hadoop 日常使用记录
1.Hadoop分布式文件系统(HDFS)
- HDFS基于GFS(Google File System),能够存储海量的数据,并且使用分布式网络客户端透明访问。
- HDFS中将文件拆分成特定大小的块结构(block-structured filesystem),一个文件的不同块存储在不同的节点中。
- 为了防止数据丢失,HDFS默认将一个块重复保存3份。
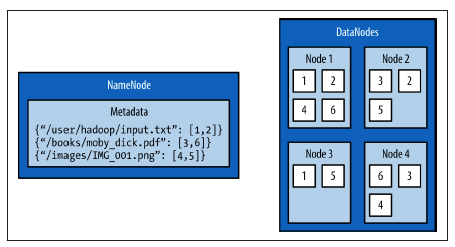
- HDFS的架构主要包括两个部分:NameNode和DataNode。
- NameNode保存整个文件系统的基础信息,例如:文件名,文件权限,文件每个块的存储位置等。为了能够快速访问获取信息,NameNode将这些基础信息保存在内存中。
- DataNodes是那些保存块(blocks)的机器,通常由大容量存储空间的廉价机器充当。
hadoop中常用文件操作命令
hdfs dfs -ls / (列出HDFS根目录的文件信息)
hdfs dfs -mkdir /user (在HDFS中创建目录)
hdfs dfs -put INPUT_PATH OUTPUT_PATH
hdfs dfs -cat
hdfs dfs -get
hadoop fs,hadoop dfs和hdfs dfs命令的区别:fs既能操作本地文件又能操作分布式文件系统,而dfs只能操作HDFS分布式文件系统。hadoop dfs已经废弃
2.MapReduce with Python
- MapReduce是一种编程模型,用它来将大量的数据计算任务划分成并行的独立的小任务。
- MapReduce框架主要包括3个阶段:map, shuffle and sort, and reduce(映射,混合和排序,规约)
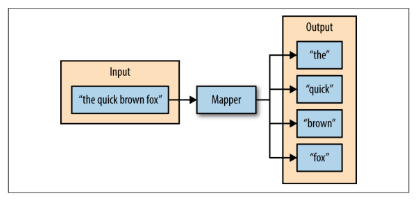
- Map阶段:maper函数分别处理系列键值对,产生零个或多个新的键值对。

- shuffle and sort:利用基于哈希的分割器给每确定每个键值对对于的reducer,并且进行排序。
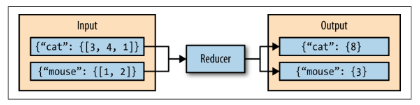
- Reduce阶段:利用reduce函数,将多个map阶段输出的键值对按照键对值进行合并,然后输出新的键值对。
- Hadoop streaming:maper和reducer都是按照一行一行的顺序从标准输入(stdin)读取数据,然后进行标准输出,maper的输出值为多个键值对,每个键值对用制表符(tab)分开。
3.Hadoop streaming
Hadoop Streaming工具的最大的好处是:能够让任何语言编写的map, reduce程序能够在hadoop集群上运行;map/reduce程序只要遵循从标准输入stdin读,写出到标准输出stdout即可。
另外一个方便之处就是:需要编写的map和reduce程序容易进行单机调试,通过管道前后相接的方式就可以模拟streaming, 在本地完成map/reduce程序的调试。
最后,streaming工具提供了丰富的参数来灵活控制作业的过程。
map/reduce作业是由一些可执行文件或脚本文件充当mapper或者reducer。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /bin/wc
任何可执行文件都可以被指定为mapper/reducer。这些可执行文件不需要事先存放在集群上; 如果在集群上还没有,则需要用-file选项让framework把可执行文件作为作业的一部分,一起打包提交。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper myPythonScript.py \
-reducer /bin/wc \
-file myPythonScript.py
hadoop 日常使用记录的更多相关文章
- Hadoop运维记录系列
http://slaytanic.blog.51cto.com/2057708/1038676 Hadoop运维记录系列(一) Hadoop运维记录系列(二) Hadoop运维记录系列(三) Hado ...
- 日常问题记录-- java.lang.IllegalArgumentException: taglib definition not consistent with specification version
转自:https://www.cnblogs.com/carterzhang/p/4288650.html 背景: tomcat8.0中使用taglib 错误表现: java.lang.Illegal ...
- hadoop日常运维与升级总结
日常运维 升级 问题处理方法 日常运维 进程管理 由于配置文件的更改,需要重启生效, 或者是进程自己因某种致命原因终止, 或者发现进程工作出现异常等情况下,需要进行手动进程的关闭或启动, 或者是增删节 ...
- hadoop安装问题记录
start-yarn.sh 启动正常,但是无法访问网页http://localhost:8088/cluster 原因: 可能是ipv6 的问题 解决方法: http://stackoverflow. ...
- hadoop 安装过程记录
1)首先配置好了四个linux虚拟机 root pwd:z****l*3 关闭了防火墙 开通了 sshd服务 开通了 ftp服务 配置了 jdk 1.8 配置好了互信 (之前配置的过程忘了!--检查了 ...
- Hadoop学习问题记录之基础篇
目的 记录学习hadoop过程中遇到的基础问题,无关大小.无关困扰时间长短. 问题一 全分布式环境中运行mapred程序,报异常:java.net.NoRouteToHostException: 没有 ...
- 【日常操作记录】Asp.Net Core 的一些基本操作或属性
用于记录在项目中使用到的方法.属性.操作,持续更新中 静态文件的使用 在项目中静态文件的使用需要在Startup中的Configure方法中增加: //使用静态文件 app.UseStaticFile ...
- Hadoop日常维护系列——Hadoop添加删除节点
添加节点 1.修改host 和普通的datanode一样.添加namenode的ip 2.修改namenode的配置文件conf/slaves 添加新增节点的ip或host 3.在新节点的 ...
- Mac OS X Yosemite安装Hadoop 2.6记录
整个安装过程分为四部分: 一. 安装Homebrew 二. ssh localhost 三. 安装Hadoop已经进行配置文件设置 (伪分布式) 四. 执行栗子 一. 安装Homebrew 採用H ...
随机推荐
- 1044 火星数字 (20 分)C语言
火星人是以 13 进制计数的: 地球人的 0 被火星人称为 tret. 地球人数字 1 到 12 的火星文分别为:jan, feb, mar, apr, may, jun, jly, aug, sep ...
- 一次 kafka 消息堆积问题排查
收到某业务组的小伙伴发来的反馈,具体问题如下: 项目中某 kafka 消息组消费特别慢,有时候在 kafka-manager 控制台看到有些消费者已被踢出消费组. 从服务端日志看到如下信息: 该消费组 ...
- Python库的安装(Windows/Linux通用)
pip安装 最简单的安装方式,自动下载并安装. pip:包管理工具 安装步骤 执行安装命令:pip install <package_name> wheel安装 在网速较差的情况下适用. ...
- bootstrap:按钮下拉菜单
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- HTTP,来一个详细的学习。
HTTP 认识 HTTP 首先你听的最多的应该就是 HTTP 是一种 超文本传输协议(Hypertext Transfer Protocol),这你一定能说出来,但是这样还不够,假如你是大厂面试官,这 ...
- BeanUtils 如何拷贝 List?
BeanUtils 如何拷贝 List? 一.背景 我们在DO.Model.VO层数据间可能经常转换数据: Entity对应的是持久层数据结构(一般是数据库表的映射模型); Model 对应的是业务层 ...
- WebStorm安装和激活
1.下载解压,得到jetbrains webstorm 2018.2主程序,破解文件和中文语言包: 2.运行“WebStorm-2018.2.exe”开始安装,默认安装目录[C:\Program Fi ...
- Redis系列之----Redis的两种持久化机制(RDB和AOF)
Redis的两种持久化机制(RDB和AOF) 什么是持久化 Redis的数据是存储在内存中的,内存中的数据随着服务器的重启或者宕机便会不复存在,在生产环境,服务器宕机更是屡见不鲜,所以,我们希望 ...
- 输入n个学生,并且输入成绩,判断是否偏科
H学校的领导主任决定分析一下今年所有N名学生的考试成绩,从中找出偏科的学生,考试成绩包含语文,数学,英语三门课程的分数,已知偏科的定义是:某一门课程的分数大于等于90,并且另外两门的分数小于等于70. ...
- MySQL快速回顾:高级查询操作
8.1 排序数据 检索出的数据并不是以纯粹的随机顺序显示的.如果不排序,数据一般将以它在底层表中出现的顺序显示.这可以是数据最初添加到表中的顺序.但是,如果数据后来进行过更新或删除,则此顺序将会受到M ...