CentOS7.0+Hadoop2.7.2+Hbase1.2.1搭建教程
1、软件版本
jdk-7u80-linux-x64.tar.gz
hadoop-2.7.2.tar.gz
hbase-1.2.1-bin.tar.gz
2、集群配置
主机:Slave1.Hadoop IP地址:192.168.1.101
主机:Slave2.Hadoop IP地址:192.168.1.102
用户设置:系统用了GUI,新版非得建立一个账户。例如随便建一个jfz,密码1,但操作时使用root(密码root)直接进行,装好后重启,以后用SSH进root。
3、配置本地hosts
输入指令:
nano /etc/hosts将以下数据复制进入各个主机中:
192.168.1.100 Master.Hadoop
192.168.1.101 Slave1.Hadoop
192.168.1.102 Slave2.Hadoop使用以下指令在Master主机中进行测试,可使用类似指令在Slave主机测试:
ping Master.Hadoop
ping Slave1.Hadoop
ping Slave2.Hadoop4、关闭防火墙
三台机器均关闭防火墙。
停止firewall:
systemctl stop firewalld.service禁止firewall开机启动:
systemctl disable firewalld.service5、Java安装
(1)卸载自带的OpenJDK v1.7:
java -version
yum remove java-1.7.0-openjdk重启。
(2) JDK安装:
在/usr下创建java文件夹,将jdk-7u80-linux-x64.tar.gz文件放到这个文件夹中。
使用以下指令进行解压
tar zxvf jdk-7u80-linux-x64.tar.gz解压后可以删除掉gz文件
rm jdk-7u80-linux-x64.tar.gz配置JDK环境变量:
nano /etc/profile添加Java环境变量,将以下数据复制到文件底部:
export JAVA_HOME=/usr/java/jdk1.7.0_80
export JRE_HOME=/usr/java/jdk1.7.0_80/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin重载使配置生效:
source /etc/profile验证安装成功:
java -version如果出现对应版本信息,则配置成功:java version "1.7.0_80"
6、SSH免密码登录
因为Hadoop需要通过SSH登录到各个节点进行操作,本集群用的是root用户,每台服务器都生成公钥,再合并到authorized_keys。
(1)修改sshd_config配置
CentOS默认没有启动SSH无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置。
nano /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes(2)生成key
输入命令:
ssh-keygen -t rsa生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置。
(3)合并key
合并公钥到authorized_keys文件,在Master服务器,进入/root/.ssh目录,通过SSH命令合并。
cat id_rsa.pub>> authorized_keys
ssh root@192.168.1.101 cat ~/.ssh/id_rsa.pub>> authorized_keys
ssh root@192.168.1.102 cat ~/.ssh/id_rsa.pub>> authorized_keys(4)拷贝key
把Master服务器的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录。
scp authorized_keys known_hosts root@192.168.1.101:/root/.ssh
scp authorized_keys known_hosts root@192.168.1.102:/root/.ssh(5)检证免密登陆
ssh root@192.168.1.101
ssh root@192.168.1.102以后就不需要输入密码了。
7、Hadoop安装流程
(1)下载hadoop安装包
将下载“hadoop-2.7.2.tar.gz”文件上传至到/home/hadoop目录下。
注意:一定要在Linux下解压,否则执行权限问题很麻烦。
(2)解压压缩包
tar -xzvf hadoop-2.7.2.tar.gz(3)在/home/hadoop目录下创建目录
创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
mkdir -p tmp hdfs/name hdfs/data(4)配置core-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/core-site.xml内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>(5)配置hdfs-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/hdfs-site.xml内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.100:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>(6)配置mapred-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.100:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.100:19888</value>
</property>
</configuration>(7)配置yarn-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/yarn-site.xml内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.100:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.100:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.100:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.100:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.100:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>注意:yarn.nodemanager.resource.memory-mb值要大于1024,否则影响进程!
(8)配置hadoop-env.sh、yarn-env.sh的JAVA_HOME
配置/home/hadoop/hadoop-2.7.2/etc/hadoop目录下:
hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了。
export JAVA_HOME=/usr/java/jdk1.7.0_80(9)配置slaves
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/slaves删除默认的localhost,增加2个从节点:
192.168.1.101
192.168.1.102(10)传送Hadoop至其它节点
将配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /home/hadoop 192.168.1.101:/home/
scp -r /home/hadoop 192.168.1.102:/home/(11)启动Hadoop
在Master服务器启动hadoop,从节点会自动启动。
进入/home/hadoop/hadoop-2.7.2目录,初始化,输入命令:
bin/hdfs namenode -format全部启动:
sbin/start-all.sh也可以分开启动sbin/start-dfs.sh、sbin/start-yarn.sh。
Hadoop环境变量配置,需要在/etc/profile 中添加HADOOP_HOME内容,之前已经配置过,所以这一步已经节省下来,那么可重启 source /etc/profile。
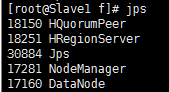
(12)验证Hadoop
jps运行成功结果:

8、Hbase安装流程
(1)复制安装包至Master节点/home/hbase目录下
通过SFTP或是直接拷贝至Master节点,软件推荐在Linux下解压!
(2)解压压缩包
tar zxvf hbase-1.2.1-bin.tar.gz(3)添加到环境变量
将hbase添加到环境变量/etc/profile中,配环境变量方便使用指令:
nano /etc/profile内容:
export HBASE_HOME=/home/hbase/hbase-1.2.1
export PATH=$HBASE_HOME/bin:$PATH
export HBASE_MANAGES_ZK=true
export HBASE_CLASSPATH=/home/hbase/hbase-1.2.1/conf(4)修改配置文件hbase-env.sh
nano /home/hbase/hbase-1.2.1/conf/hbase-env.sh
内容:
export JAVA_HOME=/usr/java/jdk1.7.0_80(5)修改配置文件hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.1.100:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master.Hadoop,Slave1.Hadoop,Slave2.Hadoop</value>
</property>
<property>
<name>hbase.temp.dir</name>
<value>/home/hbase/hbase-1.2.1/tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hbase/hbase-1.2.1/tmp/zookeeper</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>(6)修改配置文件regionservers:
nano regionservers将文件内容设置为:
Master.Hadoop
Slave1.Hadoop
Slave2.Hadoop(7)Hbase复制到从节点
差不多要成功了,别忘了最后一步!
scp -r /home/hbase/hbase-1.2.1 root@192.168.1.101:/home/hbase/
scp -r /home/hbase/hbase-1.2.1 root@192.168.1.102:/home/hbase/(8)验证Hbase
1、用jps命令看进程对不对。
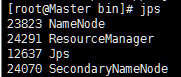
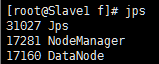
2、测试Web访问
http://Master.Hadoop:8088/
http://Master.Hadoop:50070/
http://Master.Hadoop:60010/
CentOS7.0+Hadoop2.7.2+Hbase1.2.1搭建教程的更多相关文章
- 基于Centos7+Flask+Nginx+uWSGI+Python3的服务器网页搭建教程
之前完成了贴吧签到系统的搭建,笔者想将这个功能分享给更多人使用,所以尝试搭建了一个网页,一路遇到了很多问题,最终解决了,记录下过程分享给大家 首先安装 uWSGI ,和 Nginx 配套使用,具体用途 ...
- Hadoop2.7.5+Hbase1.4.0完全分布式
Hadoop2.7.5+Hbase1.4.0完全分布式一.在介绍完全分布式之前先给初学者推荐两本书:<Hbase权威指南>偏理论<Hbase实战>实战多一些 二.在安装完全分布 ...
- YARN环境搭建 之 一:CentOS7.0系统配置
一.我缘何选择CentOS7.0 14年7月7日17:39:42发布了CentOS 7.0.1406正式版,我曾使用过多款Linux,对于Hadoop2.X/YARN的环境配置缘何选择CentOS7. ...
- CentOS7.0分布式安装HADOOP 2.6.0笔记-转载的
三台虚拟机,IP地址通过路由器静态DHCP分配 (这样就无需设置host了). 三台机器信息如下 - 1. hadoop-a: 192.168.0.20 #master 2. ha ...
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- 云服务器 Centos7.0 部署
CentOS安装jdk的三种方法 http://www.mamicode.com/info-detail-613410.html centos Linux下安装Tomcat和发布Java的web程序 ...
- centos7.0 下安装jdk1.8
centos7.0这里安装jdk1.8采用yum安装方式,非常简单. 1.查看yum库中jdk的版本 [root@localhost ~]# yum search java|grep jdk 2.选择 ...
- centos7.0 安装redis集群
生产环境下redis基本上都是用的集群,毕竟单机版随时都可能挂掉,风险太大.这里我就来搭建一个基本的redis集群,功能够用但是还需要完善,当然如果有钱可以去阿里云买云数据库Redis版的,那个还是很 ...
- centos7.0 安装字体库
最近在centos7.0下用itextpdf将word文档转成pdf时出现字体丢失的情况.网上找了很多资料,各式各样的原因和解决方法.后来经过一番测试发现是centos7.0 minimal没有安装相 ...
随机推荐
- Gym - 101102D Rectangles (单调栈)
Given an R×C grid with each cell containing an integer, find the number of subrectangles in this gri ...
- CentOS7.6部署ceph环境
CentOS7.6部署ceph环境 测试环境: 节点名称 节点IP 磁盘 节点功能 Node-1 10.10.1.10/24 /dev/sdb 监控节点 Node-2 10.10.1.20/24 /d ...
- Iptables-linux服务器做路由转发
https://blog.csdn.net/liang_operations/article/details/80747510 实现内部服务器C可以经过服务器B进行上网. 3.1服务器双网卡,一块配置 ...
- JavaScript数组的方法 | 学习笔记分享
数组 数组的四个常用方法 push() 该方法可以向数组的末尾添加一个或多个元素,并返回数组的新长度 可以将要添加的元素作为方法的参数传递,这些元素将会自动添加到数组的末尾 pop() 该方法可以删除 ...
- 服务发现之eureka
一.什么是服务发现? 问题: 我们现在有多少个服务? 服务越来越多时,服务 URL 配置管理变得非常乱 服务对外的地址变了,其他所有有使用到的服务都要改地址 增加服务,增加服务实例等,都要做运维工作 ...
- 使用PAC file结合ATS控制访问
介绍:前面已经介绍了ATS的安装和PAC文件的写法格式,现在把nginx端口转发,pac file访问控制和ATS代理结合起来分别控制不同的机器访问不同URL权限的目的 效果如下 一.使用nginx端 ...
- FPM简介(定制rpm包)
FPM简介 fpm是生成rpm包的工具.rpm包的制作,采用fpm工具完成,FPM非常易用,此命令可以把rpm包的安装.卸载做得更加优雅,在安装前可以做一些准备工作,安装后可以做一些收尾工作,在卸载前 ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- webpack 实时编译typescript与scss
webpack.config.js const path = require('path'); const CopyWebpackPlugin = require('copy-webpack-plug ...
- Java并发-几种常见的锁
这几天在忙着投提前批内推,前面看的好多东西没有总结,正好这两天补上顺带复习一下 synchronized:Java之重型锁