Learning to See in the Dark论文阅读笔记
这是一篇图像增强的论文,作者创建了一个数据集合,和以往的问题不同,作者的创建的see in the dark(SID)数据集合是在极其暗的光照下拍摄的,这个点可以作为一个很大的contribution
实际上我认为作者实际上是做了三个工作,以及图像去马赛克(demosaic),图像增强(enhancement)和图像去噪(denoise)
denoise
作者在introduction中回顾了以前的工作,包括图像去噪,图像去马赛克的工作,以及图像增强,在图像去噪方面,作者有提及之前的深度学习相关的方法,并且也说有些工作是图像demosaic和denoise同时做的,缺陷就是他们只在合成的数据几何上进行了实验,并没有在真实的数据集合上进行实验
low-light image enhancement
在回顾enhancement作者说,直方图均衡化是一种比较经典的方法,用于图像增强。另外一个比较经典的方法是gamma校正,gamma校正能够补偿暗区域,抑制比较亮的区域
还有一些其他的方法 用于图像增强,比如inverse暗通道,小波变换,视网膜模型,以及亮度图估计
但是现有的图像增强的方法并没有显式的建立图像的噪声模型,并且只是在后处理阶段应用一些现成的去噪算法(图像增强自己paper看的太少,给自己挖个坑)
noise image dataset
作者说,SID是第一个建立的有gt的低光数据集合,所以,contribution还是挺大的
数据集合建立
如下图,
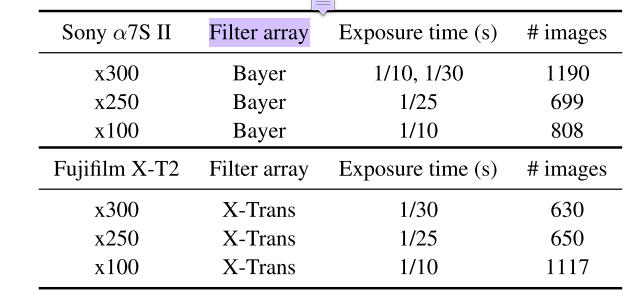
有两种成像阵列,一个是bayer的阵列,一个是X-trans的阵列,总共5094张图片
作者在拍摄每一张暗的图片的时候,都h经过长时间曝光得到一个比较亮的图片,由此构成图片对
作者还说,长时间曝光得到的图片实际上是包含噪声的,我们的target是得到perceptual quality足够高就行,而不是得到高对比度的图片
其实我觉得这种方式采集得到的图像,肯定是包含很多噪声的,但是对于这种任务而言,应该是无关紧要,这种任务的落地场景是黑天拍到的图像想要有黑夜的感觉,这种feeling就是perceptual quality,其实也真不一定需要的是看得清,而是feeling
两个相机拍摄的到的尺寸不一样,并且还挺大的,一个是60004000,一个是42402832
method
在讲坐着的方法之前,作者回顾了之前的是那种方法,一个是traditional的方法,一个是L3的方法,还有就是Burst方法
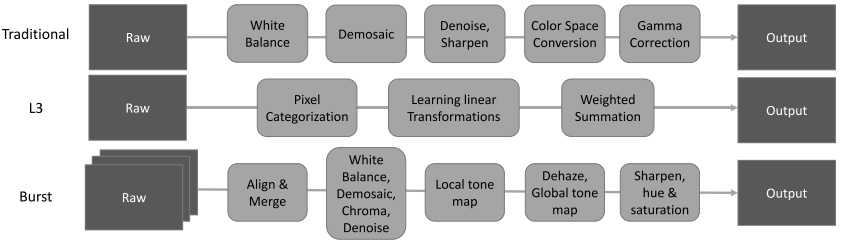
传统的方法是有一系列的step,比如先白平衡,然后demosaicing,之后denoise,sharpening,color space conversion,gamma correction还有一些其他的东西,最后得到输出的图片,这种方法大概是不同的相机有自己的一套处理算法,isp那种
L3算法则不同,L3算法是用一种large collection of local,linear and learned filters 来近似复杂的非线性piplines
但是作者说,无论是传统的pipline或者是L3 pipline,都不能处理快速的low-light图像,以你为他们不能够处理很大的峰值信噪比
除了上面说的两种方法之外,还有一种burst imageing pipline,这种方法常用在智能手机上,尽管这种方法通过aligning 和blending多张图片,但是这个过程非常的复杂,比如需要密集匹配,可能不能获取一段视频序列,或者会用到lucky imageing
作者的method,从网络结构上来说没啥创新,如下图
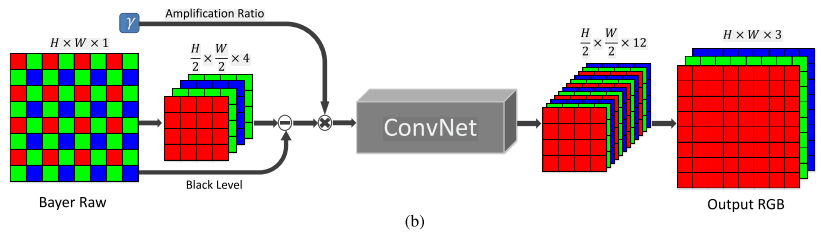
输入一个原始的bayer阵列图,作者对像素进行重新排列得到channel为4的数据,
关于重新排列,bayer arrays和X-Trans array不太一样,如下图

bayer用44的blocks重排,X-Trans用66的blocks重排,channel是9因为交换了相邻的元素(不太懂)
输出都是12channel的尺寸为图像一半的image
因为处理的是全分辨率的图像(后面训练的过程貌似crop了),所以需要的网络不能太大,作者这里用了两种网络,一种是CAN,另外一种是Unet
训练
在训练的过程中,作者用了L1 loss,和adam optimizer,
输入的是short-exposed image,输出的是long-exposure的图片,这里的gt,作者用libraw已经处理过,色彩空间是sRGB空间
因为两张图片的尺寸不一样,作者在这里用了两个网络去训练,注意到在训练的时候有一个amplification ratio,作者将这个设置为输入和输出之间的曝光时间比例
同时,对于图像随机crop512*512的尺寸,以及做了一个随机的flip以及rotation
lr一开始设置为1e-4之后减为1e-5
训练4000epoch
实验结果
作者首先展现了一些质量评估的结果,

可以看出,traditional method不能handlenoise以及color bias
所以传统的图像增强方法(如果不对噪声进行建模)的话,produce的图像噪声会非常的严重,因此作者采用了
一种图像去噪的方法BM3D,BM3D是一种非blind的去噪方法,需要指定noise-level的等级,如果指定太小的噪声的话,那么可能会去不干净,如果指定太大的噪声的话,可能会over-smooth,如下图所示

两种噪声是同时存在的,所以BM3D并不能locally adapt to the data,相反,作者的方法显得整体比较和谐
作者还说,如果和BM3D以及burst processing方法比较PSNR/SSIM是不公平的,因为,这些baseline不得不需要一些处理,为了更加公平的比较不同的方法,作者对于这一部分陈述的比较复杂,如何是一个公平的比较法呢,作者用reference image的白平衡参数来减少色彩的偏差(应该是不同方法输出的图片),同时,他们逐个channel的scale图像使得不同方法输出的图像和reference image有相同的mean values
尽管这样,作者并没有用两个指标来评价校正图像的好坏,而是用A/B test
结果如下

在比较难得Sony x300 set上,作者的结果碾压BM3D,在比较简单的Sony x100 set数据集合上,作者的结果与之相当,
作者自己拍摄了一些图片,并且进行了测试,也能够得到良好的实验结果
ablation study
作者的ablation study实验结果如下,这个时候作者用了PSNR和SSIM两个指标

Unet换成CAN的话,略有下降,但是Fuji上升了不少在ssim上升了不少
同时,如果输入的色彩空间是sRGB,会香江很多店,感觉Sony对于色彩空间更加敏感,而Fuji并不是,如果将L1换成SSIMloss的话,指标会波动一些
换成L2loss的话,也差不多把
作者还对比了不同的data arrangement对于实验结果的影响,另外一种数据arrangement不是特别懂,这里就忽略了
下面一个是作者对比了一下,如果将gt进行直方图均衡化,看看会得到什么结果
如果将gt进行直方图均衡化的话,实际上是让网络学习到一种直方图均衡化的能力,实际上作者发现,好像并没有让网络学习到这种东西,而且点掉的非常厉害,因此作者通过分析实验得到的结论是,不用把直方图均衡化纳入到网络的pipline中,可以作为一个postprocess的过程
结论
在结果中,作者讨论了很多,快速低光图像增强非常具有挑战性,因为其含有很少的光子,以及很低的snr,
作者提出的方法的limitation是,必须要手动输入amplification ratio,选取一个amplification ratio是非常的有用的,同时,作者说他们的不同的ccd有不同的网络,实际上通用性不强,我感觉这个如果以后有用的话,也应该是针对不同的相机,所以问题不大
另外作者说网络跑的比较慢,基本上需要0.38-0.66s,来处理一张full-resolution的图片
以及,作者说他希望未来的工作可以集中在图像质量的改善上,以及完善和集成训练步骤
后续工作
搜了一下谷歌学术的引用,感觉引这篇文章的人并不多,而且在此工作上做的我好像一篇都没看到
相反,github上star非常多,不说了,我先下载代码跑跑,看看有没有灵感
作者说他尝试了一下gan的loss,并不能够改变实验结果,文章中有一句话提及到了这个事情(准备亲自试一试这个)
关于讨论部分,作者说了三点
第一个是,算法并没有特别好的结果,有很大提升的空间
第二个是,现有的网络需要输入iso,能够做一个不需要iso的pipline是很有必要的
第三个是,网络的速度可以继续优化
Learning to See in the Dark论文阅读笔记的更多相关文章
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- Jean-Pierre Serre访问录
问:是什么使您以数学为职业的? 答:我记得大概是从七.八岁时起喜欢数学的.在中学里, 我常做一些高年级的题目.那时,我寄宿于Nimes,与比我大的孩子住在一起,他们常常欺侮我,为了平抚他们,我就经常帮 ...
- rxjs简单的Observable用例
import React from 'react'; import { Observable } from 'rxjs'; const FlowPage = () => { const onSu ...
- codechef Scoring Pairs
难度 \(medium-hard\) 题意 官方中文题意 做法 很显然是可以通过计算常数个\(sum(A,B)=\sum\limits_{i=0}^A \sum\limits_{j=0}^B scor ...
- javascript 权威指南一
1. JavaScript是面向web(网页)的编程语言. 2.html: 描述网页内容,css:描述网页样式,JavaScript:描述网页行为 3.JavaScript非常适合面向对象和函数式的编 ...
- C语言输出杨辉三角形
// 打印杨辉三角: 行 + 列 ][] = { }; // 1. 确定要打印的行数: 13(n) ; i < ; ++i) { // 2. 确定列数:杨辉三角 行 == 列 ; j <= ...
- gulp常用插件之gulp-babel使用
更多gulp常用插件使用请访问:gulp常用插件汇总 gulp-babel这是Babel的Gulp插件. 此自述文件适用于gulp-babel v8 + Babel v7检查7.x分支以了解使用Bab ...
- sqli-labs11-17(手注+sqlmap)
这几关涉及到的都是post型data处注入,和get型的差别就是注入点的测试处不一样,方法都是一样的 0x01 sqli-labs less-11 1.手工 由于是post型注入,那么我们不能在url ...
- springMVC三大组件、spring主要jar包、
一.springMVC三大组件 处理器映射器 RequestMappingHandlerMapping 处理器适配器 RequestMappingHandlerAdapter 视图解析器 Int ...
- PTA-德州扑克 题解
于2020/02/24记录. 德州扑克属实是个带难题.本题解简单易懂,命名合理,应该比较好理解. 题目如下: 最近,阿夸迷于德州扑克.所以她找到了很多人和她一起玩.由于人数众多,阿夸必须更改游戏规则: ...
- 0级搭建类011-Oracle Linux 7.x安装(OEL 7.7) 公开
项目文档引子系列是根据项目原型,制作的测试实验文档,目的是为了提升项目过程中的实际动手能力,打造精品文档AskScuti. 项目文档引子系列目前不对外发布,仅作为博客记录.如学员在实际工作过程中需提前 ...