MySQL 普通索引和唯一索引的区别
该文为《 MySQL 实战 45 讲》的学习笔记,感谢查看,如有错误,欢迎指正
一、查询和更新上的区别
这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。建议尽量选择普通索引。
1.1 MySQL 的查询操作
- 普通索引
查找到第一个满足条件的记录后,继续向后遍历,直到第一个不满足条件的记录。 - 唯一索引
由于索引定义了唯一性,查找到第一个满足条件的记录后,直接停止继续检索。
普通索引会多检索一次,几乎没有影响。因为 InnoDB 的数据是按照数据页为单位进行读写的,需要读取数据时,并不是直接从磁盘读取记录,而是先把数据页读到内存,再去数据页中检索。
一个数据页默认 16 KB,对于整型字段,一个数据页可以放近千个 key,除非要读取的数据在数据页的最后一条记录,就需要再读一个数据页,这种情况很少,对CPU的消耗基本可以忽略了。
因此说,在查询数据方面,普通索引和唯一索引没差别。
1.2 MySQL 的更新操作
更新操作并不是直接对磁盘中的数据进行更新,是先把数据页从磁盘读入内存,再更新数据页。
- 普通索引
将数据页从磁盘读入内存,更新数据页。 - 唯一索引
将数据页从磁盘读入内存,判断是否唯一,再更新数据页。
由于 MySQL 中有个 change buffer 的机制,会导致普通索引和唯一索引在更新上有一定的区别。
change buffer的作用是为了降低IO 操作,避免系统负载过高。change buffer将数据写入数据页的过程,叫做merge。
如果需要更新的数据页在内存中时,会直接更新数据页;如果数据不在内存中,会先将更新操作记入change buffer,当下一次读取数据页时,顺带merge到数据页中,change buffer也有定期merge策略。数据库正常关闭的过程中,也会触发merge。
对于唯一索引,更新前需要判断数据是否唯一(不能和表中数据重复),如果数据页在内存中,就可以直接判断并且更新,如果不在内存中,就需要去磁盘中读出来,判断一下是否唯一,是的话就更新。change buffer是用不到的。即使数据页不在内存中,还是要读出来。
change buffer 用的是 buffer pool 里的内存,因此不能无限增大。change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
结论:唯一索引用不了change buffer,只有普通索引可以用。
二、change buffer 和 redo log的区别
2.1 change buffer 的适用场景
change buffer 的作用是降低更新操作的频率,缓存更新操作。这样会有一个缺点,就是更新不及时,对于读操作比较频繁的表,不建议使用 change buffer。
因为更新操作刚记录进change buffer中,就读取了该表,数据页被读到了内存中,数据马上就merge到数据页中了。这样不仅不会降低性能消耗,反而会增加维护change buffer的成本。
适用于写多读少的表。
2.2 change buffer 和 redo log 区别
我们举一个例子用来理解 redo log 和 change buffer。我们执行以下 SQL 语句:
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
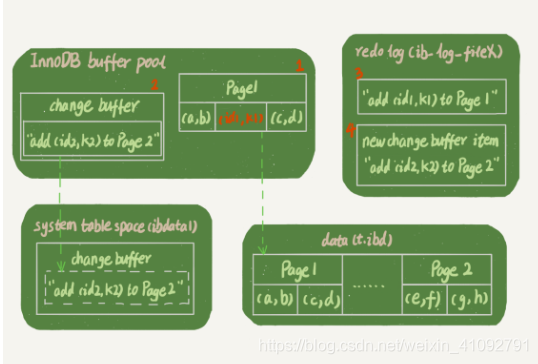
假设,(id1,k1) 在数据页 Page 1 中,(id2,k2) 在数据页 Page 2 中。并且 Page 1 在内存中,Page 2 不在内存中。
执行过程如下:
- 直接向 Page 1 中写入
(id1,k1); - 在
change buffer中记下"向 Page 2 中写入(id2,k2)"这条信息; - 将以上两个动作记入redo log。
做完上面这些,事务就可以完成了。执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘(两次操作合在一起写了一次磁盘),而且还是顺序写的。
这条更新语句,涉及了四个部分:内存、redo log(ib_log_fileX)、 数据表空间(t.ibd)、系统表空间(ibdata1)。
如果要读数据的话,过程是怎样的?
mysql> select * from t where k in (k1, k2);
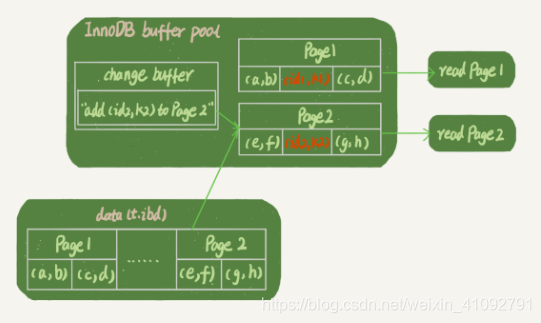
假设读操作在更新后不久,此时内存中还有 Page 1,没有 Page 2,那么读操作就和 redo log 以及 ibdata1 无关了。
- 从内存中获取到 Page 1 上的最新数据
(id1,k1); - 将数据页 Page 2 读入内存,执行
merge操作,此时内存中的 Page 2 也有最新数据(id2,k2);
需要注意的是:
- redo log中的数据,可能还没有 flush 到磁盘,磁盘中的 Page 1 和 Page 2 中并没有最新数据,但我们依然可以拿到最新数据(内存中的 Page 1 就是最新的,Page 2 虽然不是最新的,但是从磁盘读到内存中后,执行了
merge操作,内存中的 Page 2 就是最新的了。) - 如果此时 MySQL 异常宕机了,比如服务器异常掉电,change buffer 中的数据会不会丢?
change buffer中的数据分为两部分,一部分是已经merge到ibdata1中的数据,这部分数据已经持久化,不会丢失。另一部分数据,还在change buffer中,没有merge到ibdata1,分 3 种情况:
(1)change buffer 写入数据到内存,redo log 也已经写入(ib-log-filex),但是未commit,binlog中也没有fsync到磁盘,这部分数据会丢失;
(2)change buffer 写入数据到内存,redo log 也已经写入(ib-log-filex),但是未commit,binlog 已写入到磁盘,这部分不会多丢失,异常重启后会先从 binlog 恢复 redo log,再从 redo log 恢复 change buffer;
(3)change buffer 写入数据到内存,redo log 和 binlog 都已经fsync,直接从redo log 恢复,不会丢失。
redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗
感谢阅读,有兴趣的小伙伴可以关注我的微信公众号DevOps探索之旅,大家一起学习进步

MySQL 普通索引和唯一索引的区别的更多相关文章
- Mysql索引介绍及常见索引(主键索引、唯一索引、普通索引、全文索引、组合索引)的区别
Mysql索引概念:说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要 ...
- Mysql主键索引、唯一索引、普通索引、全文索引、组合索引的区别
原文:Mysql主键索引.唯一索引.普通索引.全文索引.组合索引的区别 Mysql索引概念: 说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不 ...
- MySQL的几个概念:主键,外键,索引,唯一索引
概念: 主键(primary key) 能够唯一标识表中某一行的属性或属性组.一个表只能有一个主键,但可以有多个候选索引.主键常常与外键构成参照完整性约束,防止出现数据不一致.主键可以保证记录的唯一和 ...
- 【MySQL 读书笔记】普通索引和唯一索引应该怎么选择
通常我们在做这个选择的时候,考虑得最多的应该是如果我们需要让 Database MySQL 来帮助我们从数据库层面过滤掉对应字段的重复数据我们会选择唯一索引,如果没有前者的需求,一般都会使用普通索引. ...
- 如何选择普通索引和唯一索引《死磕MySQL系列 五》
系列文章 一.原来一条select语句在MySQL是这样执行的<死磕MySQL系列 一> 二.一生挚友redo log.binlog<死磕MySQL系列 二> 三.MySQL强 ...
- MySQL 普通索引、唯一索引和主索引
1.普通索引 普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度.因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn ...
- MySQL 笔记整理(9) --普通索引和唯一索引,应该怎么选择?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 9) --普通索引和唯一索引,应该怎么选择? 假如你在维护一个市民系统, ...
- MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划
这篇文章主要介绍了MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划的相关资料,需要的朋友可以参考下 一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存 ...
- Sql Server 索引之唯一索引和筛选索引
唯一索引(UNIQUE INDEX) 当主键创建时如果不设置为聚集索引,那么就一定是唯一的非聚集索引.实际上,唯一索引,故名思议就是它要求该列上的值是唯一的.唯一索引能够保证索引键中不包含重复的值, ...
随机推荐
- Browser Security-css、javascript
层叠样式表(css) 调用方式有三种: 1 用<style> 2 通过<link rel=stylesheet>,或者使用style参数. 3 XML(包括XHTML)可以通过 ...
- XSS Cheat Sheet
Basic and advanced exploits for XSS proofs and attacks. Work in progress, bookmark it. Technique Vec ...
- jenkins集成jmeter-进阶篇
1.gitlab自动触发jenkins构建 1⃣️安装插件: 2⃣️新建工程,设置git url,build when a change is pushed auto.sh /bin/sh echo ...
- 工具之wc
wc命令的功能为统计指定文件中的字节数.字数.行数, 并将统计结果显示输出. 语法:wc [选项] 文件… 说明:该命令统计给定文件中的字节数.字数.行数.如果没有给出文件名,则从标准输入读取.wc同 ...
- ajax 后台java代码执行完毕 前端报404错误
一个ajax请求,到java后台代码,后台成功接受并执行相应处理,但是返回的时候,success却没进去,前端报404错误. 因为是由于Controller忘记写spring的@Responsebod ...
- SVM(1)模式识别课堂笔记
引言:当两类样本线性可分时,针对我们之前学习的感知机而言,存在多个超平面能将数据分开,这里要讨论什么样的分类面最好的问题.为此,我们形式化的定义了最优分类超平面,他有两点特征:1.能将训练样本没有错误 ...
- Struts2与OGNL的联系
1.Struts与OGNL的结合原理 (1)值栈: OGNL表达式要想运行就要准备一个OGNLContext对象,Struts2内部含有一个OGNLContext对象,名字叫做值栈. 值栈也由两部分组 ...
- #使用abp框架与vue一步一步写我是月老的小工具(2) 后台搭建初体验
#使用abp框架与vue一步一步写我是月老的小工具(2) 后台搭建初体验 一.续上前言 关于这个小玩意的产品思考,假设我暂时把他叫我是月老热心人 这是一个没有中心的关系链,每个人进入以后都是以自己为中 ...
- 二、Shell变量
类型 注释强变量 变量在使用前,必须事先声明,甚至还需要初始化 弱变量 变量用时声明,甚至不区分类型 变量的作用:用来保存变化的数据 变量名 名称固定,由系统设定或用户定义 变量值 根据用户设 ...
- linux安装mariadb
yum install -y mariadb-server 账号:root 密码:空 本地登录:mysql -u root -p 远程登录:mysql -h 192.168.0.1 -u root - ...