python操作hive 安装和测试
方法一:使用pyhive库
如上图所示我们需要四个外部包
中间遇到很多报错。我都一一解决了
1.Connection Issue: thrift.transport.TTransport.TTransportException: TSocket read 0 bytes
2.安装sasl 遇到Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools"
解决了 点击
3.遇到
thrift.transport.TTransport.TTransportException: Could not start SASL: b'Error in sasl_client_start (-4) SASL(-4): no mechanism available: Unable to find a callback: 2'
处理
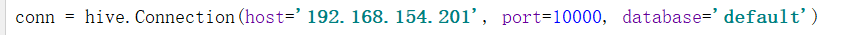
加上 auth="NOSAL"这个参数
4.我发现上面这个包有的安装不了 我强行用pycharm alt+enter强行按安装的
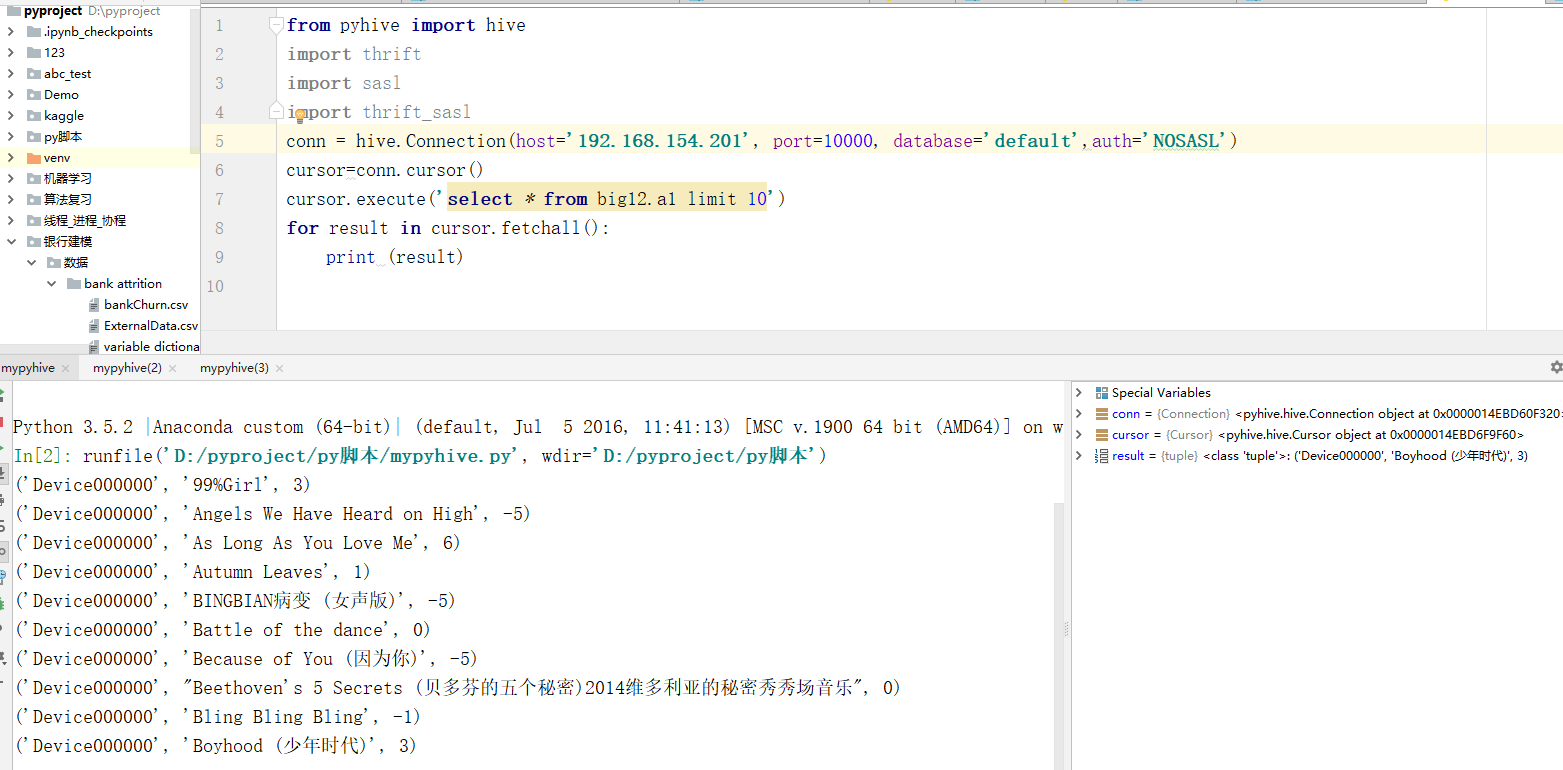
最后附上测试代码
from pyhive import hive
import thrift
import sasl
import thrift_sasl
conn = hive.Connection(host='192.168.154.201', port=10000, database='default',auth='NOSASL')
cursor=conn.cursor()
cursor.execute('select * from a1 limit 10')
for result in cursor.fetchall():
print (result)
方法二:使用impyla库
pip install thrift-sasl==0.2.
pip install sasl
pip install impyla
测试代码如下:
from impala.dbapi import connect
conn = connect(host='192.168.154.201', port=10000, database='default')
cursor = conn.cursor()
cursor.execute('select * from a1 limit 10')
for result in cursor.fetchall():
print(result)
方法三:使用ibis库
# # 1.查询hdfs数据
from ibis import hdfs_connect
hdfs = hdfs_connect(host='xxx.xxx.xxx.xxx', port=50070)
hdfs.ls('/')
hdfs.ls('/apps/hive/warehouse/ai.db/tmp_ys_sku_season_tag')
hdfs.get('/apps/hive/warehouse/ai.db/tmp_ys_sku_season_tag/000000_0', 'parquet_dir')
# 2.查询数据到python dataframe
from ibis.impala.api import connect ImpalaClient = connect('192.168.154.201',10000,database='default')
lists=ImpalaClient.list_databases()
print(lists)
isExist=ImpalaClient.exists_table('a1') # # 执行SQL
# if(isExist):
# sql='set mapreduce.job.queuename=A'
# ImpalaClient.raw_sql(sql) # 将SQL结果导出到python dataframe
requete = ImpalaClient.sql('select * from a1 limit 10')
df = requete.execute(limit=None)
print(type(df))
print(df)
结果:

官网API:https://docs.ibis-project.org/api.html#impala-client
变成df确实能用pandas和numpy两个包能做很多事情
python操作hive 安装和测试的更多相关文章
- python操作Redis安装、支持存储类型、普通连接、连接池
一.python操作redis安装和支持存储类型 安装redis模块 pip3 install redis 二.Python操作Redis之普通连接 redis-py提供两个类Redis和Strict ...
- Linux 首先基本包安装(vim啊什么的),源,源优化,项目架构介绍, (LNMuWsgi)Django项目相关软件mysql,redies,python(相关模块)安装配置测试
内容 补充: 查看已启动服务的端口 netstat -tulnp |grep (方式1) ss -tulnp|grep (方式2) 前期铺垫: . Linux要能上网 . 掌握Linux软件包安装方法 ...
- python操作数据库-安装
首先是下载软件: 链接:http://pan.baidu.com/s/1nvp1imX 密码:6i0x 之后就是一系列设置. 安装教程:自行百度就行.需要注意的是设置my.ini时,需要加上这些东西( ...
- python操作hive并且获取查询结果scheam
执行hive -e 命令并且获取对应的select查询出来的值及其对应的scheam字段 需要在执行语句中前部添加 set hive.cli.print.header=true; 这个设置,如下语句: ...
- python3 操作 hive 安装依赖包整理
安装依赖pip install saslpip install thriftpip install thrift-saslpip install PyHive windows安装sasl报错,解决方案 ...
- Python操作Redis、Memcache、RabbitMQ、SQLAlchemy
Python操作 Redis.Memcache.RabbitMQ.SQLAlchemy redis介绍:redis是一个开源的,先进的KEY-VALUE存储,它通常被称为数据结构服务器,因为键可以包含 ...
- Python之路【第十篇】Python操作Memcache、Redis、RabbitMQ、SQLAlchemy、
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- 文成小盆友python-num11-(2) python操作Memcache Redis
本部分主要内容: python操作memcache python操作redis 一.python 操作 memcache memcache是一套分布式的高速缓存系统,由LiveJournal的Brad ...
- 使用python操作Memcache、Redis、RabbitMQ、
Memcache 简述: Memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的.需要 ...
随机推荐
- 基于JAVA Socket的底层原理分析及工具实现
前言 在工作开始之前,我们先来了解一下Socket 所谓Socket,又被称作套接字,它是一个抽象层,简单来说就是存在于不同平台(os)的公共接口.学过网络的同学可以把它理解为基于传输TCP/IP协议 ...
- Web 开发和数据科学家仍是 Python 开发的两大主力
由于 Python 2 即将退役,使用 Python 3 的开发者大约为 90%,Python 2 的使用量正在迅速减少.而去年仍有 1/4 的人使用 Python 2. Web 开发和数据科学家仍是 ...
- 高性能MySQL3_笔记1_Mysql的架构与历史
第一层:连接处理.授权认证.安全 第二层:mysql的核心功能,包括查询解析.分析.优化.缓存以及所有的内置函数(例如日期.加密.数学函数), 所有跨存储引擎的功能都在这一层实现:存储过程.触发器.视 ...
- c#调用带用户名密码验证的wsdl
之前记录过一篇添加带验证的webservice,但是公司的另一个项目是.net framework2.0的项目,没有服务引用,只能添加web引用. 现在记录和分享一下方法: 先添加web引用,选择ws ...
- shiro学习(三,shiro加密)
shiro加密 使用MD5加密 认证 //自定义的Realm 域 public class CustomRealmSecret extends AuthorizingRealm { @Overrid ...
- Spark 源码和应用开发环境的构建
引言 Spark 现在无疑是大数据领域最热门的技术之一,读者很容易搜索到介绍如何应用 Spark 技术的文章,但是作为开发人员,在了解了应用的概念之后,更习惯的是打开开发环境,开发一些应用来更深入的学 ...
- npm安装淘宝镜像cnpm
在cmd中执行 npm install -g cnpm --registry=https://registry.npm.taobao.org
- 如何将webstrom本地的代码上传到github上
首先注册一个github账户,然后下载一个git软件. 文件夹的任意处点击右键,找到gitbash here,打开终端命令窗口. 因为我们本地 Git 仓库和 GitHub 仓库之间的传输是通过 S ...
- vue的使用与安装 npm -v报错
1.先将node从官方文档下载下来,然后进行安装. 安装成功后,在dos命令中node -v.npm -v来测试,如果成功就可以安装cnpm(国内淘宝镜像比较快).这里我遇到一个bug,npm -v压 ...
- 3 java 笔记
1 垃圾回收机制能够很好地提高编程效率 2 垃圾回机制保护程序的完成性 3 面向对象的三种基本特征:继承,封装,多态 4 面向对象的方式:OOA(面向对象的分析),OOD(面向对象的设计)和OOP(面 ...