Yandex Big Data Essentials Week1 Scaling Distributed File System
GFS Key Components
- components failures are a norm
- even space utilisation
- write-once-read-many
GFS and Hadoop Distributed File System
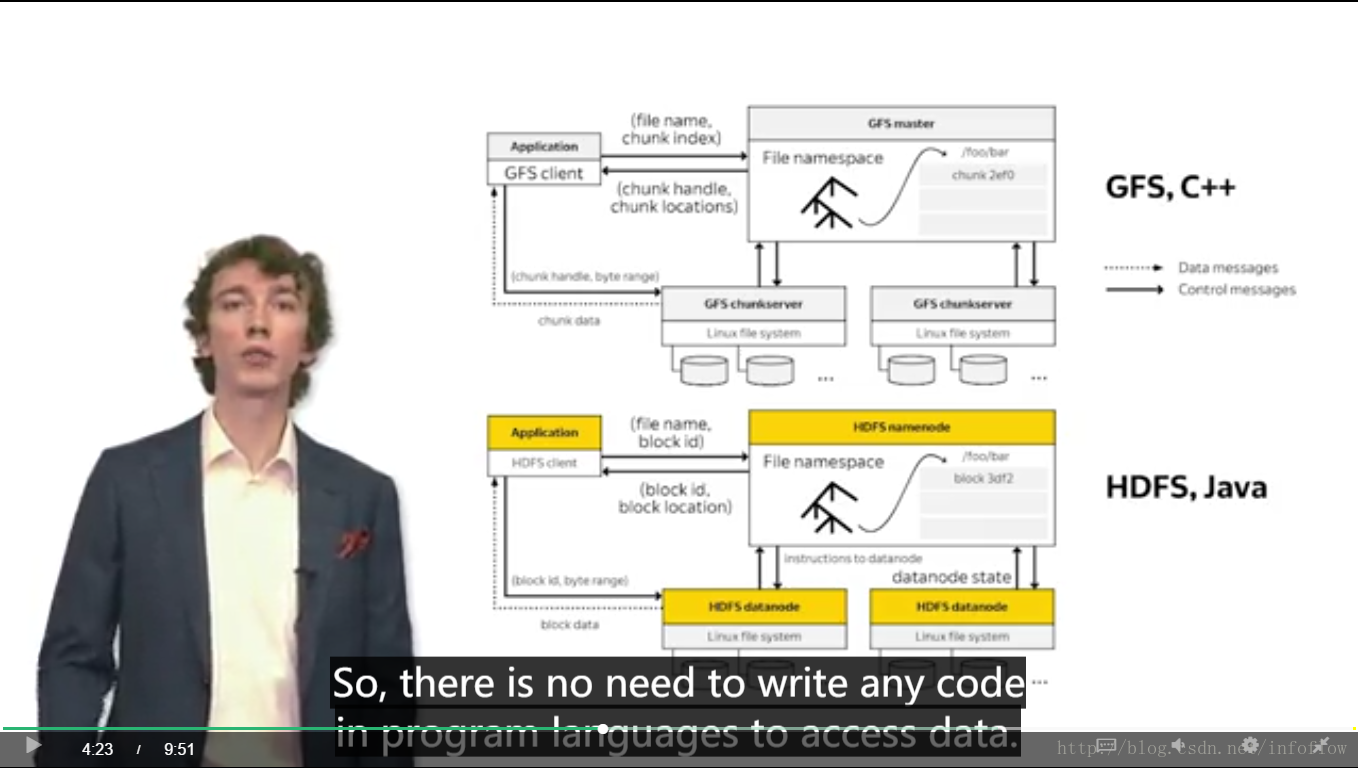
GFS主要分为:Application 、Master、ChannelServer
hdfs主要分为:Appllcation 、 NameNode 、DataNode三部分
how to read file from hdfs
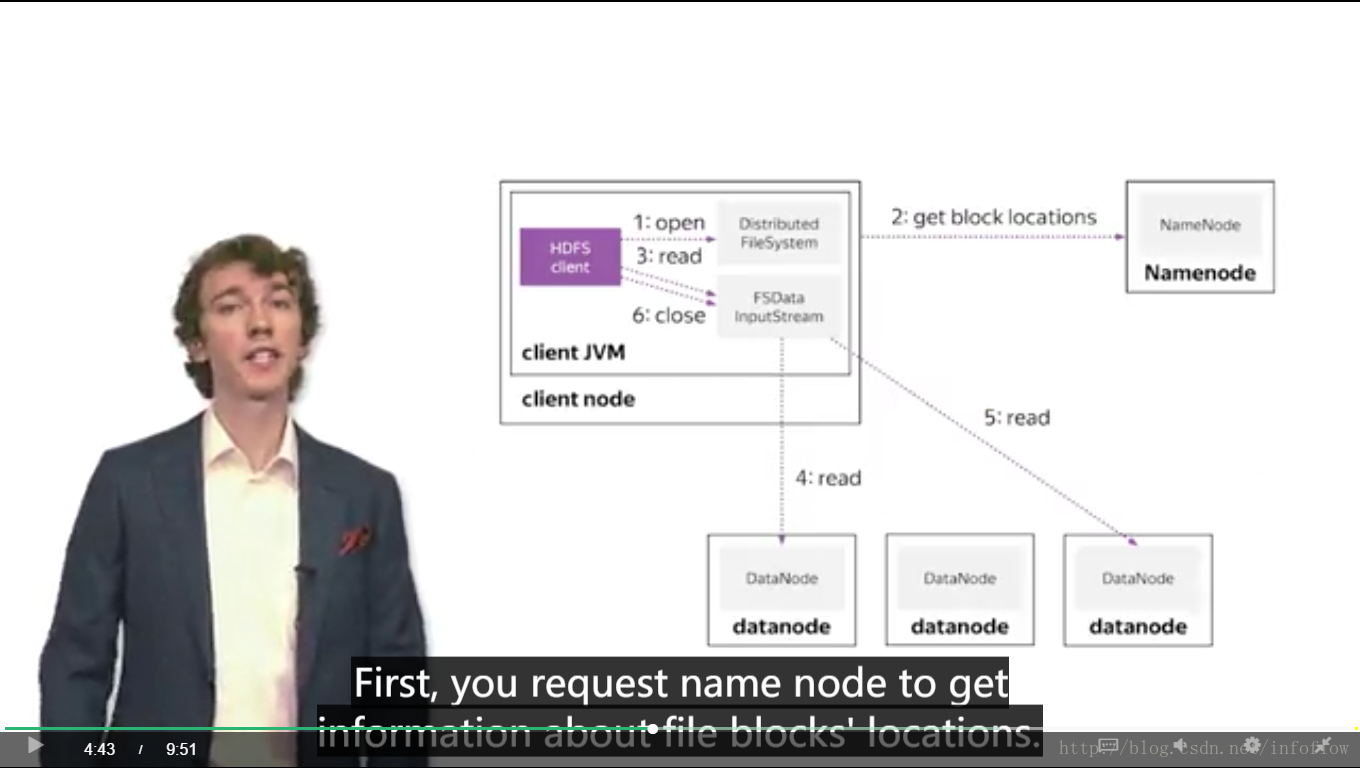
HDFS client 运行在client node 上的client jvm上。
读取文件的流程
- 打开分布式文件系统上的文件
- 从NameNode处取的文件块的位置
- HDFS client将块位置信息传给FSDataInputStream
- FSDataInputStream再从相应的DataNode里面读取其中一个块数据
- FSDataInputStream再从相应的DataNode里面读取另一个块数据
- 关闭FSDataInputStream
写入文件的流程

hdfs client 运行在client jvm上,client jvm运行在client jvm上。
写入文件的流程:
1. HDFS client 在Distributed FileSystem上创建文件
2. DistributedFileSystem 在NameNode上create一个文件
3. HDFS client 通过FSDataInputStream向datanode发送write packet
4. 至少三个datanode组成Pipeline of datanodes写入多个副本
5. datanode向FSDataInpuStream发送ack packet
6. 关闭
In DFS,you can “append” into file,but cannot “modify” a file in the middle. Why?
DFS的核心特性write once read many time 描述了一种数据存储策略。信息一旦写入就不能修改,因为修改操作需要对对底层的存储结构进行修改。如果需要修改分布式文件系统(例如hdfs)中的文件,可以写一份新的同样文件名的数据。旧的文件在hdfs在整理数据的时候会丢弃。
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
Yandex Big Data Essentials Week1 Scaling Distributed File System的更多相关文章
- Yandex Big Data Essentials Week1 Unix Command Line Interface File System exploration
File System Function In computing, a file system or filesystem is used to control how data is stored ...
- Yandex Big Data Essentials Week1 Unix Command Line Interface Processes managing
free displays the total amount of free and used memory free [options] top provides a dynamic real-ti ...
- Yandex Big Data Essentials Week1 Unix Command Line Interface File Content exploration
cat displays the contents of a file at the command line copies or apppend text file into a document ...
- HDFS分布式文件系统(The Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to ...
- HDFS(Hadoop Distributed File System )
HDFS(Hadoop Distributed File System ) HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表 ...
- 5105 pa3 Distributed File System based on Quorum Protocol
1 Design document 1.1 System overview We implemented a distributed file system using a quorum based ...
- Ceph: A Scalable, High-Performance Distributed File System译文
原文地址:陈晓csdn博客 http://blog.csdn.net/juvxiao/article/details/39495037 论文概况 论文名称:Ceph: A Scalable, High ...
- Hadoop ->> HDFS(Hadoop Distributed File System)
HDFS全称是Hadoop Distributed File System.作为分布式文件系统,具有高容错性的特点.它放宽了POSIX对于操作系统接口的要求,可以直接以流(Stream)的形式访问文件 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
随机推荐
- 干货!直击JVM底层 —— Java Class字节码文件解析
目录 前言 如何阅读class文件 基本概念 无符号数&表 常量池 魔数(magic number) & 版本号 常量池 访问标志 类引索&父类引索&接口引索集合 字段 ...
- 【X86】---X86处理器大小端的数据存储验证
之前也关注过大小端的存储,可能时间久了,加之又之前的电脑抽象换成了当前的处理器寄存器的值判断,导致自己总是有点蒙圈.看Spec手册的时候,有时会无法与手册中某个Bit的值与RU/RW工具读出来的对应上 ...
- 3次方的期望dp
osu 是一款群众喜闻乐见的休闲软件. 我们可以把osu的规则简化与改编成以下的样子: 一共有n次操作,每次操作只有成功与失败之分,成功对应1,失败对应0,n次操作对应为1个长度为n的 ...
- springcloud复习1
1.SpringCloud是什么?SpringCloud=分布式微服务架构下的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶. 2.SpringCloud和SpringBoot是什 ...
- Redux 一步到位
简介 Redux 是 JavaScript 状态容器,提供可预测化的状态管理 Redux 除了和 React 一起用外,还支持其它库( jquery ... ) 它体小精悍(只有2kB,包括依赖) 由 ...
- maven常用的远程仓库地址
<mirror> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <url>ht ...
- URL方案最佳做法|高级路由特性 | 精通ASP-NET-MVC-5-弗瑞曼
使 URL整洁和人性化 GET(安全交互)和POST(不安全交互):选用正确的一个.
- C#数字图像处理(十四)击中击不中变换 (Hit-miss)
击中击不中变换定义 击中击不中变换(HMT)需要两个结构元素B1和B2,合成一个结构元素对B=(B1,B2) 一个用于探测图像内部,作为击中部分;另一个用于探测图像外部,作为击不中部分.显然,B1和B ...
- OpenCV里的颜色空间
RGB三原色组合方式是最常用的 RGB色彩空间: R:红色分量 G:绿色分量 B:蓝色分量 HSV色彩空间: H - 色调(主波长). S - 饱和度(纯度/色调). V - 明度(强度). LAB色 ...
- 降级gcc版本
前言 ubuntu16.04版本中默认的gcc版本是5.4,因为有些第三方应用依赖的问题,我不得不降级到5.3,下面是关于gcc的降级操作 部署操作 下载GCC源码(https://ftp.gnu.o ...