pyquery:轻松、灵活的处理html
楔子
下面我们来学习一下RabbitMQ,RabbitMQ是一款消息队列。至于什么是消息队列,以及为什么要有消息队列,这一类老生常谈的问题我们就不说了。而现在有那么多消息队列,为什么要选择RabbitMQ呢?因为笔者所在公司用的就是RabbitMQ,所以没有为什么。
初始RabbitMQ
RabbitMQ是一个开源的的消息队列和代理服务器,通过普通协议在完全不同的应用之间共享数据。并且RabbitMQ是使用Erlang语言编写,基于AMQP协议。
上面是RabbitMQ的介绍,我们来解释一下
RabbitMQ是开源的RabbitMQ跟语言无关,python可以像里面发送消息、接收消息,golang也可以发送消息、接收消息。RabbitMQ是用Erlang编写,Erlang语言最初用于交换机领域的架构模式,它有着和原生socket一样的延迟。因此这意味着RabbitMQ的性能是非常优秀的基于AMQP协议。AMQP: Advanced Message Queuing Protocl,即:高级消息队列协议。它是具有现代特征的二进制协议,是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
AMQP核心概念
RabbitMQ是基于AMQP协议的,所以我们有必要了解一下AMQP的一些核心概念。这些概念可能一开始会让人有些懵,但是不要紧,现在先有一个印象,我们后续会慢慢介绍,包括RabbitMQ的架构。
1. Server:又称之为Broker,主要接收客户端的连接,实现AMQP的实体服务。
2. Connection:连接,客户端与Broker的网络连接
3. Channel:网络信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道。客户端可以建立多个Channel,每个Channel代表一个会话任务。
4. Message:消息,服务器和客户端之间如果想传送数据,那么首先要将数据包装成消息,才能发送。消息由Body和Properties组成,前者是消息体内容,后者则是对消息进行修饰,比如消息的优先级、延迟等高级特性。
5. Virtual host:虚拟地址,用于进行逻辑隔离,最上层的消息路由。一个Virtual host里面可以有若干个Exchange和Queue,但是同一个Virtual host里面不能相同名称的Exchange或Queue。为什么要有虚拟地址这么一个概念呢?主要是为了对服务进行划分,比如有多个应用服务在开发,那么A服务就把消息路由到虚拟地址等于/A的主机上,B服务可以把消息都路由到虚拟地址等于/B的主机上,更具有层次感。
6. Exchange:交换机,接收消息,根据路由键转发消息到绑定的队列。所以消息并不是直接进入到队列里面,而是要先进入到Exchange、也就是交换机中,然后再根据路由键,被转发到与Exchange绑定的队列中。
7. Binding:Exchange和Queue之间的虚拟连接,我们说过交换机和队列之间是要进行绑定的,这个绑定的连接就是Binding,Binding中可以包含Binding key、用来和路由键匹配的
8. Routing key:路由键、一个路由规则,虚拟机可以用它来确定如何路由一个特定消息。
9. Queue:队列,或者消息队列,保存生产者发送的消息,转发给消费者、或者消费者主动获取。
RabbitMQ整体架构
我们用一张图来看看RabbitMQ的整体架构是什么样子的,然后再次解释一下上面的概念

左边的是生产者、生产消息,右边的是消费者、消费消息,这很好理解,而中间的部分则是RabbitMQ的服务端,或者说broker。
然后我们解释一下中间RabbitMQ服务的结构
Queue:
队列,RabbitMQ的作用是存储消息,那么自然要有队列来进行存储。队列的特点是先进先出,因此可以看出clientA和clientB是生产者,生产者生产消息送到rabbitmq的内部对象Queue里面去,而client1、2、3可以看成是消费者,消费者则是从队列中取出数据,可以简化为:

生产者Send Message "A"送到Queue中,消费者发现消息队列Queue中有订阅的消息,就会将这条消息A读取出来进行一系列的业务操作,这里是一个消费者对应一个队列Queue,也可以是多个消费者订阅同一个队列Queue,当然多个消费者的话,就会将Queue里面的消息平分给其他的消费者,但这样会存在一个问题。每个消息的处理时间不同的话,就会有消费者一直处于忙碌之中,而有的消费者处理完之后会处于空闲之中。因为前面提到了,如果一个消费者对应一个队列Queue的话,很好理解。但是多个消费者对应一个队列Queue的话,就会将Queue里面的消息均摊给相应的的消费者,但消费者所在机器的性能不同就会造成资源的浪费。因此我们就可以使用prefetchCount来限制每次发送给消费者信息的的个数
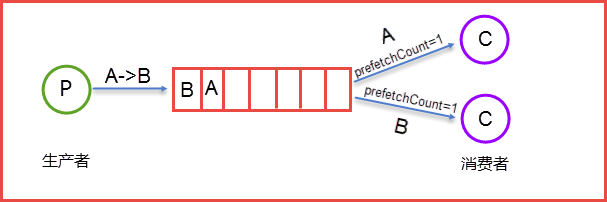
这里的prefetchCount=1是指每次从Queue中发送一条消息。等消费者处理完这条消息后Queue会再发送一条消息给消费者,这样可以保证谁处理的块,就会处理的多,可以保证负载均衡。
Exchange:
我们在介绍AMQP协议的时候说了生产者最终是将消息发送到Queue当中,但不是直接发送的,而是中间经过了一层Exchange,那么这个Exchange是干什么的呢?首先我们可以思考一下,这个RabbitMQ里面只能有一个Queue吗?显然不是,可以有多个Queue,那生产者send message的时候,要往哪一个Queue里面send呢。所以这个时候Exchange就出现了,可Exchange又是怎样将消息准确地推送到对应的Queue里面呢?

从图中我们看到,主要依赖于Binding,RabbitMQ是通过Binding将Exchange和Queue绑定在一起,并且在绑定Exchange和Queue的同时,会指定一个Binding key,生产者将消息发送到Exchange的时候,会产生一个Routing key,当Binding key和Routing key对应上之后消息就会发送到相应的Queue中去。所以我们可以将消息,不直接发到Queue当中;而是会发到Exchange中,然后对消息进行过滤,再有Exchange选择将消息发送到Binding key和Routing key相匹配的Queue中。
而Exchange有四种类型,不同的类型有着不同的策略。也就是生产者发送了一条消息,Routing key的规则是A,就会将Routing key=A的消息发送到Exchange中,这时候Exchange中有自己的规则,会按照对应的规则去筛选生产者发送的消息,如果能对应上Exchange的内部规则,那么Exchange就会将消息推送到与自己绑定的Queue当中去。因此,生产者往Exchange里面send消息,会产生一个Routing key,Exchange和Queue绑定的时候会有一个Binding key,只要两者符合,那么就会将生产者send过来的消息放到对应的Queue当中。但是刚才也说了,Exchange有着不同的类型(也就是RabbitMQ架构图中的Exchange Types),不同类型的Exchange会有着不同的策略,这也就决定了消息所推送到的Queue会不一样,那么Exchange都有哪些类型呢?
Exchange Types:
1. fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
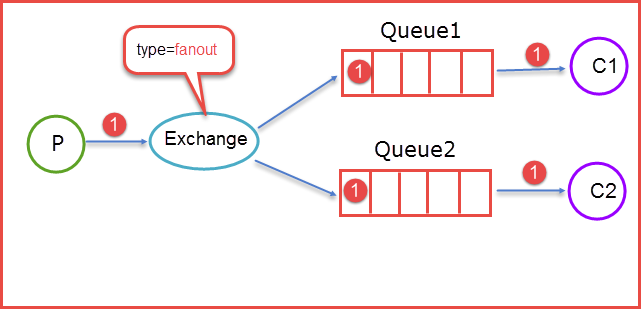
上图所示,生产者(P)生产消息1,并将消息1推送到Exchange,由于Exchange Type=fanout这时候会遵循fanout的规则将消息推送到所有与它绑定Queue,也就是图上的两个Queue最后两个消费者消费。
2. direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中
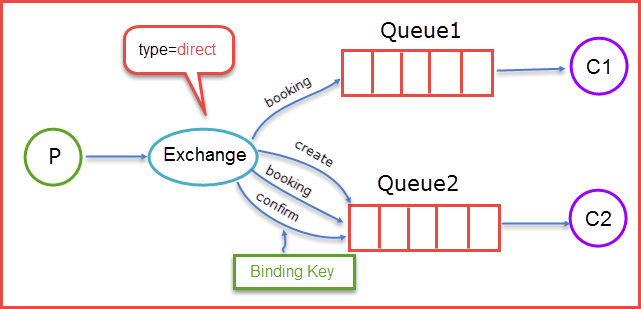
当生产者(P)发送Rotuing key=booking的消息时,这时候将消息传送给Exchange,Exchange获取到生产者发送过来消息后,会根据自身的规则进行与匹配相应的Queue,这时发现Queue1和Queue2都符合,就会将消息传送给这两个队列,如果我们以Rotuing key=create和Rotuing key=confirm发送消息时,这时消息只会被推送到Queue2队列中
3. topic
前面提到的direct规则是严格意义上的匹配,换言之Routing Key必须与Binding Key相匹配的时候才将消息传送给Queue,那么topic这个规则就是模糊匹配,可以通过通配符满足一部分规则就可以传送。它的约定是:
1. routing key为一个句点号"."分隔的字符串(我们将被句点号"."分隔开的每一段独立的字符串称为一个单词),如"stock.usd.nyse"、"nyse.vmw"、"quick.orange.rabbit"2. binding key与routing key一样也是句点号"."分隔的字符串3. binding key中可以存在两种特殊字符"*"与"#",用于做模糊匹配,其中"*"用于匹配一个单词,"#"用于匹配多个单词(可以是零个)

当生产者发送消息Routing Key=F.C.E的时候,这时候只满足Queue1,所以会被路由到Queue中;如果Routing Key=A.C.E时,那么都满足,所以会被同时路由到Queue1和Queue2中;如果Routing Key=A.F.B时,这里只会发送一条消息到Queue2中。
4. headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
RabbitMQ的安装与使用
下面我们来安装一下RabbitMQ,这里我们只演示如何在Linux系统上安装,Windows上不介绍,因为消息队列啥的基本上不会用在Windows上。
1. 我们说RabbitMQ是Erlang语言编写的,那么肯定要安装Erlang语言,这就跟使用Hadoop要先安装jdk一样。安装命名为:yum install erlang,非常简单

安装结束之后,输入erl,如果显示如上内容,说明安装成功
2. 安装RabbitMQ,也非常简单,直接yum install rabbitmq-server即可。
然后控制台输入rabbitmqctl status
如果显示如上内容,说明安装成功
然后关于RabbitMQ的启动、停止我们可以使用如下命令。
启动rabbitmq:systemctl rabbitmq-server start停止rabbitmq:systemctl rabbitmq-server stop重启rabbitmq:systemctl rabbitmq-server restart
然后我们就可以通过编程语言去连接了,我们后面会演示如何使用python连接RabbitMQ并进行消息的发送和接收,这里主要是说一下连接的端口是5672。也就是我们想要进行tcp通信的话,是通过端口5672进行通信的。
另外RabbitMQ也支持我们使用webUI的方式访问,但是webUI访问需要我们安装一个插件,安装也很简单,rabbitmq-plugins enable rabbitmq_management即可。然后就可以通过浏览器查看了,webUI访问的端口是15672,我们来看一下。

这里提示我们需要用户名和密码,那么我们可以创建一个,怎么创建呢?
1. 添加用户:rabbitmqctl add_user 用户名 密码2. 给用户管理员权限,rabbitmqctl set_user_tags 用户名 administrator3. 为用户设置权限: rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"
我这里已经创建完了,并赋予权限,然后我们用刚才创建的账号进行登录。
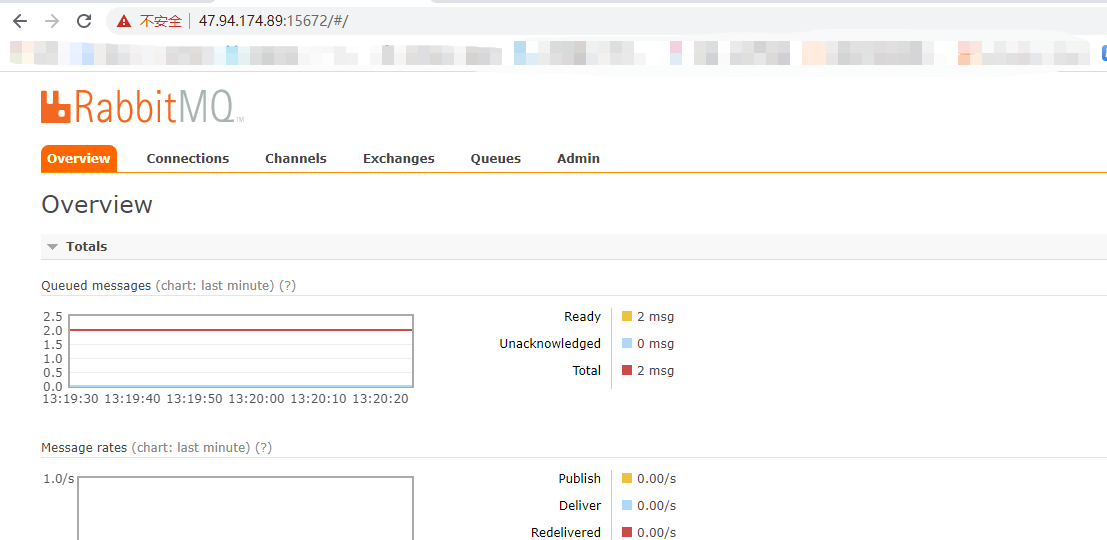
此时我们就进入了RabbitMQ的控制台页面,我之前已经用python发送了两条消息,并进行了接收。我们添加用户、删除用户、设置权限等等,也可以在webUI上进行操作。至于页面上显示的其它内容有兴趣可以自己去看,比较简单。
另外我们提到了端口号,RabbitMQ进行tcp通信的端口号是5672,webUI的端口号是15672,此外还有一个25672,是集群之间通信的端口号。
命令行相关操作
下面来介绍一下RabbitMQ的命令行操作,我们上面在介绍安装RabbitMQ的时候已经介绍了一些控制台的命令了,比如RabbitMQ的启动、停止、重启,以及添加用户、设置用户权限等等,下面我们再来整理一下,顺便再说一下其它的命令。
首先RabbitMQ的启动、停止我们使用的命令是systemctl,而RabbitMQ的内部操作我们使用的命令是rabbitmqctl
启动rabbitmq:systemctl rabbitmq-server start停止rabbitmq:systemctl rabbitmq-server stop重启rabbitmq:systemctl rabbitmq-server restart
RabbitMQ的启动、停止、重启没什么好说的
rabbitmqctl list_users:列出所有用户rabbitmqctl delete_user 用户名:删除某个用户rabbitmqctl add_user 用户名 密码:添加某个用户rabbitmqctl change_password 用户名 密码

rabbitmqctl set_permissions -p 虚拟地址 用户名 ".*" ".*" ".*":设置权限rabbitmqctl clear_permissions -p 虚拟地址 用户名:清除权限rabbitmqctl list_user_permissions 用户名:列出该用户的权限rabbitmqctl set_user_tags 用户名 administrator:设置该用户为管理员。除了设置为管理员,还可以设置为其它角色:none、management、policymaker、monitoring、administrator,权限大小依次递增。
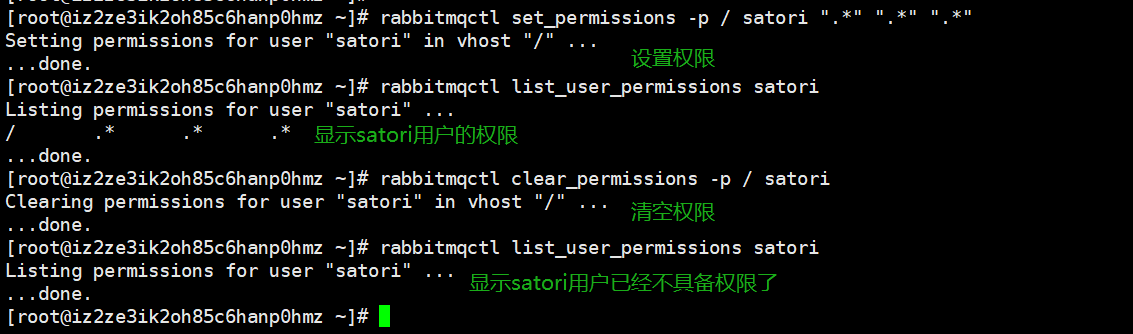
rabbitmqctl list_vhosts:列出所有虚拟地址rabbitmqctl list_permissions -p 虚拟地址:列出该虚拟地址所在主机的权限rabbitmqctl add_vhost 虚拟地址:创建虚拟地址rabbitmqctl delete_vhost 虚拟地址:删除虚拟地址
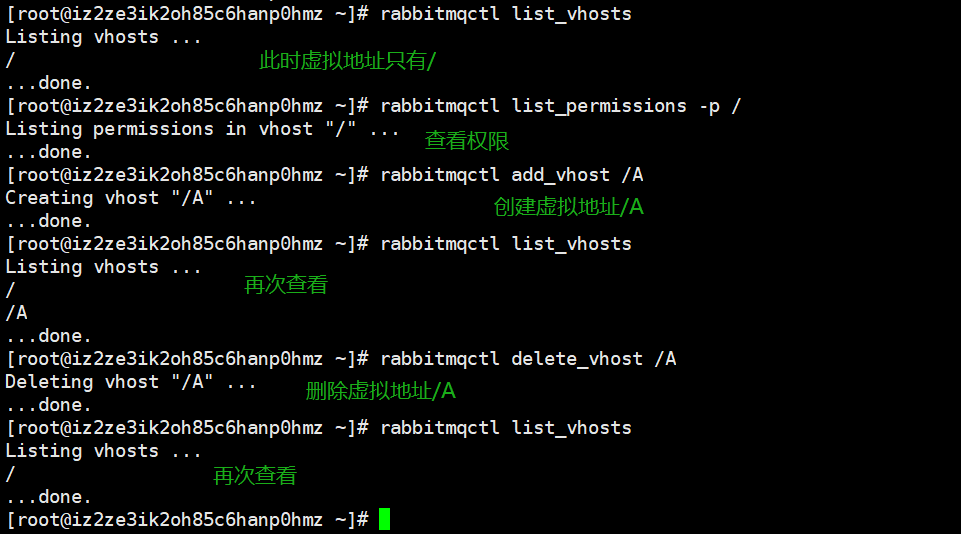
rabbitmqctl list_queues:查看所有队列信息rabbitmqctl -p 虚拟地址 purge_queue 队列:清除队列里面的信息rabbitmqctl reset:移除所有队列的所有数据,但是不推荐使用
RabbitMQ支持的命令非常多,包括还有集群的命令,比如:集群之间如果有机器挂掉了,那么如果将挂掉的机器从集群中移出去、或者指定消息是存储在磁盘中还是内存中等等。但是如果把命令一次性全捞出来,则对于学习来讲无疑是个灾难,我们目前就先记住这么多吧。当然不用刻意的去记,多实际操作几波就可以了。
消息生产与消费
生产者发送消息到队列(注意:我们这里说到队列里面去,不是直接去的,而是经过了我们之前说的几个步骤的)里面去,然后消费者监听,从队列里面取消息。在代码层面分为以下几步:
1. 创建一个连接connection,相当于建立一个TCP连接,它封装了socket协议相关部分逻辑,生产者和消费者的都是通过TCP的连接到RabbitMQ Server中的,这个后续会在程序中体现出来。2. 根据connection创建网络信道channel,channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。另外,这个channel相当于一个虚拟连接,建立在上面TCP连接的基础上,数据流动都是通过Channel来进行的。为什么不是直接建立在TCP的基础上进行数据流动呢?如果建立在TCP的基础上进行数据流动,建立和关闭TCP连接有代价。频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。3. Queue:根据Channel创建一个队列,具体存储消息的4. Producer & Consumer:生产者和消费者,生产者负责生产消息,消费者负责消费消息
下面我们来使用python向RabbitMQ里面生产数据和消费数据,使用python作为客户端连接的话需要使用一个叫做pika的模块,直接pip install pika即可。接下来我就直接在Windows机器上操作我阿里云上的RabbitMQ。
生产者:
import pika
# 我们现在是远程登录,一般情况下公司不可能随便就会让你远程连接,所以肯定需要指定用户进行认证。
# 我们之前创建了一个名为satori的用户并赋予了管理员权限
credentials = pika.PlainCredentials("satori", "123456")
# 创建了connection,相当于建立了tcp连接
# 如果连接的时候报出了pika.exceptions.ProbableAccessDeniedError,那么就要考虑你的用户是否具有相应的权限
# 可能该用户只在某个虚拟地址下有权限,那么你还需要指定一个参数:virtual_host,默认是'/'
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
# 端口可以不用指定,默认是5672
# 当然如果修改了端口,那么就要重新指定了
port=5672,
credentials=credentials))
# 这一步则是在tcp连接的基础之上创建了一个channel,用来生成Queue,send message等等
channel = connection.channel()
# 使用channel声明一个Queue,就叫girls吧
channel.queue_declare(queue="girls")
# 下面发布消息,会将消息发送到上一步声明的队列里面
# 我们目前还没有用到交换机,所以暂时exchange以及routing_key都没有什么用
# 但是这三个参数必须指定
channel.basic_publish(exchange="",
routing_key="girls",
body="my name is satori")
# 消息发送完毕之后,关闭连接
channel.close()
消费者:
from pprint import pprint
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
# 这里还是声明一个queue,刚才生产者明明已经声明了,为什么还要再次声明?先不管,后面说
channel.queue_declare(queue="girls")
# 定义一个回调函数
def on_message_callback(ch, method, properties, body):
pprint({"ch": ch, "method": method, "properties": properties, "body": body})
# 订阅,消费消息
channel.basic_consume("girls", # 指定队列
# 指定回调函数,从消息队列中取出的消息会自动传递给回调函数
on_message_callback=on_message_callback,
# 消费者从队列里面取走消息之后,是否删除队列中的消息,默认为False。
# 如果为True,那么消费者取走了消息后,队列里面的消息就会被删除
# 如果为False,即便消费者取走了,消息还是会坚挺在队列里面
# 假设此时消息队列里面有3条数据,如果为Flase,那么不管执行多少次,都会取得这三条数据
# 要是再往队列里面放两条数据,那么下一次消费者就会取5条数据。
auto_ack=True
)
# 这一步才算是真正开始消费
channel.start_consuming()
然后启动生产者,发送成功之后,再启动消费者。当然先启动哪一个其实没有影响,然后消费者会自动将消息从队列里面取出,然后传递给我们定义的回调函数,最终打印如下:
"""
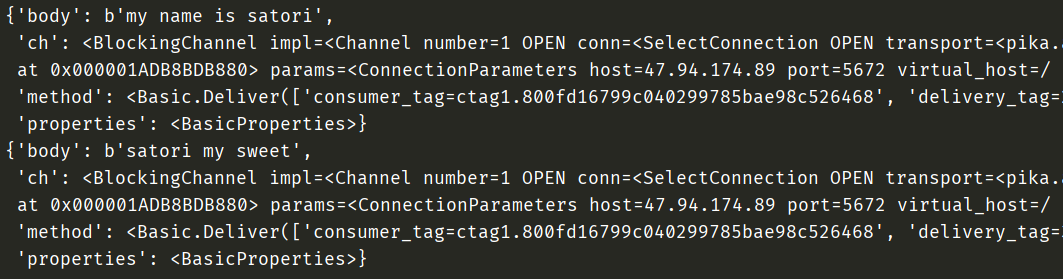
{'body': b'my name is satori',
'ch': <BlockingChannel impl=<Channel number=1 OPEN conn=<SelectConnection OPEN transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ADB8BDB880> params=<ConnectionParameters host=47.94.174.89 port=5672 virtual_host=/ ssl=False>>>>,
'method': <Basic.Deliver(['consumer_tag=ctag1.800fd16799c040299785bae98c526468', 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=girls'])>,
'properties': <BasicProperties>}
"""
body:生产者往队列里面发送的内容ch:队列method:生产者发送消息时带的一些参数,比如requests请求网页的时候也会带一些请求头之类的properties:一些属性,先不管
另外:生产者发送完消息之后程序就结束了,但是消费者会一直死循环卡在那里,因为会一直等待监听、等待消息。如果此时生产者再往队列里面发送一条消息,那么消费者会自动取出。
此时我关闭消费者,然后让生产者再往里面发送两条消息:message1、message2
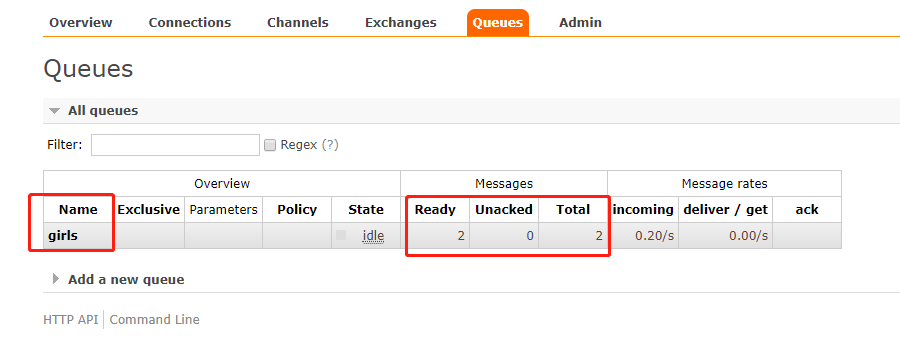
我们通过webUI看到此时girls队列里面有两条数据,或者我们通过命令行来查看也是可以的

然后我们启动消费者:
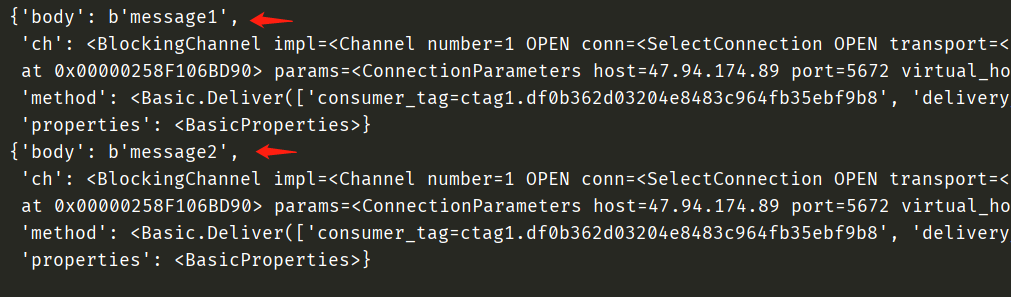
我们看到message1和message2已经被取走了,那么再来看看队列:

此时队列中消息也已经没了,这里再提一句上了auto_ack参数,如果指定为False,那么消费者消费完之后,队列中的这两条信息还会存在,不会被队列清除。
以上我们就简单演示了如何使用python操作RabbitMQ,但是还有一个问题
为什么生产者已经声明了queue,却要在消费者当中再次声明呢?
因为我们说不准到底是生产者先启动还是消费者先启动,如果消费者先启动而且不声明queue的话,消费者上哪儿排队去。好比一个包子铺,如果没有那么消费者会创建一个,生产者做好包子就直接往里面放就可以了。所以当声明一个queue时,会先检测有没有这个queue,如果没有会先创建,有的话直接生产消息或者消费消息。所以这算是一个为了安全起见所采取的措施,因此当消费者启动之后,如果没有指定的队列,那么也会创建一个队列。但是消费者和生产者创建的队列的属性必须保持一致,假设生产者创建了A队列,并且创建的时候指定了持久化(后面说),消费在创建A队列的时候,也必须指定为持久化,否则报错。尽管当消费者创建A队列的时候,队列已经存在,不会再创建了,但是仍然要保持属性一致
消息安全接收
我们实现了消息的发送和接收,但是显然我们还没有考虑到安全性,那就是如何让RabbitMQ知道这条消息已经被消费掉了呢?如果消费者在消费消息的时候突然挂掉了,消息没消费完,包子吃一半噎死了,该咋办呢?
比如:此时消息队列里面有一条消息,当消费者取走这条消息的时候,RabbitMQ就会将消息从队列里面删除,但是消费者在消费的时候出现了异常。因此只能重新消费,但是队列里面已经没有了。因此可能有人想到了一个办法,那就是先指定auto_ack=False,消费者取走之后,让消息依旧存储在队列里面。当消费者取走消息、并且相应的逻辑执行成功之后,再指定auto_ack=True再获取一次。
这确实是一个办法,但显然不是最优的办法。其实rabbitmq有一个机制,那就是在指定auto_ack=False的时候,也是可以删除队列中的数据的。我们说auto_ack=False的时候,默认是不会删除队列中的消息的。但是当消费者消费完一条消息之后,如果给服务器端一个响应表示已经消费完了,你把消息给我从队列里面删除,那么RabbitMQ这个时候就会将消息从队列里面删除。
from pprint import pprint
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="girls")
def on_message_callback(ch, method, properties, body):
pprint({"ch": ch, "method": method, "properties": properties, "body": body})
# 消息消费完毕,如果想删除队列中的消息
# 那么必须要给服务端发送一个确认信息,告诉服务端消息消费完了
# 当然还要确保消费的消息确实是队列中需要删除的消息,通过参数method.delivery_tag实现
# 不能拿一个韭菜馅的包子,然后说白菜馅的包子吃完了
ch.basic_ack(delivery_tag=method.delivery_tag)
"""
我们说这里的逻辑是将消息从队列中取走,然后传递给回调函数
如果指定auto_ack=True,那么当消息取走的那一刹那,RabbitMQ就会将消息从队列里面删除
因为对于RabbitMQ来说,它不管你有没有消费成功。
只要你传递了auto_ack=True,并把消息取走了,那么RabbitMQ就会把消息从队列里面删掉
所以我们指定auto_ack=False,此时RabbitMQ就会确保这条消息真的被消费了,才会删除
而消费者有没有消费成功,RabbitMQ服务端是不知道的,因此就会将这条消息一直保留在队列里
除非消费者给RabbitMQ服务端一个反馈,明确告诉服务端自己已经把消息消费完了,RabbitMQ才会删除。
"""
channel.basic_consume("girls",
on_message_callback=on_message_callback,
auto_ack=False
)
channel.start_consuming()
执行代码,消费数据,此时再看队列,会发现数据已经没了,因为我们在消费完数据之后给服务端一个反馈告诉服务端自己把数据消费完了。
那么这背后的机制是什么呢?
其实在指定auto_ack=False、然后将数据取走的时候,尽管这条消息不会被删除,但是会打上一个标记,表示这条消息已经被取走了。此时可以看成是将消息拷贝了一份给消费者,但此时队列中该条的消息已经被打上了一个标记;如果消费者在之后又给服务端一个反馈,告诉服务端自己已经消费完了,那么这时候服务端就会将该消息从队列里面删掉,而消费者传递的delivery_tag=method.delivery_tag则保证了删除的消息是自己消费的那条,而不是别的消息;但如果消费者挂掉了,得不到响应,那么会将标记清除,等待其他消费者消费。并且一旦某个消费者无法消费,那么服务器就会得到响应,知道socket断开,下次就不会再将消息发给这个消费者了。
在生产中,我们一般都会指定auto_ack=False,然后当消费者消费完之后主动提交一个反馈,然后删除消息。
如果有三个消费者,但是只有一条消息怎么办?
如果有三个消费者,但是只有一条消息,那么对于当前来说,一条消息只会被一个消费者消费。如果这条消息被取走了,那么不管有没有消费完,其它的消费者都不能再消费。另外,即便消费者消费完了,但如果没有给服务端反馈,那么服务端都会认为没有消费完,因为服务端是不知道消费者是否消费完了消息。如果在服务端收到反馈之前,因为某种原因,该消费者断开了,那么服务端就会感知到这个消费者挂掉了。那么该消费者所取走的消息会被认为消费失败,那么会将队列中对应的消息上的标记清除,并交给其它的消费者进行消费。这样就确保了在有消息、又有消费者的情况下,能让消费者消费消息,不会出现消息无法被消费者消费的情况。
消息持久化
现在问题又来了,我们刚才关心的是消费者挂了,消息怎么消费。那万一RabbitMQ服务挂了呢?我们生产者往队列里面写了好多消息,但消费者还没来得及消费,服务就挂掉了,那么队列里面的消息还在吗?答案是别说消息了,连队列都没了。那么怎么办呢?

channel.basic_qos(prefetch_count=1)
# 此外在消费者中加上这一行,表示消息在发送给消费者的时候会考虑负载均衡
# 注意:这一行代码是写在消费者当中的,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
消息的订阅和发布
之前的例子都是一对一的消息发送和接收,即消息只能发送到指定的queue里面,但是有些时候希望消息被所有的queue接收到,起到类似于广播的效果,那么这个时候就需要exchange了。并且广播是不会像之前一样,消费者不在线就把消息存起来,等消费者上线再接收。广播的话,不管消费者在不在线都要广播,并且广播完了就不再广播了。还记得exchange有哪四种类型吗?我们来演示一下
fanout
我们说fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
生产者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
port=5672,
credentials=credentials))
channel = connection.channel()
# 声明交换机,并且此时不需要声明队列,因为我们不再往队列里面发了,而是往exchange里面发
# 指定交换机类型为fanout
channel.exchange_declare(exchange="logs", exchange_type="fanout")
# 因为我们声明了名为logs的交换机,那么这个时候就会往交换机里面发
# 如果不存在名为logs的交换机,那么此时就会报错
# 是的,这个exchange参数代表的是交换机。如果指定了,那么消息就会往交换机里面发
# 但如果没指定(传了个空字符串),那么就会往上一步声明的队列里面发送,正如我们上面演示的那样
# 而且这个参数也就是第一个参数
channel.basic_publish(exchange="logs",
routing_key="", # 此时的routing_key直接传递一个空字符串即可,因为知道exchange的类型是fanout,所以直接广播给每个队列
body="satori",
)
channel.close()
消费者:
from pprint import pprint
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
# 这里同样需要声明,因为我们说过可以消费者先启动,并且这里必须消费者先启动
# 所以也要指定交换机
channel.exchange_declare(exchange="logs", exchange_type="fanout")
# 注意绑定到交换机上的队列不可以重名,如果有一个队列绑定到交换上了,那么这个队列就不能二次绑定了
# 这里的exclusive表示排他,也就是rabbitmq会帮我们生成不重名的队列名
# 所以这里的queue,我们也是传递一个空字符串,因为rabbitmq帮我们返回了一个唯一的队列名
# 并且会在消费者断开之后,自动将该queue删除掉
result = channel.queue_declare("", exclusive=True)
# 调用result.method.queue会拿到该队列名
queue_name = result.method.queue
# 将生成的queue绑定到交换机上,这样当生产者发送数据给exchange的时候,exchange会自动的将数据发送到绑定的queue里面
# 如果不绑定,那么是接收不到的。因为上面的生产者是将数据发送到交换机里面的,所以必须将队列绑定到交换机上
# 这里的交换机的名字是"logs"
channel.queue_bind(exchange="logs", queue=queue_name)
def on_message_callback(ch, method, properties, body):
print(body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue_name,
on_message_callback=on_message_callback,
)
channel.start_consuming()
我们将消费者的代码执行两次,那么这里就会向交换机logs绑定了两个不重名的队列,当生产者写入数据的时候,会进行广播,所有的消费者都会收到消息。但是注意:消费者绑定的队列不可以重名,并且这个时候一定要先启动消费者,再启动生产者。因为生产者一旦启动,不管消费者有没有在线,都会广播,等到消费者上线,已经广播完了。
我们执行代码,会看到两个消费者都能收到数据,这里就不截图了。我们看一下队列吧
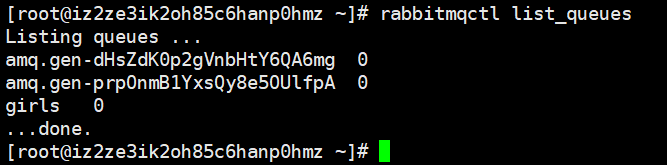
我们看到多了两个队列,队列的名字是RabbitMQ自动帮我们创建的。并且这两个队列是一次性的,消费者断开之后就会自动删除。这里之所以还没有删,是因为我们的消费者还处于监听状态,没有断开。下面我们将消费者断开,再来看一下:

此时队列已经被删除了,因为消费者断开了。
direct
direct类型的Exchange则是把消息路由到那些binding key与routing key完全匹配的Queue中,另外如果在声明交换机的时候,不指定exchange_type,那么默认就是direct
生产者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
port=5672,
credentials=credentials))
channel = connection.channel()
# 默认是direct,这里交换机也不可以重名,我们刚才已经指定一个交换机了
channel.exchange_declare(exchange="logs_2")
channel.basic_publish(exchange="logs_2",
# 指定routing_key="A"
# 那么只有和交换机绑定时,指定binding_key也为"A"的队列才可以接收到
routing_key="A",
body="satori",
)
channel.close()
消费者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="logs_2")
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
# 绑定的时候指定binding_key,但是这里参数名叫做routing_key,我们知道就行
channel.queue_bind(exchange="logs_2", queue=queue_name, routing_key="A")
def on_message_callback(ch, method, properties, body):
print(body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue_name,
on_message_callback=on_message_callback,
)
channel.start_consuming()
然后启动消费者再启动生产者,会发现消费者可以消费到数据。但是如果这里的binding_key不指定为"A",而是指定为"B"的话,就接收不到了。
topic
topic和direct比较类似,只不过此时的routing_key是以"点"分隔字符串,每个部分称为一个单词。同理binding_key也是如此,并且binding_key可以存在两种元字符,*代表任意一个单词(注意:是单词,不是单个字符),#代表任意多个单词。
生产者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
port=5672,
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="logs3", exchange_type="topic")
channel.basic_publish(exchange="logs3",
routing_key="hello.python",
body="satori",
)
channel.close()
消费者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="logs3", exchange_type="topic")
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange="logs3", queue=queue_name, routing_key="#.#")
def on_message_callback(ch, method, properties, body):
print(body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue_name,
on_message_callback=on_message_callback,
)
channel.start_consuming()
headers
不再演示
值得一提的是,在声明交换机和队列的时候,都可以加上一个auto_delete参数
channel.exchange_declare(exchange="logs4", auto_delete=True)
channel.queue_declare("xx", auto_delete=True)
该参数默认为False,如果为True。那么在声明队列时,如果所有监听该队列的消费者断开,那么该队列就会被删除;在声明交换机的时候指定auto_delete=True,那么当所有绑定在此交换机上的队列都被删除时,该交换机会被删除。
当然里面还有其它参数,比如arguments,这个是在扩展AMQP协议的时候使用的,可以附加一些属性。
消息rpc
我们目前消息的发送都是单向的,也就是生产者发送消息,消费者消费消息,那么消费者可不可以给生产者反馈呢?显然是可以的,此时就需要两个队列,不能只有一个队列,否则就死循环了。A往队列1发送数据,B从队列1里面取数据。然后B往队列2发数据,A往队列2取数据。
假设我们有一个客户端和一个服务端,服务端上面有一个服务,客户端给服务端传递一个参数,服务端根据参数计算出相应的结果,然后再返回给客户端。我们实现一下上面的需求,因此此时的服务端相当于消费者,要一直开启监听,客户端相当于生产者。
生产者:
import uuid
import pika
class Client:
def __init__(self):
credentials = pika.PlainCredentials("satori", "123456")
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
port=5672,
credentials=credentials))
self.channel = self.connection.channel()
# 声明一个队列:
self.queue = self.channel.queue_declare("", exclusive=True).method.queue
# 这里的客户端相当于生产者,但是注意:此时是双向的,那么生产者也要能够消费数据
# 消费的数据来自于上面声明的队列
self.channel.basic_consume("", on_message_callback=self.on_message_callback)
# 生成一个不重复的id,也是给消息起一个id
self.corr_id = str(uuid.uuid4())
# 服务端返回的消息内容
self.body = None
def on_message_callback(self, ch, method, properties, body):
if self.corr_id == properties.correlation_id:
self.body = body.decode("utf-8")
def remote_server(self, arg):
"""
给服务端传递参数,调用服务
"""
# 这里就是给服务端发送消息了
# 这里再次声明一个queue,因为客户端传递、服务端接收的queue是同一个queue
# 但是接收服务端返回消息的queue则必须是另一个queue
self.channel.queue_declare("calc")
self.channel.basic_publish(exchange='',
routing_key='calc',
# 注意这里的逻辑,我们持久化也是在这里面指定的
properties=pika.BasicProperties(
# 将消息发送给服务端服务端
# 并告诉服务端返回消息的话,就返回到self.queue中
reply_to=self.queue,
# 给消息加上一个id
correlation_id=self.corr_id,
),
body=str(arg))
# 因为此时客户端、相当于生产者也开启了监听
# 一旦返回,就会执行on_message_callback,通过properties.correlation_id可以拿到消息的id
# 判断是不是我们需要的消息,然后将消息内容赋值给self.body
while self.body is None:
# 这一步会一直检测队列中是否有消息,但是注意:这一步是不阻塞的
self.connection.process_data_events()
# 一旦有消息,那么读取
return int(self.body)
client = Client()
print(client.remote_server(100))
消费者:
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="47.94.174.89",
credentials=credentials))
channel = connection.channel()
channel.queue_declare("calc")
def on_message_callback(ch, method, properties, body):
# 这里body显然是客户端传递的arg
# 我们直接计算1到该数的和
res = sum(range(int(body.decode("utf-8"))))
# 我们说客户端是生产者、但是也要能消费数据
# 同理这里的服务端作为消费者,同时也可以生产数据
ch.basic_publish(exchange="",
# 我们将客户端传递的消息接收之后,可以获取客户端指定的reply_to
# 事实上,对于直接往队列里面发送,这个routing_key其实没用
# 因为这里的routing_key主要用于交换机当中,这里即便注释掉也是可以的
# 但是有人好奇了,既然没有用,那么它是怎么把消息发送到客户端指定的queue当中呢
# 注意这里的ch,我们使用ch.basic_publish,而不是channel.basic_public
# 因为channel.basic_public,会自动往声明的队列里面发送。
# 而这里的ch是根据客户端传递的消息获取的,所以这里面包含了发送的queue信息
# 所以我们用的不是这里的channel,而是包含了指定客户端指定队列信息的channel
routing_key=properties.reply_to,
# 同样取出里面id,然后返回消息的时候,也加上这个id,不然客户端是不会消费的
properties=pika.BasicProperties(correlation_id=properties.correlation_id),
body=str(res))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume("calc",
on_message_callback=on_message_callback,
)
channel.start_consuming()
当我们启动客户端和服务端的时候,在客户端的控制台上会打印出4950。事实上,这里无论是先启动客户端还是先启动服务端,效果都是一样的。只不过先启动客户端,客户端会阻塞罢了,因为服务端不返回数据会一直死循环。
总结
RabbitMQ我们就说到这里,中间介绍的比较零碎,但是仔细读完的话,还是能满足日常操作的。
pyquery:轻松、灵活的处理html的更多相关文章
- EasyExcel 轻松灵活读取Excel内容
写在前面 Java 后端程序员应该会遇到读取 Excel 信息到 DB 等相关需求,脑海中可能突然间想起 Apache POI 这个技术解决方案,但是当 Excel 的数据量非常大的时候,你也许发现, ...
- 一起学爬虫——PyQuery常用用法总结
什么是PyQuery PyQuery是一个类似于jQuery的解析网页工具,使用lxml操作xml和html文档,它的语法和jQuery很像.和XPATH,Beautiful Soup比起来,PyQu ...
- TurboCAD Pro for Mac(二维绘图和三维建模工具)破解版安装
1.软件简介 TurboCAD Pro 是 macOS 系统上一款二维绘图和三维建模工具,具备强大的绘图和设计特性,加上强大的创建复杂的三维模型的工具,三维 OpenGL 的渲染,和超过 11, ...
- 评点SAP HR功能及人力资源管理软件
评点SAP HR功能及人力资源管理软件 本文导航 第1页:my SAP 人力资源软件 第2页:my SAP HR协同功能 第3页:组织结构管理 第4页:mySAPTM HR的战略功能 第5页:集成 ...
- 来看看Uber的司机支持服务签到及预约系统的架构设计思路
Uber的Greenlight Hubs(GLH)在全球拥有超过700个分支机构,为合作车主提供从账户和支付到车辆检查和车主注册等各方面的人工支持.为了给合作车主创造更好的体验并提高客户满意度,Ube ...
- Lombok 使用详解,简化Java编程
前言 在 Java 应用程序中存在许多重复相似的.生成之后几乎不对其做更改的代码,但是我们还不得不花费很多精力编写它们来满足 Java 的编译需求 比如,在 Java 应用程序开发中,我们几乎要为所有 ...
- 一个SAP顾问的回忆:我过去很胖!
去年也是这个时候,SAP成都研究院体育界大神邓阳,曾经赏脸在Jerry这个公众号上赐文一篇,介绍了他和围绕在他身边的一群小伙伴们的体育故事:SAP成都研究院的体育故事 而今天文章的主角则是SAP成都研 ...
- hue初识
Hue Web应用的架构 Hue 是一个Web应用,用来简化用户和Hadoop集群的交互.Hue技术架构,如下图所示,从总体上来讲,Hue应用采用的是B/S架构,该web应用的后台采用python编程 ...
- 聊聊elasticsearch7.8的模板和动态映射
最近想写一篇es的索引的一个设计,由于设计的东西特别多,当然,elasticsearch的模板和动态映射也是其中的一个设计点,所以干脆先来聊聊索引的模板和动态映射,模板,听这个名字就相当于一些公共可用 ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
随机推荐
- UI的流畅度优化
Android中所有的界面绘制工作都是在UI线程中进行的,提高UI流畅度的最核心根本在于释放UI线程.即:不在主线程中做耗时的操作. 很多人都知道,耗时的操作要放到子线程中去做,比如访问网络,比如读写 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_2_04微服务下电商项目基础模块设计
笔记 4.微服务下电商项目基础模块设计 简介:微服务下电商项目基础模块设计 分离几个模块,课程围绕这个基础项目进行学习 小而精的方式学习微服务 1.用户服务 ...
- Xcode8.1 真机测试 ,添加iOS10.3的idk到Xcode8.1中
1.下载iOS10.3的idk包; 2.解压, 找到路径 Finder -> 应用程序 -> 右键Xcode -> 显示包内容 -> Contents -> Develo ...
- CentOS的SVN服务器搭建与自动部署全过程
CentOS的SVN服务器搭建与自动部署全过程 http://www.jb51.net/article/106218.htm authz-db = authz 引起的 svn 认证失败 http:// ...
- 嵌入式【杂记--手机芯片与pc】
手机.身边的移动设备大多数是嵌入式计算机,pc也是计算机,只是功耗上很大. 手机所采用的大多数芯片是英国ARM公司的架构coretom A系列 core, Intel公司采用自己的架构设计的芯片适用于 ...
- react 添加代理 proxy
react package.json中proxy的配置如下 "proxy": { "/api/rjwl": { "target": &quo ...
- 刷新页面后,让控制台的js代码继续执行
在各种限时,秒杀活动中,有个自动循环的点击的工具是很重要的. 为了方便起见,我们把Js代码放在浏览器的控制台执行,但是刷新页面后,js代码就清空了,也就无法执行. 可以用js代码实现一个不受页面刷新影 ...
- <转>常规测试方法
功能测试 1. 安装测试: 安装过程中对于缺省安装目录及任意指定的安装目录,是否都能正确安装: 若是选择安装,查看能否实现其相应的功能: 在所有能中途退出安装的位置退出安装程序后,验证此程序并未安装成 ...
- 强化学习应用于游戏Tic-Tac-Toe
Tic-Tac-Toe游戏为3*3格子里轮流下棋,一方先有3子成直线的为赢家. 参考代码如下,我只删除了几个没用的地方: ####################################### ...
- 浅谈Web图像优化
前端优化有很多,图像优化也是其中的一部分.无论是渐进增强还是优雅降级,图像优化成为了开发上不可忽视的一部分. 知其然,须知其所以然 图像优化的前提是需要了解图像的基本原理.常规的图像格式分为矢量图和位 ...