使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hadoop主要服务于之前没有完成的项目:网站日志流量分析系统(该系统目前用虚拟机实现了离线分析模块,实时分析由于资源问题尚未完成,我想这次不担心了)考虑到阿里云ECS对于我个人来说,成本有点太高了,但是自从学了Dokcer以后,我再也不怕了,用这一台就够啦,哈哈哈哈……下面开始吧!安装过程较长,so please be patient!
一、环境准备
①阿里云轻量应用服务器(学生价很实惠的~),我的配置:1C、2G、40G(足够了)
②CentOS7.3,内核4.4(可用uname -r 查看,自带的3.10.x可能会导致Docker运行不稳定,鄙人踩过的坑,可参考鄙人另一篇博客:从centos7镜像到搭建kubernetes集群(kubeadm方式安装)里面有关于升级内核命令)
③Docker版本:19.03.5(安装参考官网即可,镜像加速可参考鄙人另一篇博客:Docker配置阿里云镜像源)
④JDK1.8:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
⑤Hadoop:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz(ps:source为源码包,binary为安装包)
二、构建ssh-centos镜像
1、创建对应目录
mkdir centos-ssh
cd centos-ssh
vim Dockerfile #这里docker build时缺省名为Dockerfile
2、编写Dockerfile
FROM centos # 镜像的作者
MAINTAINER xiedong # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装openssh-clients
RUN yum install -y openssh-clients # 添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE
CMD ["/usr/sbin/sshd", "-D"]
3、构建镜像
docker build -t 'xd/centos-ssh' . #注意别忘记末尾的点
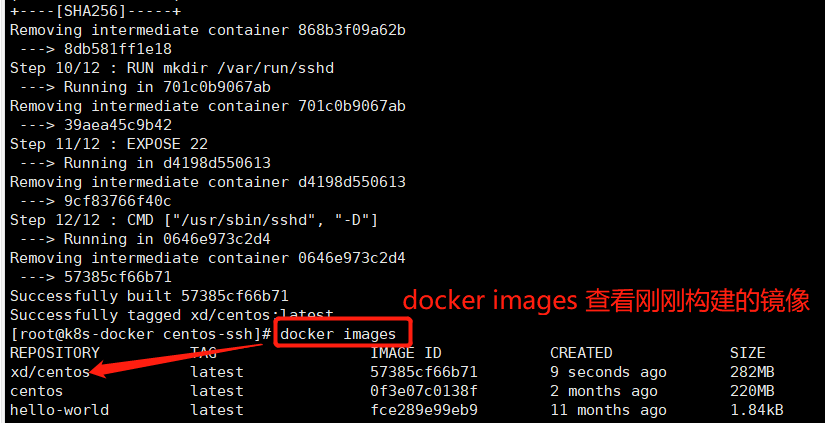
三、构建jdk1.8镜像
1、创建目录并上传JDK至该目录
mkdir centos-ssh-root-jdk
cd centos-ssh-root-jdk

2、编辑Dockefile(docker build 缺省名为Dockerfile)
#基于上一个ssh镜像构建
FROM xd/centos-ssh
#拷贝并解压jdk
ADD jdk-8u231-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1..0_231 /usr/local/jdk1.
ENV JAVA_HOME /usr/local/jdk1.
ENV PATH $JAVA_HOME/bin:$PATH
3、构建jdk1.8镜像
docker build -t 'xd/centos-jdk' .
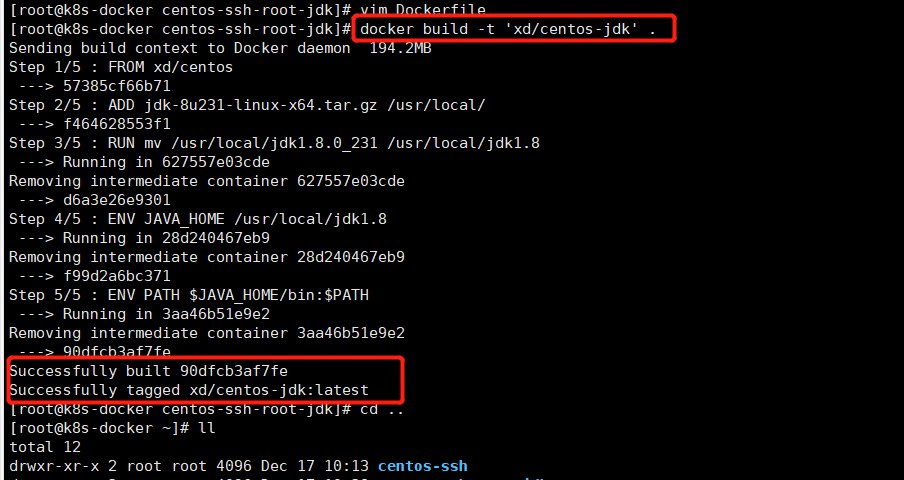
四、构建hadoop镜像
1、创建目录并上传Hadoop安装包
mkdir centos-ssh-root-jdk-hadoop
cd centos-ssh-root-jdk-hadoop

2、编写Dockerfile
FROM xd/centos-jdk
ADD hadoop-2.7..tar.gz /usr/local
RUN mv /usr/local/hadoop-2.7. /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
3、构建镜像
docker build -t 'xd/hadoop' .
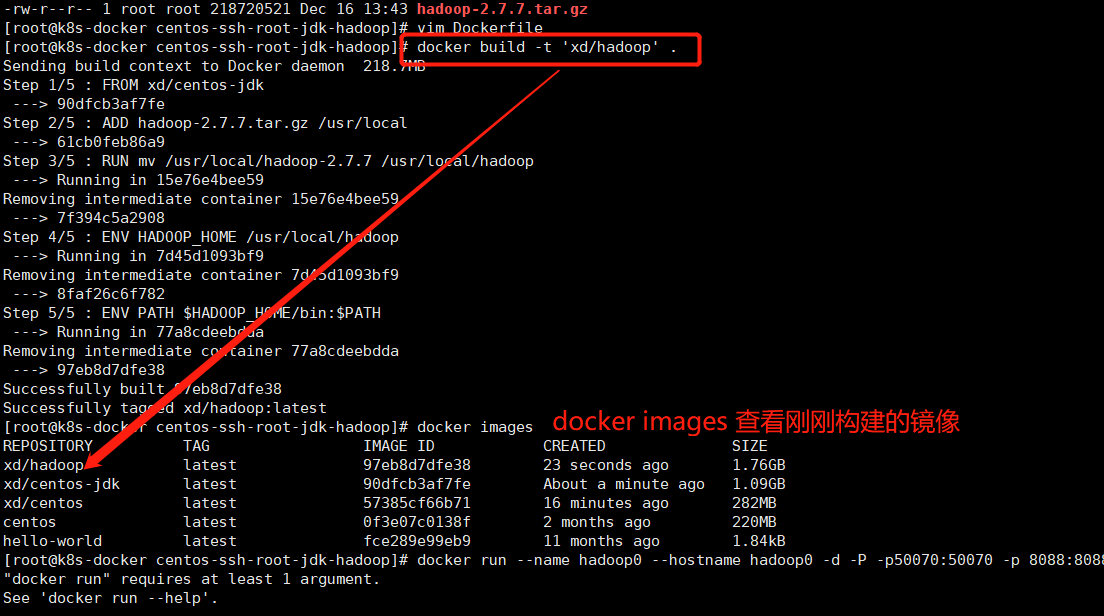
五、启动容器并固定IP
1、集群规划
主节点:hadoop0 ip:192.168.2.10
从节点1:hadoop1 ip:192.168.2.11
从节点2:hadoop2 ip:192.168.2.12
ps:这里Docker容器重启后IP会发生变化,所以需要给Docker设置固定IP,使用pipework给docker固定ip
2、启动容器
分别为hadoop0、hadoop1、hadoop2
docker run --name hadoop0 --hostname hadoop0 -d -P -p : -p : xd/hadoop #hadoop0对外开放端口50070和8088
docker run --name hadoop1 --hostname hadoop1 -d -P xd/hadoop
docker run --name hadoop2 --hostname hadoop2 -d -P xd/hadoop
docker ps查看刚刚启动的3个容器

3、固定IP
docker容器重启以后ip会发生变化,所以这里通过pipework给docker固定ip,pipework下载地址:https://github.com/jpetazzo/pipework
①上传、解压并改名该压缩包
unzip pipework-master.zip
mv pipework-master pipework
cp -rp pipework/pipework /usr/local/bin/
②安装birdge-utils
yum -y install bridge-utils
③创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/ dev br0
④设置固定IP
pipework br0 hadoop0 192.168.2.10/
pipework br0 hadoop1 192.168.2.11/
pipework br0 hadoop2 192.168.2.12/
⑤验证
分别ping这3个ip即可验证ip是否设定成功

六、集群搭建
ps:以下操作均是对hadoop0主节点配置(可参考博主之前写的虚拟机内搭建的Hadoop集群:Hadoop之伪分布式安装)----还是那条路子:配置主机名与IP映射、ssh免密登录……等。
1、进入容器
docker exec -it hadoop0 /bin/bash (当然也可以用attach进入)
2、配置主机名与IP映射(3个节点)
192.168.2.10 hadoop0
192.168.2.11 hadoop1
192.168.2.12 hadoop2
3、ssh免密登录
ssh-keygen
#剩下的一路回车即可
ssh-copy-id hadoop0
#根据提示输入yes以及主机密码,开头我们设置的是root/root
ssh-copy-id hadoop1
ssh-copy-id hadoop2
4、hadoop的相关配置
进入/usr/local/hadoop/etc/hadoop目录,涉及的配置文件有:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
①配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1. #修改JAVA_HOME
②core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value></value>
</property>
</configuration>
③hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
④yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
⑤mapred-site.xml(需要修改模板:mv mapred-site.xml.template mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、格式化hadoop并启动伪分布式hadoop
进入进入到/usr/local/hadoop目录下
①格式化(格式化操作不能重复执行。如果一定要重复格式化,带参数-force即可)
bin/hdfs namenode -format
注意:在执行的时候会报错,是因为缺少which命令,安装即可 执行下面命令安装
yum install -y which

②启动伪分布hadoop
sbin/start-all.sh
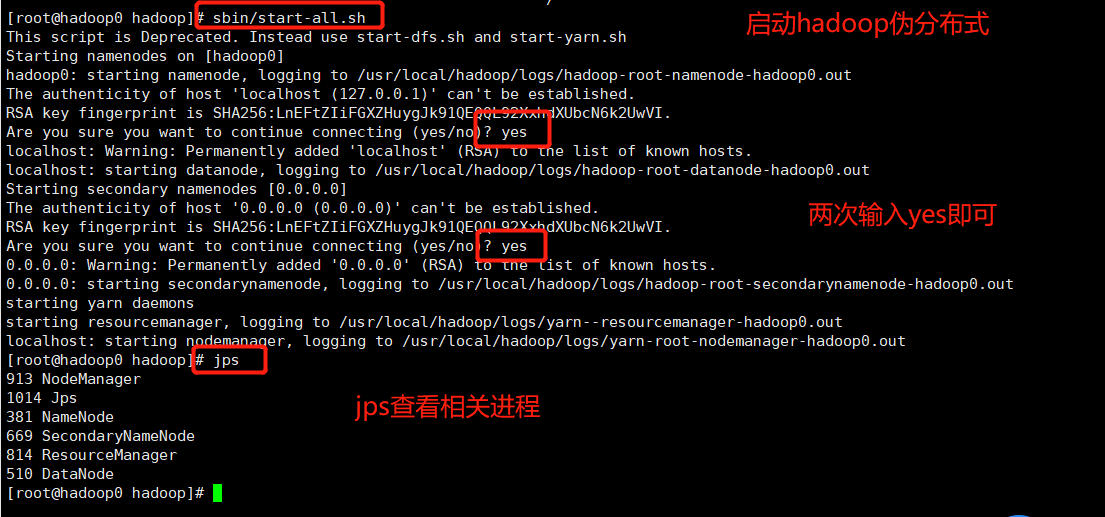
6、完全分布式hadoop搭建
进入/usr/local/hadoop
①停止上一步的伪分布式hadoop
sbin/stop-all.sh
②指定nodemanager的地址,修改文件yarn-site.xml
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
③修改hadoop0中hadoop的一个配置文件etc/hadoop/slaves
删除原来的所有内容,修改为如下
hadoop1
hadoop2
④拷贝至其他两个节点
scp -rq /usr/local/hadoop/ hadoop1:/usr/local/
scp -rq /usr/local/hadoop/ hadoop2:/usr/local/
⑤启动hadoop分布式集群服务
执行sbin/start-all.sh
ps:在执行的时候会报错,是因为两个从节点缺少which命令,安装即可(yum install -y which)
7、验证完全分布式集群是否正常
①hadoop0主节点需要有以下进程
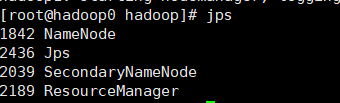
②hadoop1从节点需要有以下进程
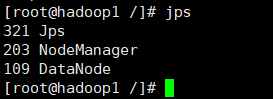
③hadoop2从节点需要有以下进程
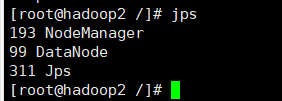
七、wordcount单词计数验证集群服务
1、创建本地文件并写入任意内容
vi a.txt
hello hadoop
hello spark
hello flink
2、上传该文件至HDFS并验证是否上传成功
hdfs dfs -put a.txt /
hadoop fs -ls /

3、提交job程序至hadoop集群
cd /usr/local/hadoop/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.7..jar wordcount /a.txt /out
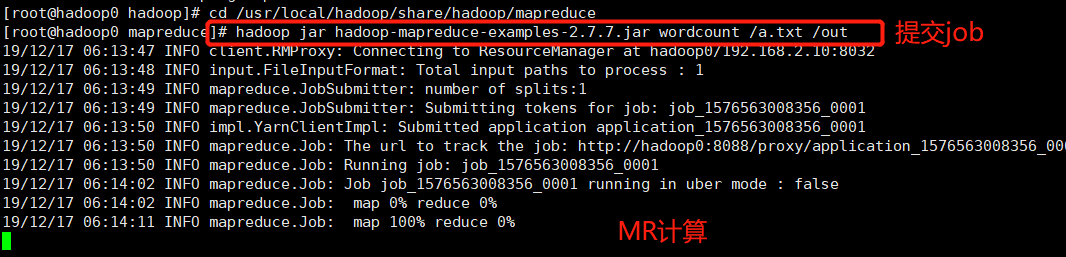
4、查看计算结果
hadoop fs -ls /out
hadoop fs -cat /out/part-r-
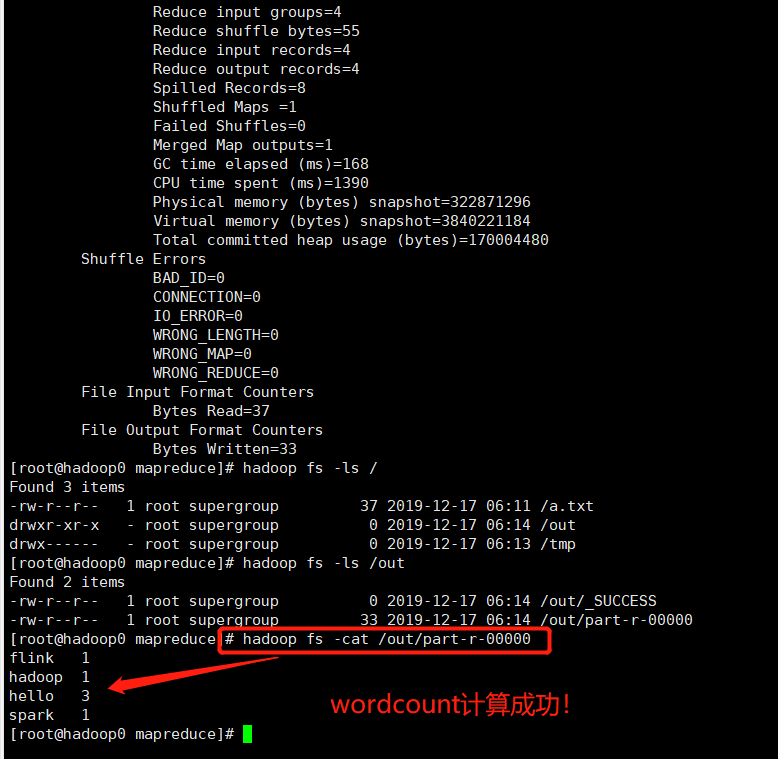
至此、使用Docker搭建Hadoop集群成功!
八、浏览器访问Hadoop集群服务
1、docker ps查看主节点容器

启动的容器的时候指定了对外开放端口:50070和8088
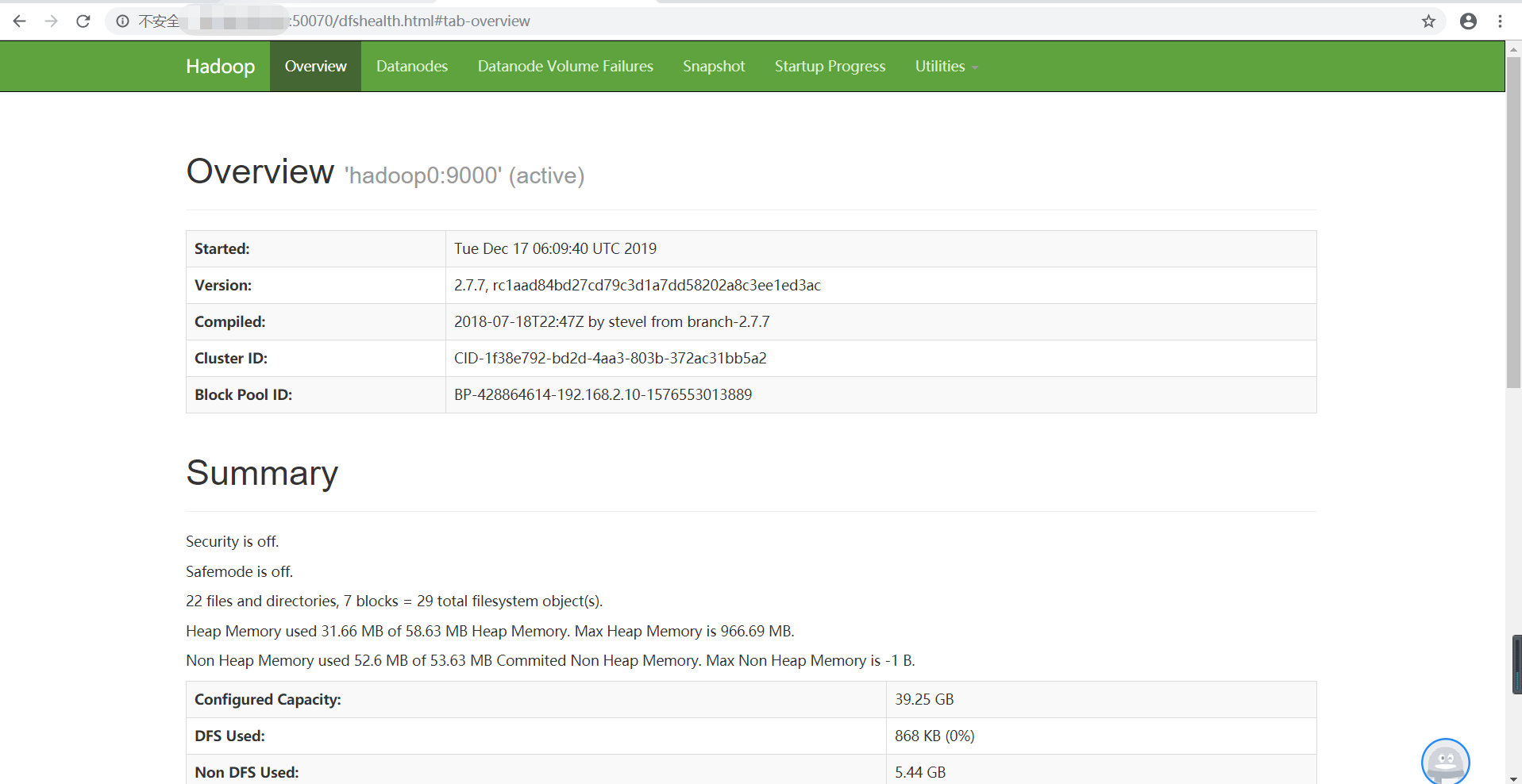
2、浏览器访问:http://IP:50070/dfshealth.html#tab-overview即可看到以界面
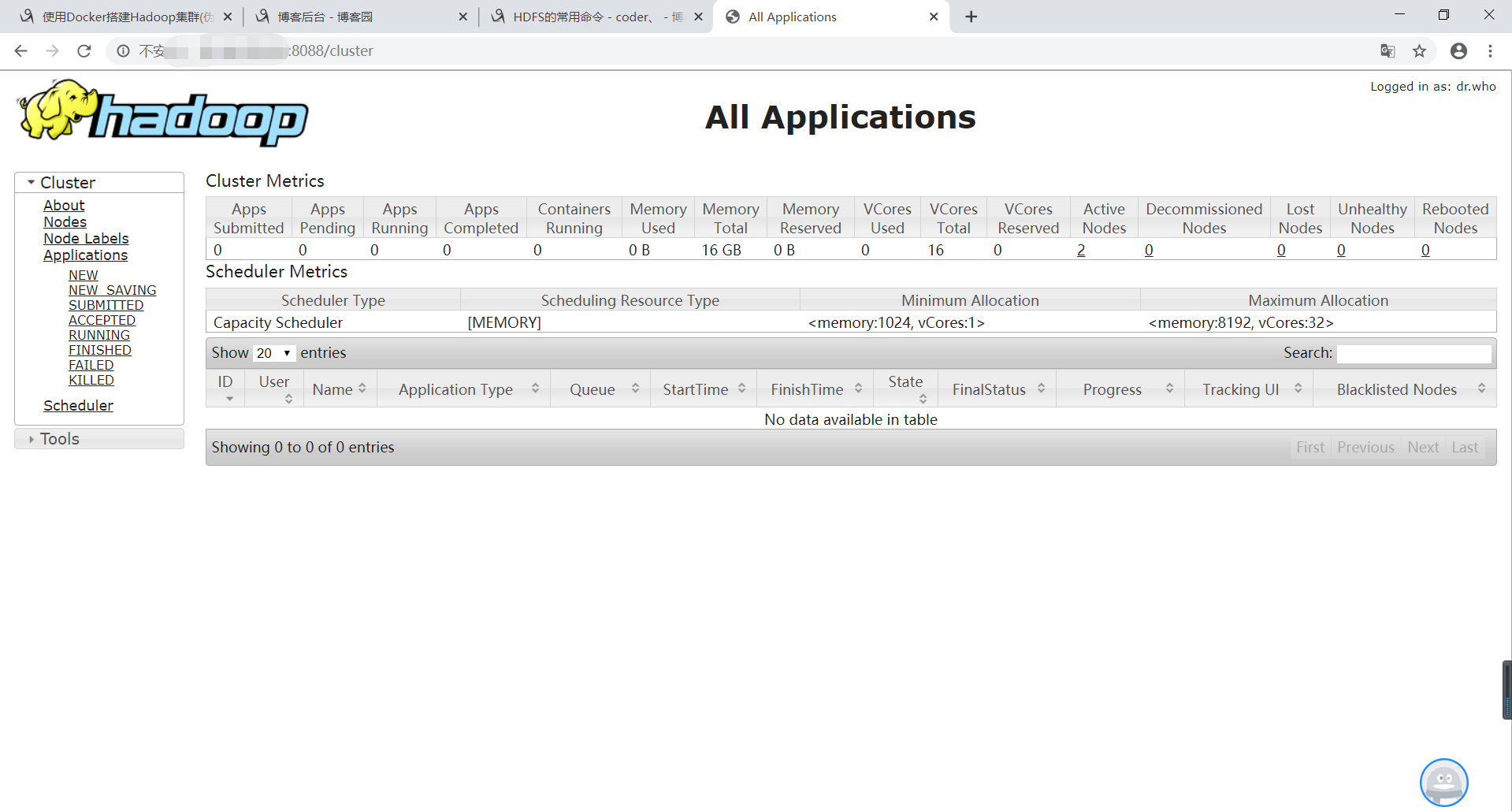
3、浏览器访问:http://IP:8088/cluster
九、重启容器注意点
1、停止3个容器
docker stop hadoop0
docker stop hadoop1
docker stop hadoop2
2、启动3个容器
docker start hadoop0
docker start hadoop1
docker start hadoop2
3、固定IP
pipework br0 hadoop0 192.168.2.10/
pipework br0 hadoop1 192.168.2.11/
pipework br0 hadoop2 192.168.2.12/
4、主机名与IP映射
ps:每次修改比较麻烦,干脆一个脚本:runhosts.sh
#!/bin/bash
echo 192.168.2.10 hadoop0 >> /etc/hosts
echo 192.168.2.11 hadoop1 >> /etc/hosts
echo 192.168.2.12 hadoop2 >> /etc/hosts
chmod +x runhosts.sh
scp runhosts.sh hadoop1:~
scp runhosts.sh hadoop2:~
./runshots.sh
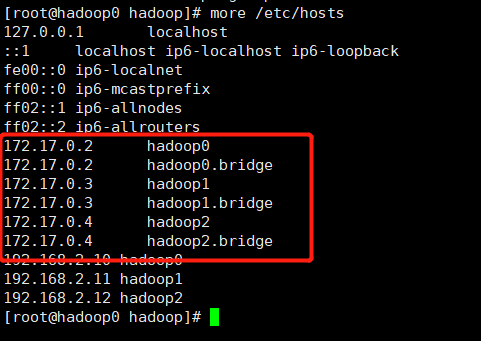
5、查看是否映射成功
有一些docker版本中不会在hosts文件中自动生成下面这些映射,所以我们才在这里手工给容器设置固定ip,并设置主机名和ip的映射关系
6、启动hadoop集群
sbin/start-all.sh
参考自:https://blog.csdn.net/xu470438000/article/details/50512442(如有侵权,请联系删除)
使用Docker搭建Hadoop集群(伪分布式与完全分布式)的更多相关文章
- docker搭建Hadoop集群
一个分布式系统基础架构,由Apache基金会所开发. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储. 首先搭建Docker环境,Docker版本大于1.3. ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 在搭建Hadoop集群环境时遇到的一些问题
最近在学习搭建hadoop集群环境,在搭建的过程中遇到很多问题,在这里做一些记录.1. SSH相关的问题 问题一: ssh: connect to host localhost port 22: Co ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- docker安装hadoop集群
docker安装hadoop集群?图啥呢?不图啥,就是图好玩.本篇博客主要是来教大家如何搭建一个docker的hadoop集群.不要问 为什么我要做这么无聊的事情,答案你也许知道,因为没有女票.... ...
- Docker 搭建 etcd 集群
阅读目录: 主机安装 集群搭建 API 操作 API 说明和 etcdctl 命令说明 etcd 是 CoreOS 团队发起的一个开源项目(Go 语言,其实很多这类项目都是 Go 语言实现的,只能说很 ...
随机推荐
- RN开发-IDE和API
一.开发工具 1.Visual Studio Code:微软IDE,轻量级,只有30+M大小 2.nuclide :仅支持Mac 3.WebStorm : JavaScript开发工具(IDE) 二. ...
- HDU 1542 Atlantis(扫描线算法)
题意:给出n个矩形的左下角左边和右上角坐标,求这n个矩形的面积并 原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=1542 典型的扫描线算法的题目 什么是 ...
- python爬虫匹配实现步骤
import requests,re url='https://movie.douban.com/top250' urlcontent=requests.get(url).text #正则 ''' 实 ...
- MySQL5.5升级至5.7
一.下载免安装MySQL5.7包 下载页面 下载链接 二.替换mysql的安装目录 解压mysql5.7 tar -zxf mysql-5.7.23-linux-glibc2.12-x86_64.ta ...
- 记录 shell学习过程(9)正则表达式 转自树明聊运维
正则表达式 正则表达式介绍 特殊字符 POSIX特殊字符 一.正则表达式介绍 正则表达式是一种文本模式匹配,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符") ...
- C short类型的内存分析
#include<stdio.h> #include<limits.h> void main(){ //printf("short%d, int%d, long%d ...
- sendmail邮件服务器
安装sendmail之前 我们要先搭建一个DNS服务器用来解析邮件 下图是配置好的DNS正向解析记录和反向解析记录 正向 反向 DNS配置好之后我们就来安装sendmail服务 然后再安装sendma ...
- js面向对象的程序设计 --- 中篇(创建对象) 之 原型模式
·原型模式 我们创建的每一个函数都由一个prototype(原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型的所有 实例共享的属性和方法. 如果按照字面意思来理解,那 ...
- Java之字符串替换replace()
replace(char oldChar, char newChar)返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 而生成的 import java.uti ...
- Python的深拷贝、浅拷贝
浅拷贝 定义:浅拷贝只是对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值. 浅拷贝的特点: 公用一个值: 这两个变量的内存地址一样: 对其中一个变量的值改变,另外一个变量的值也会改 ...