C语言递归,非递归实现翻转链表
翻转链表作为,链表的常用操作,也是面试常遇到的。
分析
非递归分析:
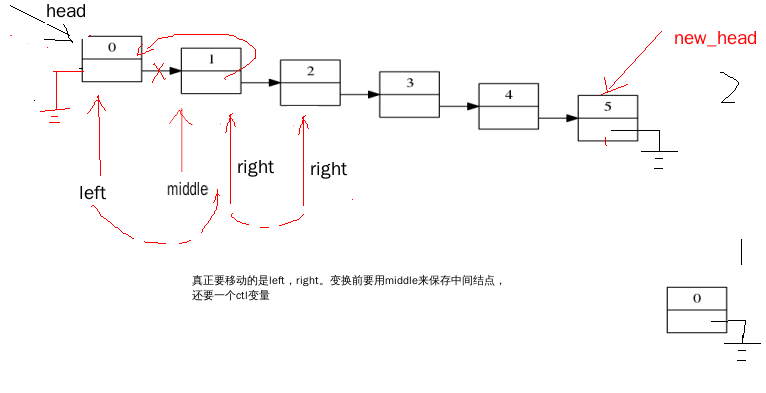
非递归用的小技巧比较多,很容易出错。
递归分析比较简单,在代码里面
代码:
#include<stdio.h>
#include<stdlib.h>
typedef int elemtype;
typedef struct node{
elemtype element;
struct node*next;//写成node* next;node * next;node *next;也是可以的,为了方便阅读,以后统一写成elemtype* element。'*',';',',''=','->'等等这些特殊意义的关键字符语法规则差不多,本身具有分割意义,两旁加空格与不加空格的意义是一致的,也就是说空格对这些特殊字符是不起作用的,而解析编译器,运行器也不是利用空格来分割的;标志符是不能用这些字符,为了方便阅读,不会看的一驼屎,最好在这些特殊的字符两旁加空格。
}node;//这个类型名与其的结构体名可以一样,不矛盾。 /*Function:将链表所有结点从头结点顺序打印,遍历链表。traverse_linkedList
*遍历一种数据机构,进去看一看,给人说一说,一般遍历打印里面的数据,知道是进去,可以拿到里面的数据。
*这种数据结构有很多数据元素,但每次遍历只能访问一个元素,因此要循环,而且要访问所有的结点,必须有一种机制从一个结点跳到另一个结点。
*@paramb:node* phead :链表首地址,首结点地址。
*/
void traverse_linkedList(node* phead){
node *p=phead ;//定义一个跳转控制指针
if (NULL == p){
printf("亲,链表为空\n");
return ;
}
else{
while(NULL != p){ printf("%d\n",p -> element);//访问结构体的数据,可以用: 其结构体变量.成员变量;还可以:指向这个结构体的指针 -> 成员变量
p = p -> next ;
}
} }
/*Function:翻转链表(非递归) reverse_linkedList
*param:node** phead //参数意义:保存链表指针变量的地址
*return: void
*
*知识点:node** p;p代表链表指针变量的地址。*p才是链表。**p 代表结点(可以认为"*"具有解析功能)
*整体的思路:重整结点的关系,原来从左指向右,翻转后从右指向左;原来指向头结点,翻转后指向尾结点
*
*时间复杂度:O(n)
*
*
* */
void reverse_linkedList(node** phead){//存链表头的指针变量的地址传过来,旨在能改变这个变量,指针本质上是存地址的变量。
node *pLeft,*pRight,*pMiddle;//定义三个指针: 左中右,pRight:作移动。
pLeft=pRight=*phead;
//空链表或者只有一个结点
if(NULL == pLeft || NULL == ( pLeft -> next)){
return ; }else{
//头的结点的处理
pLeft = *phead ;
pRight = (*phead) -> next ; //' ->'优先级最高
pLeft -> next = NULL ; //循环控制条件
node *ctl=pRight;
while(NULL != ctl){
pMiddle = pRight ;// 在移动前,先保存
pRight = pRight -> next ;// pRight移动到下一个结点
ctl = pMiddle -> next; //在变换关系前,先把控制的信息存起来
pMiddle -> next = pLeft ; //变换关系
pLeft = pMiddle ; // p变换
} *phead = pLeft ; //指向链表头指针变量,指向新的头。
}
}
/*
*Function:翻转链表(递归) reverse_recursive_linkedList
*param:node* head
*return: node*
*
*知识点:
*递归:自身调用自身;出口。
*思考:
*
*如果链表是空链表或者只有一个结点,就可以直接的返回表头;如果是两个结点以上链表,调用自身,拿到子结点的表头,再重建他们的关系。
*
* */
node* reverse_recursive_linkedList(node * head){
if(head == NULL || head -> next == NULL){
return head ;
}
else{
node* second = head -> next ;
node* new_head = reverse_recursive_linkedList(second);
second -> next = head ;
head -> next = NULL ;
return new_head ;
}
}
int main()
{
node *p , *q , *head;//仅仅定义了几个指针变量,系统做了哪些工作呢?开辟这些指针变量类型所需的空间。若没有初始值一般由系统随机分配值,还没有指向真正的结点,也就是说 p -> 成员变量是没有意义的。会报""; node 类型的声明,告诉系统作对应的语法检查,该怎么处理指针指向的内容。
// insert 10 nodes
//创建结点,结点本质上是数据块,这些数据是占用空间的,有了储存空间,就有了数据载体。所以开辟空间是创建数据的关键,然后告诉系统你怎么来处理这块空间,最后空间开辟成功。
p = q = (node* )malloc(sizeof(node)) ;//与” 数据类型 标识符“ 创建的差别,无标识符,要手动开空间,并提取信息。标识符功能:解析+地址。
head = p ;
p -> element = ;
int i=;
for ( i = ;i < ; i++){ q = (node* )malloc(sizeof(node)) ;
q -> element = i + ;
p -> next = q ;
p = q ; } traverse_linkedList(head);
reverse_linkedList(&head);//&只能作取址用,没有解析功能。
traverse_linkedList(head);
traverse_linkedList(reverse_recursive_linkedList(head));
}
本人在重拾C,很多东西看是熟悉而又陌生,所以注释比较多一点,仅供参考,不爽直接忽略,
C语言递归,非递归实现翻转链表的更多相关文章
- Reverse Linked List 递归非递归实现
单链表反转--递归非递归实现 Java接口: ListNode reverseList(ListNode head) 非递归的实现 有2种,参考 头结点插入法 就地反转 递归的实现 1) Divide ...
- 【数据结构】——搜索二叉树的插入,查找和删除(递归&非递归)
一.搜索二叉树的插入,查找,删除 简单说说搜索二叉树概念: 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 若它的右 ...
- java:合并两个排序的链表(递归+非递归)
//采用不带头结点的链表 非递归实现 public static ListNode merge(ListNode list1,ListNode list2){ if(list1==null) retu ...
- Java实现二叉树的创建、递归/非递归遍历
近期复习数据结构中的二叉树的相关问题,在这里整理一下 这里包含: 1.二叉树的先序创建 2.二叉树的递归先序遍历 3.二叉树的非递归先序遍历 4.二叉树的递归中序遍历 5.二叉树的非递归中序遍历 6. ...
- 二叉树的先序、中序以及后序遍历(递归 && 非递归)
树节点定义: class TreeNode { int val; TreeNode left; TreeNode right; TreeNode(int x) { val = x; } } 递归建立二 ...
- 二叉树——遍历篇(递归/非递归,C++)
二叉树--遍历篇 二叉树很多算法题都与其遍历相关,笔者经过大量学习.思考,整理总结写下二叉树的遍历篇,涵盖递归和非递归实现. 1.二叉树数据结构及访问函数 #include <stdio.h&g ...
- 树的广度优先遍历和深度优先遍历(递归非递归、Java实现)
在编程生活中,我们总会遇见树性结构,这几天刚好需要对树形结构操作,就记录下自己的操作方式以及过程.现在假设有一颗这样树,(是不是二叉树都没关系,原理都是一样的) 1.广度优先遍历 英文缩写为BFS即B ...
- 全排列问题(递归&非递归&STL函数)
问题描述: 打印输出1-9的所有全排序列,或者打印输出a-d的全排列. 思路分析: 将每个元素放到余下n-1个元素组成的队列最前方,然后对剩余元素进行全排列,依次递归下去. 比如:1 2 3 为例首先 ...
- 二叉树的递归,非递归遍历(java)
import java.util.Stack; import java.util.HashMap; public class BinTree { private char date; private ...
- 二叉树的递归,非递归遍历(C++)
二叉树是一种非常重要的数据结构,很多其它数据结构都是基于二叉树的基础演变而来的.对于二叉树,有前序.中序以及后序三种遍历方法.因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历不仅容易 ...
随机推荐
- iOS UIWebView 拦截点击事件(双击缩放)
在平时的开发中,要使用到webview,但类似微信的webview在数据没有加载完成的时候 双击屏幕,webview不会缩放,其实实现这个功能很简单 代码是用swift写的 class YYSimpl ...
- ssh整合问题总结--使用HibernateTemplate实现数据分页展示
在进行大量的数据展示时,必须要使用分页查询,第一次使用在SSH框架整合中使用分页查询,遇到了一些问题,下面以我练习的项目为例详细介绍,如何在Spring+hibernate(+action)的环境下完 ...
- SQLServer学习笔记系列11
一.写在前面的话 身体是革命的本钱,这句放在嘴边常说的话,还是拿出来一起共勉,提醒一起奋斗的同僚们,保证睡眠,注意身体!偶尔加个班,也许不曾感觉到身体发出的讯号,长期晚睡真心扛不住!自己也制定计划,敦 ...
- web开发中不同设备浏览器的区分
通常区分不同设备浏览器是用JavaScript中的navigator.userAgent.toLowerCase()方式获取浏览器的userAgent信息 //使用javascript判断是否是iPh ...
- [Java IO]01_File类和RandomAccessFile类
File类 File类是java.io包中唯一对文件本身进行操作的类.它可以进行创建.删除文件等操作. File类常用操作 (1)创建文件 可以使用 createNewFille() 创建一个新文 ...
- 30 个惊艳的 Bootstrap 扩展插件
Bootstrap 是快速开发Web应用程序的前端工具包.它是一个CSS和HTML的集合,它使用了最新的浏览器技术,给你的Web开发提供了时尚的版式,表单,buttons,表格,网格系统等等. Boo ...
- 【原创】kafka client源代码分析
该包下只有一个文件:ClientUtils.scala.它是一个object,里面封装了各种client(包括producer,consumer或admin)可能会用到的方法: 1. fetchTop ...
- WPF筛选、排序和分组
可以通过CollectionViewSource或者CollectionView对视图进行排序.筛选和分组. 一.通过CollectionViewSource listingDataView是Coll ...
- python中global 和 nonlocal 的作用域
python引用变量的顺序: 当前作用域局部变量->外层作用域变量->当前模块中的全局变量->python内置变量 . 一 global global关键字用来在函数或其他局部作用域 ...
- 转载:《TypeScript 中文入门教程》 14、输入.d.ts文件
版权 文章转载自:https://github.com/zhongsp 建议您直接跳转到上面的网址查看最新版本. 介绍 当使用外部JavaScript库或新的宿主API时,你需要一个声明文件(.d.t ...