C++实现索引堆及完整测试代码
首先贴一篇我看的博客,写的很清楚。作者:Emma_U
一些解释
索引堆首先是堆,但比堆肯定是更有用。
用处:
1.加速。 索引堆存储的是索引,并不直接存储值。在堆上浮下沉的元素交换的时候,交换索引可比交换值来的快。虽然我代码只实现了int类型的索引堆,但比方说string类型的索引堆,交换两个string,显然没有交换两个int型的索引快。
2.方便改动原数组 比如现在有一个vector,然后我们把它初始化为普通的堆,然后我们突然想改动vector中的第i个元素并恢复堆性质。但我们怎么找这个值在哪呢,毕竟堆只有首元素是可以在O(1)时间访问的。我们只有一个个遍历去寻找,这样时间是O(N),N是堆规模。但索引堆可以做到O(1)时间寻找并更新。虽然寻找并更新后重新恢复堆性质二者都需要O(logN)时间,但对于较大的N,二者的总体时间复杂度一个是O(N),一个是O(logN)。
稍微讲一下原理,因为我也是看文首的那篇博客学习的,也相当于复习了。首先我们声明一个data数组作为我们的原始数据集,除非人为更新其中的值,不然是不变的。data_size为data数组的规模。
另外就是我们堆的主体,一个index数组,大小等于data_size。其中的值初始化为0、1、2、3…data_size-1。也就是data数组所有元素的索引(此时还没初始化堆,所以是顺序的)。之后我们建堆后,data数组是不变的,我们只对index进行改动。最终我们对于index要保持这样的性质:data[index[i]]>data[index[2i+1]] and data[index[i]]>data[index[2i+2]]。 最终的结果就是:如果把index数组的每个元素值index[i]都作为索引改成data[index[i]],那index就是堆,这部分应该蛮好理解的。但到目前为止,我们如果更改data中的某个值,仍然要到index数组中一个个查找哪个是被改的,时间还是O(N),没有优化。目前所做的工作只是提高了建堆、维护堆性质等操作的时间开销,也就是只做了上面优点1的优化,优点2并没有实现。
下面是我觉得很不好理解的部分,怎么O(1)时间查询data数组中的第i个值。这里推荐去看文首的博客,我自我感觉不会讲的比作者更好。我下面针对那篇博客的内容补充一个证明,请先阅读那篇博客,一定要先看,不然你不知道我下面在证明什么!!!
下面的1~5编号的代码在我文后贴的index_heap.cpp中。下面证明map数组的值按照我的代码这样设置是正确的。
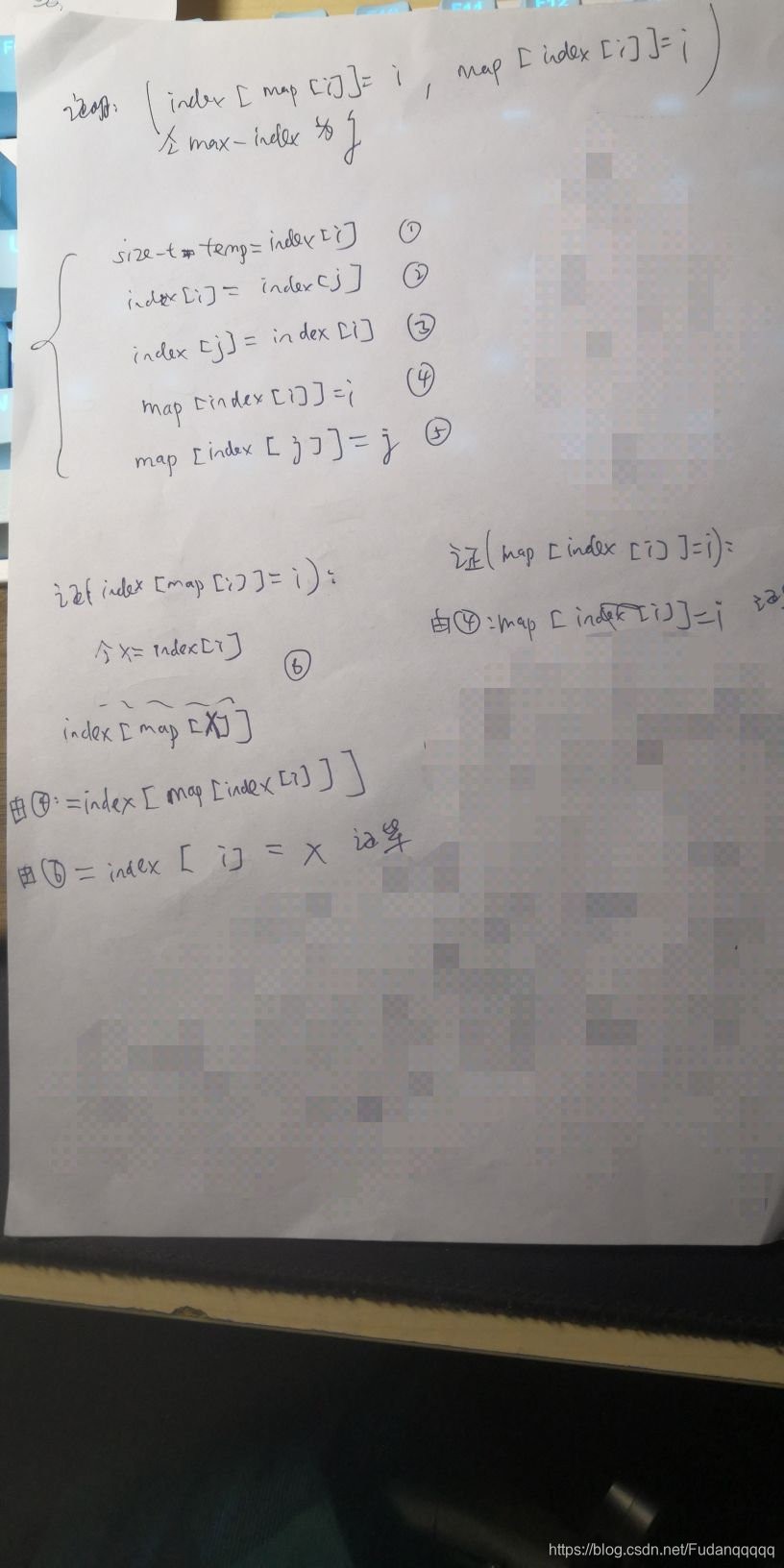
实现代码:
index_heap.h:
#pragma once
// #pragma warning(disable:4996)
#ifndef _INDEX_HEAP_H_
#define _INDEX_HEAP_H_
#include<iostream>
#include<vector>
using std::vector;
using std::cout;
using std::endl;
class index_heap {
vector<int> data; //数据数组
vector<int> index; //堆,index中存的是data中的索引,不存具体元素
vector<int> map; //映射,map[i]为data中索引i的元素在堆中的索引
int data_size;
public:
index_heap() :data_size(0) {}
~index_heap() {}
index_heap(const vector<int>&);
void create_max_heap();
void print();
void shift_down(size_t);
void shift_up(size_t);
void push(int);
void pop();
int top();
void change(size_t, int);
};
#endif
index_heap.cpp
#include"index_heap.h"
index_heap::index_heap(const vector<int>& vec) {
data = vec;
data_size = vec.size();
index.resize(data_size);
for (int i = 0; i < data_size; ++i) {
index[i] = i;
}
map = index;
create_max_heap();
}
void index_heap::create_max_heap() {
for (int i = data_size / 2 - 1; i >= 0; --i) {
shift_down(i);
}
}
void index_heap::print() {
if (data_size == 0) {
cout << "No data!" << endl;
return;
}
cout << "DATA:" << endl;
for (int num : data) {
cout << num << " ";
}
cout << endl << "INDEX:" << endl;
for (int num : index) {
cout << num << " ";
}
cout << endl << "MAP:" << endl;
for (int num : map) {
cout << num << " ";
}
}
//下沉
void index_heap::shift_down(size_t i) {
if (i >= data_size - 1) {
return;
}
int j = i;
if (2 * i + 1 < data_size and data[index[2 * i + 1]] > data[index[j]]) {
j = 2 * i + 1;
}
if (2 * i + 2 < data_size and data[index[2 * i + 2]] > data[index[j]]) {
j = 2 * i + 2;
}
if (i != j) {
int temp = index[i];
index[i] = index[j];
index[j] = temp;
map[index[i]] = i;
map[index[j]] = j;
shift_down(j);
}
}
//上浮
void index_heap::shift_up(size_t i) {
if (i >= data_size or i == 0) {
return;
}
size_t i_parent = i / 2 - 1; //i_parent是i的父亲节点
if (data[index[i_parent]] < data[index[i]]) {
int temp = index[i];
index[i] = index[i_parent];
index[i_parent] = temp;
map[index[i]] = i;
map[index[i_parent]] = i_parent;
shift_up(i_parent);
}
}
void index_heap::push(int x) {
data.push_back(x);
++data_size;
index.push_back(data_size - 1);
map.push_back(data_size - 1);
shift_up(data_size - 1);
}
void index_heap::pop() {
if (data_size == 0) {
cout << "No data can be popped!" << endl;
return;
}
size_t p = index[0];
data.erase(data.begin() + p);
index[0] = index[data_size - 1];//最后一个元素(即最小的元素)拿到堆顶
--data_size; //相当于删除了堆顶
index.resize(data_size);
map.resize(data_size);
map[index[0]] = 0;
shift_down(0); //恢复大顶堆性质
}
int index_heap::top() {
if (data_size == 0) {
cout << "No data can be topped!" << endl;
return INT_MAX;
}
return data[index[0]];
}
void index_heap::change(size_t i, int num) {
if (i >= data_size) {
cout << "Invalid index!" << endl;
return;
}
if (data[i] == num) {
cout << "Same number,no need to change!" << endl;
return;
}
int original_num = data[i];
data[i] = num;
if (original_num > num) {
shift_down(map[i]);
}
else {
shift_up(map[i]);
}
}
main.cpp(测试):
#include"index_heap.h"
int main()
{
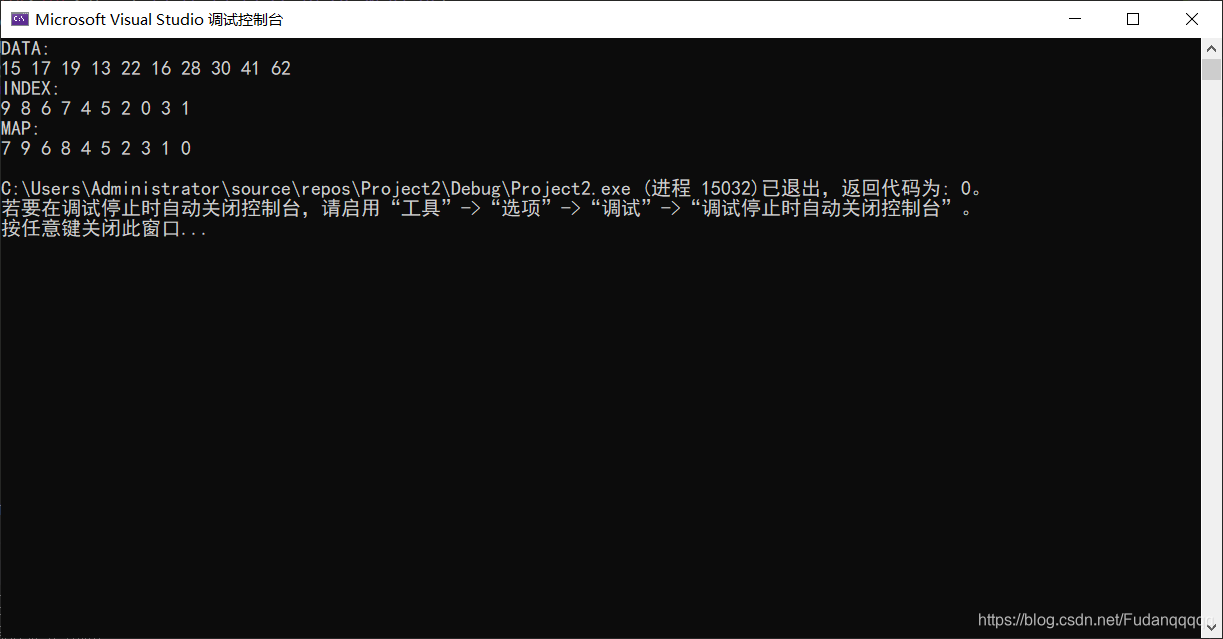
vector<int> p = { 15,17,19,13,22,16,28,30,41,62};
index_heap heap(p);
heap.print();
getchar();
return 0;
}
我的运行截图:
话说之前根本没听过索引堆这个名词,昨天做leetcode一道双端队列题时候看见这个名词,于是从昨天晚上看到今天下午,搞懂了一个新东西,还蛮有意思的哈。
2019年11月15日 16:05:44
C++实现索引堆及完整测试代码的更多相关文章
- 面试官:讲讲Redis的五大数据类型?如何使用?(内含完整测试源码)
写在前面 最近面试跳槽的小伙伴有点多,给我反馈的面试情况更是千差万别,不过很多小伙伴反馈说:面试中的大部分问题都能够在我的公众号[冰河技术]中找到答案,面试过程还是挺轻松的,最终也是轻松的拿到了Off ...
- 自己动手写中文分词解析器完整教程,并对出现的问题进行探讨和解决(附完整c#代码和相关dll文件、txt文件下载)
中文分词插件很多,当然都有各自的优缺点,近日刚接触自然语言处理这方面的,初步体验中文分词. 首先感谢harry.guo楼主提供的学习资源,博文链接http://www.cnblogs.com/harr ...
- 堆和索引堆的实现(python)
''' 索引堆 ''' ''' 实现使用2个辅助数组来做.有点像dat.用哈希表来做修改不行,只是能找到这个索引,而需要change操作 还是需要自己手动写.所以只能用双数组实现. #引入索引堆的核心 ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
- Java 网络IO编程总结(BIO、NIO、AIO均含完整实例代码)
本文会从传统的BIO到NIO再到AIO自浅至深介绍,并附上完整的代码讲解. 下面代码中会使用这样一个例子:客户端发送一段算式的字符串到服务器,服务器计算后返回结果到客户端. 代码的所有说明,都直接作为 ...
- 索引堆(Index Heap)
首先我们先来看一个由普通数组构建的普通堆. 然后我们通过前面的方法对它进行堆化(heapify),将其构建为最大堆. 结果是这样的: 对于我们所关心的这个数组而言,数组中的元素位置发生了改变.正是因为 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Python之unittest测试代码
前言 编写函数或者类时,还可以为其编写测试.通过测试,可确定代码面对各种输入都能够按要求的那样工作. 本次我将介绍如何使用Python模块unittest中的工具来测试代码. 测试函数 首先我们先编写 ...
- 基于傅里叶变换的音频重采样算法 (附完整c代码)
前面有提到音频采样算法: WebRTC 音频采样算法 附完整C++示例代码 简洁明了的插值音频重采样算法例子 (附完整C代码) 近段时间有不少朋友给我写过邮件,说了一些他们使用的情况和问题. 坦白讲, ...
随机推荐
- Python 绘图 cookbook
目录 python绘图常见bug matplotlib包加载 解决中文绘图乱码解决方法 解决python中用matplotlib画多幅图时出现图形部分重叠的问题 python绘图常见bug matpl ...
- 关于2008R2的序列号
windows server 2008 r2 企业版序列号 BX4WB-3WTB8-HCRC9-BFFG3-FW26F P63JV-9RWW2-DJW7V-RHTMT-W8KWJ MDB49-7MYG ...
- Android_ViewPager+Fragment实现页面滑动和底部导航栏
1.Xml中底部导航栏由一个RadioGroup组成,其上是ViewPager. <?xml version="1.0" encoding="utf-8" ...
- MongoDB地理空间(2d)索引创建与查询
LBS(Location Based Services)定位服务,即根据用户位置查询用户附近相关信息,这一功能在很多应用上都有所使用.基于用户位置进行查询时,需要提供用户位置的经纬度.为了提高查询速度 ...
- URLSearchParams/FormData
一.URLSearchParams()(很好用,但有一定兼容问题,未来版本的浏览器中该功能的语法和行为可能随对应的标准文档而改变.) URLSearchParams 接口定义了一些实用的方法来处理 U ...
- nginx 启动报错找不到nginx.pid文件
这个问题的出现应该是系统找不到nginx的配置文件nginx.conf,所以,我们要告诉系统配置文件的位置:' --- 使用nginx -c /usr/local/nginx/conf/nginx.c ...
- c++ char*和wchar*互相转换(转)
原文地址: 1.c++ char*和wchar*互相转换 2.C++ WINDOWS下 wchar_t *和char * 相互转化总结篇
- api接口出现Provisional headers are shown,
问题分析:根据反馈可以知道,发起请求,但服务器未及时响应,原因可能是超时,或者被拦截
- 2019牛客多校第五场 F maximum clique 1 状压dp+最大独立集
maximum clique 1 题意 给出一个集合s,求每个子集的最大独立集的权值和(权值是独立集的点个数) 分析 n比较小,一股浓浓的暴力枚举每一个子集的感觉,但是暴力枚举模拟肯定会T,那么想一想 ...
- 转载:android audio policy
Audio policy basic:https://www.cnblogs.com/CoderTian/p/5705742.html Set volume flow:https://blog.csd ...