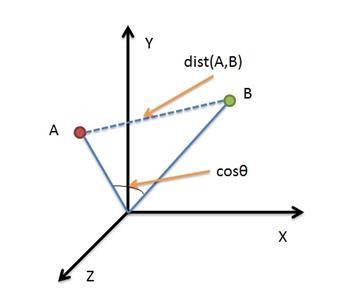
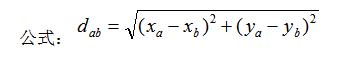
1.2 K值的选取: KNN算法决策结果很大程度上取决于K值的选择。选择较小的K值相当于用较小领域中的训练实例进行预测,训练误差会减小,但同时整体模型变得复杂,容易过拟合。选择较大的K值相当于用较大领域中训练实例进行预测,可以减小泛化误差,但同时整体模型变得简单,预测误差会增大。
1.3 分类决策规则:k值中对象们“投票”,哪类对象“投票”数多就属于哪类,如果“投票”数一样多,那么随机抽选出一个类。
2.1knn KD树
我们举例来说明KD树构建过程,假如有二维样本6个,分别为{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},KD树过程构建过程如下
2.1.1寻找划分特征: 6个数据点在x,y维度上方差分别为6.97,5.37,x轴上方差更大,用x轴特征建树。
######################################################

方差或表达为:
######################################################
2.1.2Node-data = (7,2)。具体是:根据x维上的值将数据排序,6个数据的中值(所谓 中值,即中间大小的值)为7,所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7
2.1.3左子空间和右子空间。具体是:分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
2.1.4递归构建KD树:用同样的方法划分左子树{(2,3),(5,4),(4,7)}和右子树{(9,6),(8,1)},最终得到KD树。
如左子树{(2,3),(5,4),(4,7)} x轴方差 2.3,y轴方差4.3,所有使用y轴进行分割
重复上面2.1,2.2,2.3 步骤 ,中值为5.4

首先,粗黑线将空间一分为二,然后在两个子空间中,细黑直线又将整个空间划分为四部分,最后虚黑直线将这四部分进一步划分。
2.2 KD树搜索最近邻
当我们生成KD树后,就可以预测测试样本集里面的样本目标点。
1 二叉搜索:对于目标点,通过二叉搜索,能够很快在KD树里面找到包含目标点的叶子节点。
2回溯:为找到最近邻,还需要进行回溯操作,算法沿搜索路径反向查找是否有距离查询点更近的数据点。以目标点为圆心,目标点到叶子节点的距离为半径,得到一个超球体,最邻近点一定在这个超球体内部。
3更新最近邻:返回叶子节点的父节点,检查另一叶子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点中寻找是否有更近的最近邻,有的话就更新最近邻。如果不相交就直接返回父节点的父节点,在另一子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。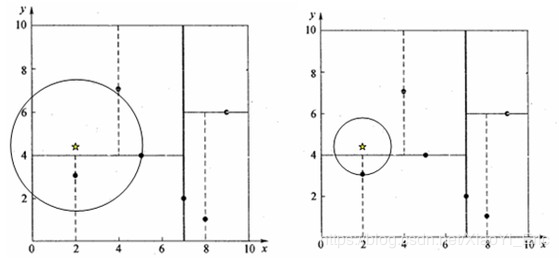
2.3KD树预测
根据KD树搜索最近邻的方法,我们能够得到第一个最近邻数据点,然后把它置为已选。然后忽略置为已选的样本,重新选择最近邻,这样运行K次,就能得到K个最近邻。如果是KNN分类,根据多数表决法,预测结果为K个最近邻类别中有最多类别数的类别。如果是KNN回归,根据平均法,预测结果为K个最近邻样本输出的平均值。
spark 机器学习 knn原理(一)的更多相关文章
- spark 机器学习 knn 代码实现(二)
通过knn 算法规则,计算出s2表中的员工所属的类别原始数据:某公司工资表 s1(训练数据)格式:员工ID,员工类别,工作年限,月薪(K为单位) 101 a类 8年 ...
- spark 机器学习 ALS原理(一)
1.线性回归模型线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归.当你使用它时,你首先假设输出变量(相应变量.因变量.标签)和预测变量(自变量.解释变量.特征)之间存 ...
- spark 机器学习 决策树 原理(一)
1.什么是决策树 决策树(decision tree)是一个树结构(可以是二叉树或者非二叉树).决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树. 其中每个非叶节点表示 ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark机器学习解析下集
上次我们讲过<Spark机器学习(上)>,本文是Spark机器学习的下部分,请点击回顾上部分,再更好地理解本文. 1.机器学习的常见算法 常见的机器学习算法有:l 构造条件概率:回归分 ...
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- PAT 甲级 1146 Topological Order (25 分)(拓扑较简单,保存入度数和出度的节点即可)
1146 Topological Order (25 分) This is a problem given in the Graduate Entrance Exam in 2018: Which ...
- Delphi 调用控件的过程,初学者都想知道
假设有过程: procedure TForm1.Button1Click(Sender: TObject);begin ShowMessage('唐细刚 2008');end; 想在 FormC ...
- 【计算机视觉】OpenCV篇(4) - Pycharm+PyQt5+Python小项目实战
1.下载安装 (1)Pycharm:下载链接 (2)推荐使用Qt Designer来设计界面,如果你装的是Anaconda的话,就已经自带了designer.exe,我这里使用的是Pycharm的虚拟 ...
- 分类:logistic回归
import numpy as np import matplotlib.pyplot as plt x=np.linspace(-1,1,200) y=1/(1+np.exp(10*x-1)) pl ...
- linux中查看端口号
linux中查看端口号 yum install lsof -y [root@test1 ~]# lsof -i :80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF ...
- 测试框架nunit之assertion断言使用详解
任何xUnit工具都使用断言进行条件的判断,NUnit自然也不例外,与其它的xUnit(如Junit.phpUnit.pythonUnit)相比,由于大量使用了Generic.Attribute等语言 ...
- SpringBoot RequestBody ajax提交对象
前端实现: var student = { "name":1, "age":2, "score":3 }; $.ajax({ url:&qu ...
- 客户端连接Codis集群
新建maven webapp项目 添加相关依赖: <dependency> <groupId>redis.clients</groupId> <artifac ...
- ROS中的通信机制
http://www.ros.org/core-components/ Communications Infrastructure At the lowest level, ROS offers a ...
- 《ucore lab4》实验报告
资源 ucore在线实验指导书 我的ucore实验代码 练习1:分配并初始化一个进程控制块 题目 alloc_proc函数(位于kern/process/proc.c中) 负责分配并返回一个新的str ...