轻量架构ShuffleNet V2:从理论复杂度到实用设计准则
转自:机器之心
近日,旷视科技提出针对移动端深度学习的第二代卷积神经网络 ShuffleNet V2。研究者指出过去在网络架构设计上仅注重间接指标 FLOPs 的不足,并提出两个基本原则和四项准则来指导网络架构设计,最终得到了无论在速度还是精度上都超越先前最佳网络(例如 ShuffleNet V1、MobileNet 等)的 ShuffleNet V2。在综合实验评估中,ShuffleNet V2 也在速度和精度之间实现了最佳权衡。研究者认为,高效的网络架构设计应该遵循本文提出的四项准则。本文已被 ECCV 2018 收录。
1 简介
深度卷积网络(CNN)的结构经过多年改进变得更加准确和快速。自 2012 年 AlexNet [1] 取得里程碑式突破,各种新型结构层出不穷,一次次刷新 ImageNet 分类准确率,这些结构包括 VGG [2]、GoogLeNet [3]、ResNet [4、5]、DenseNet [6]、ResNeXt [7]、SE-Net [8] 和神经网络架构自动搜索 [9–11]。
除了精度,计算复杂度是另一个重要的考虑因素。现实世界的任务通常是当目标平台(如硬件)和应用场景(如自动驾驶需要低延迟)既定时,在有限算力之下实现最优的精度。这催生出一系列针对轻量级架构设计和速度-精度更好权衡的研究,包括 Xception [12]、MobileNet [13]、MobileNet V2 [14]、ShuffleNet V1[15] 和 CondenseNet [16] 等等。在这些研究中,组卷积(group convolution)和深度卷积(depthwise convolution)至关重要。
度量计算复杂度的常用指标是浮点运算数,即 FLOPs。然而,FLOPs 是一种间接指标。它只是本文真正关心的直接指标(如速度或延迟)的一种近似形式,通常无法与直接指标划等号。先前研究 [17,18,14,19] 已对这种差异有所察觉。比如,MobileNet V2 [14] 要远快于 NASNET-A [9],但是两者 FLOPs 相当。图 1 (c) (d) 进一步解释了这一现象,它表明 FLOPs 近似的网络也会有不同的速度。所以,将 FLOPs 作为衡量计算复杂度的唯一标准是不够的,这样会导致次优设计。
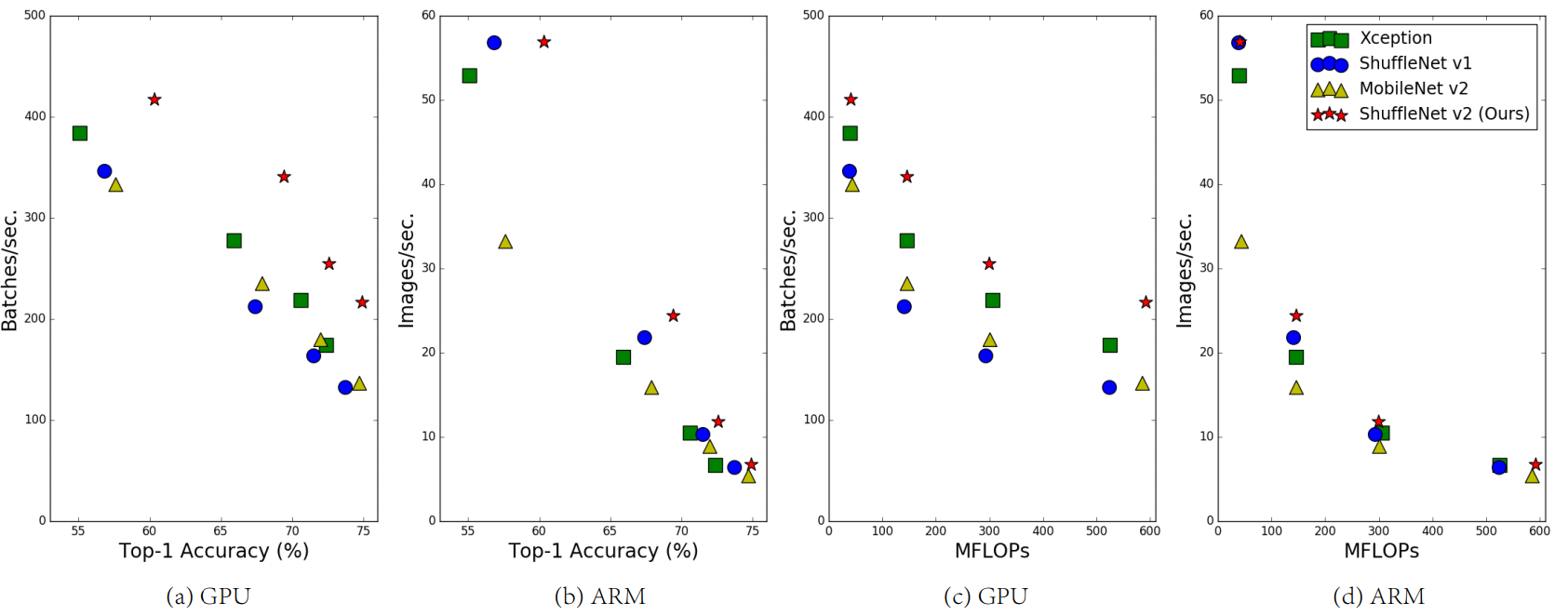
图 1:四个网络架构在两个硬件平台、四种不同计算复杂度上的(验证集 ImageNet 分类)精度、速度和 FLOPs 结果。(a, c) GPU 结果,batchsize= 8。(b, d) ARM 结果,batchsize = 1。本文提出的 ShuffleNet V2(右上)在所有情况下取得了最优性能。
间接指标 (FLOPs) 和直接指标(速度)之间存在差异的原因可以归结为两点。首先,对速度有较大影响的几个重要因素对 FLOPs 不产生太大作用。其中一个因素是内存访问成本 (MAC)。在某些操作(如组卷积)中,MAC 占运行时间的很大一部分。对于像 GPU 这样具备强大计算能力的设备而言,这就是瓶颈。在网络架构设计过程中,内存访问成本不能被简单忽视。另一个因素是并行度。当 FLOPs 相同时,高并行度的模型可能比低并行度的模型快得多。
其次,FLOPs 相同的运算可能有着不同的运行时间,这取决于平台。例如,早期研究 [20–22] 广泛使用张量分解来加速矩阵相乘。但是,近期研究 [19] 发现张量分解在 GPU 上甚至更慢,尽管它减少了 75% 的 FLOPs。本文研究人员对此进行了调查,发现原因在于最近的 CUDNN [23] 库专为 3×3 卷积优化:当然不能简单地认为 3×3 卷积的速度是 1×1 卷积速度的 1/9。
据此,研究者提出了高效网络架构设计应该考虑的两个基本原则:第一,应该用直接指标(例如速度)替换间接指标(例如 FLOPs);第二,这些指标应该在目标平台上进行评估。在这项研究中,作者遵循这两个原则,并提出了一种更加高效的网络架构。
第 2 部分,作者首先分析了两个代表性的当前最优网络 [15,14] 的运行性能,然后推导出高效网络设计的四个准则,它们扬弃了仅考虑 FLOPs 所带来的局限性。尽管这些准则独立于硬件平台,但研究者通过一系列可控实验,以专用的代码优化在两个不同的硬件平台(GPU 和 ARM)上验证其性能,确保本论文提出的准则是当前最佳的。
第 3 部分,研究者根据这些准则设计了一种新的网络架构。它是 ShuffleNet V1 的改进版,因此被称为 ShuffleNet V2。第 4 部分,综合验证实验的结果表明,ShuffleNet V2 在两个平台上都比先前的网络快得多,并且更加准确。图 1 (a) (b) 给出了对比结果的概览。例如,给定计算复杂度预算 40M FLOPs,ShuffleNet V2 的精度比 ShuffleNet V1 高 3.5%,比 MobileNet V2 高 3.7%。
2 高效网络设计的实用准则
研究者分析了两个移动端当前最佳网络 ShuffleNet V1 和 MobileNet V2 的运行时性能,发现它们的表现代表了当前的研究趋势。它们的核心组件为组卷积和深度卷积,这也是其它当前最佳架构的关键组件,例如 ResNet、Xception、MobileNet 和 CondenseNet 等。
研究者注意到 FLOPs 仅和卷积部分相关,尽管这一部分需要消耗大部分的时间,但其它过程例如数据 I/O、数据重排和元素级运算(张量加法、ReLU 等)也需要消耗一定程度的时间。
基于以上观察,研究者从不同层面做了运行时(速度方面)分析,并提出了设计高效网络架构需要遵循的准则:
G1. 相同的通道宽度可最小化内存访问成本(MAC);
G2. 过度的组卷积会增加 MAC;
G3. 网络碎片化(例如 GoogLeNet 的多路径结构)会降低并行度;
G4. 元素级运算不可忽视。
结论和讨论:基于上述准则和实证研究,本文总结出一个高效的网络架构应该:(1)使用「平衡」的卷积(相同的通道宽度);(2)考虑使用组卷积的成本;(3)降低碎片化程度;(4)减少元素级运算。这些所需特性依赖于平台特征(例如内存控制和代码优化),且超越了理论化的 FLOPs。它们都应该在实际的网络设计中被考虑到。
近期,轻量级神经网络架构 [15,13,14,9, 11,10,12] 上的研究进展主要基于 FLOPs 间接指标,并且没有考虑上述四个准则。例如,ShuffleNet V1 [15] 严重依赖组卷积(违反 G2)和瓶颈形态的构造块(违反 G1)。MobileNet V2 [14] 使用一种倒置的瓶颈结构,违反了 G1。它在「厚」特征图上使用了深度卷积和 ReLU 激活函数,违反了 G4。自动生成结构 [9,10,11] 的碎片化程度很高,违反了 G3。
3 新型高效架构 ShuffleNet V2
ShuffleNet V1 回顾
ShuffleNet[15] 是一种先进的网络架构,广泛应用于手机等低配设备。它启发了本文工作,因此首先对其进行回顾与分析。
根据 ShuffleNet V1,轻量级网络的主要挑战是在给定计算预算(FLOPs)时,只能获得有限数量的特征通道。为了在不显著增加 FLOPs 情况下增加通道数量,ShuffleNet V1 采用了两种技术:逐点组卷积核和类瓶颈(bottleneck-like)结构;然后引入「channel shuffle」操作,令不同组的通道之间能够进行信息交流,提高精度。其构建模块如图 3(a)(b) 所示。
如第二部分所述,逐点组卷积和瓶颈结构都增加了 MAC(G1 和 G2)。这个成本不可忽视,特别是对于轻量级模型。另外,使用太多分组也违背了 G3。捷径连接(shortcut connection)中的元素级「加法」操作也不可取 (G4)。因此,为了实现较高的模型容量和效率,关键问题是如何保持大量且同样宽的通道,既没有密集卷积也没有太多的分组。
通道分割和 ShuffleNet V2
为此,本文引入一个简单的操作——通道分割(channel split)。如图 3(c) 所示。在每个单元的开始,c 特征通道的输入被分为两支,分别带有 c−c'和 c'个通道。按照准则 G3,一个分支仍然保持不变。另一个分支由三个卷积组成,为满足 G1,令输入和输出通道相同。与 ShuffleNet V1 不同的是,两个 1×1 卷积不再是组卷积。这部分是为了遵循 G2,部分是因为分割操作已经产生了两个组。
卷积之后,把两个分支拼接起来,从而通道数量保持不变 (G1)。然后进行与 ShuffleNet V1 相同的「Channel Shuffle」操作来保证两个分支间能进行信息交流。
「Shuffle」之后,下一个单元开始运算。注意,ShuffleNet V1 [15] 中的「加法」操作不再存在。像 ReLU 和深度卷积这样的操作只存在一个分支中。另外,三个连续的操作「拼接」、「Channel Shuffle」和「通道分割」合并成一个操作。根据 G4,这些变化是有利的。
对于空间下采样,该单元经过稍微修改,详见图 3(d)。通道分割运算被移除。因此,输出通道数量翻了一倍。
本文提出的构造块 (c)(d),以及由此而得的网络,被称之为 ShuffleNet V2。基于上述分析,本文得出结论:由于对上述四个准则的遵循,该架构设计异常高效。
上述构建模块被重复堆叠以构建整个网络。为简单起见,本文令 c' = c/2。整个网络结构类似于 ShuffleNet V1(见表 5)。二者之间只有一个区别:前者在全局平均池化层之前添加了一个额外的 1×1 卷积层来混合特征,ShuffleNet V1 中没有该层。与 ShuffleNet V1 类似,每个构建块中的通道数量可以扩展以生成不同复杂度的网络,标记为 0.5×、1×等。
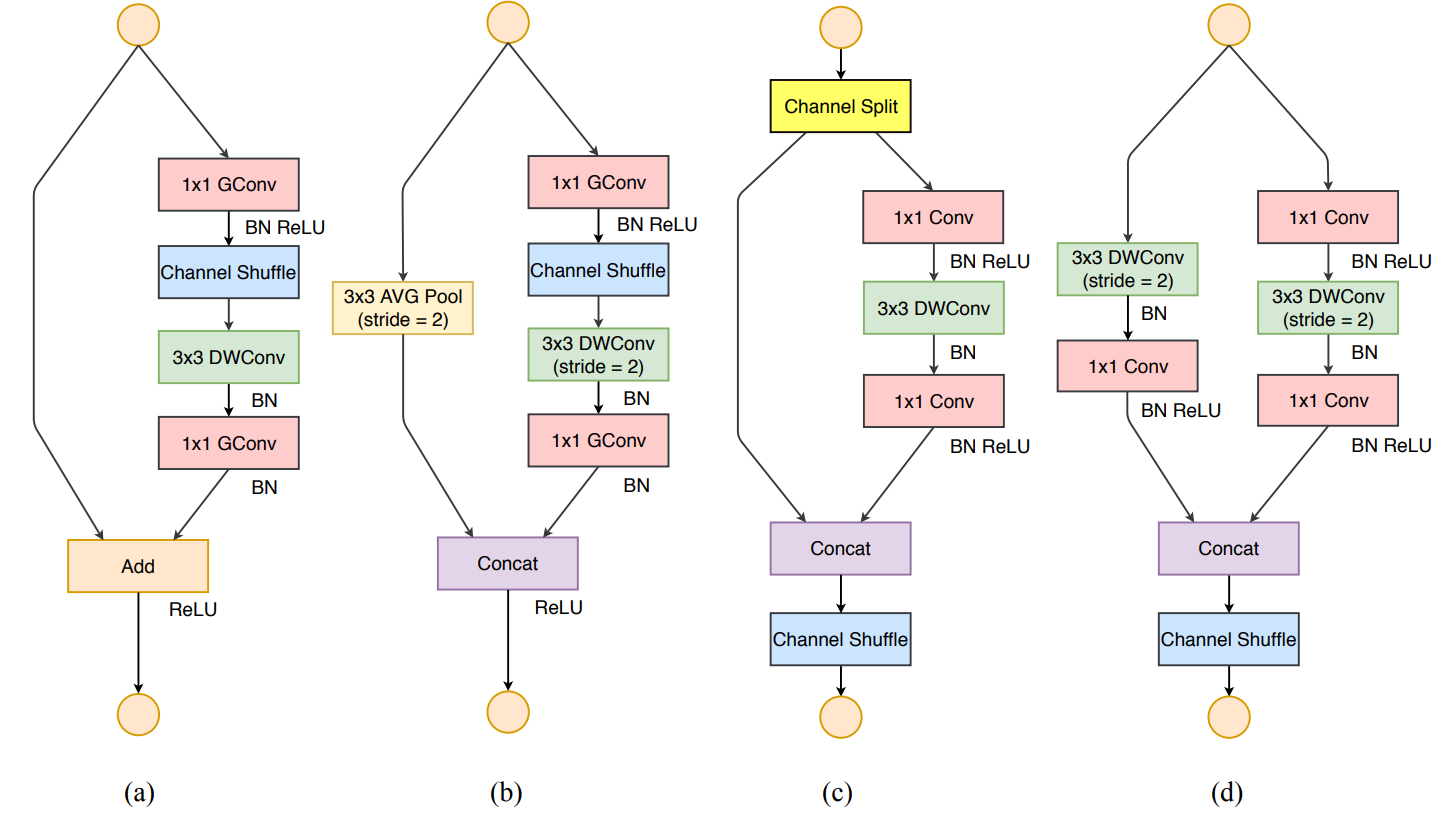
图 3:ShuffleNet V1 [15] 和 ShuffleNet V2 的构造块。(a)ShuffleNet 基本单元;(b) 用于空间下采样 (2×) 的 ShuffleNet 单元;(c) ShuffleNet V2 的基本单元;(d) 用于空间下采样 (2×) 的 ShuffleNet V2 单元。DWConv:深度卷积 (depthwise convolution)。GConv:组卷积 (group convolution)。
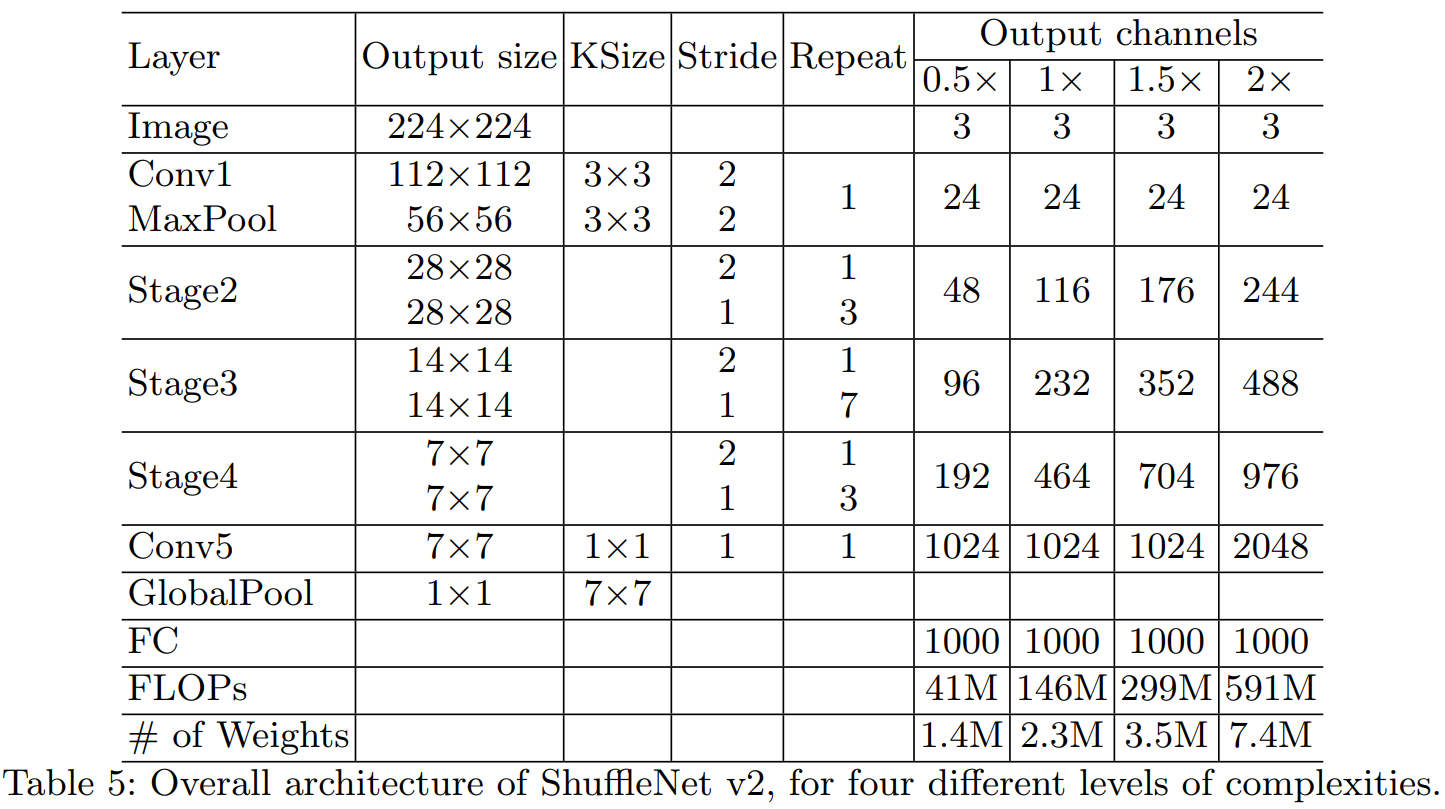
表 5:ShuffleNet V2 的整体架构,复杂度包含四个级别。
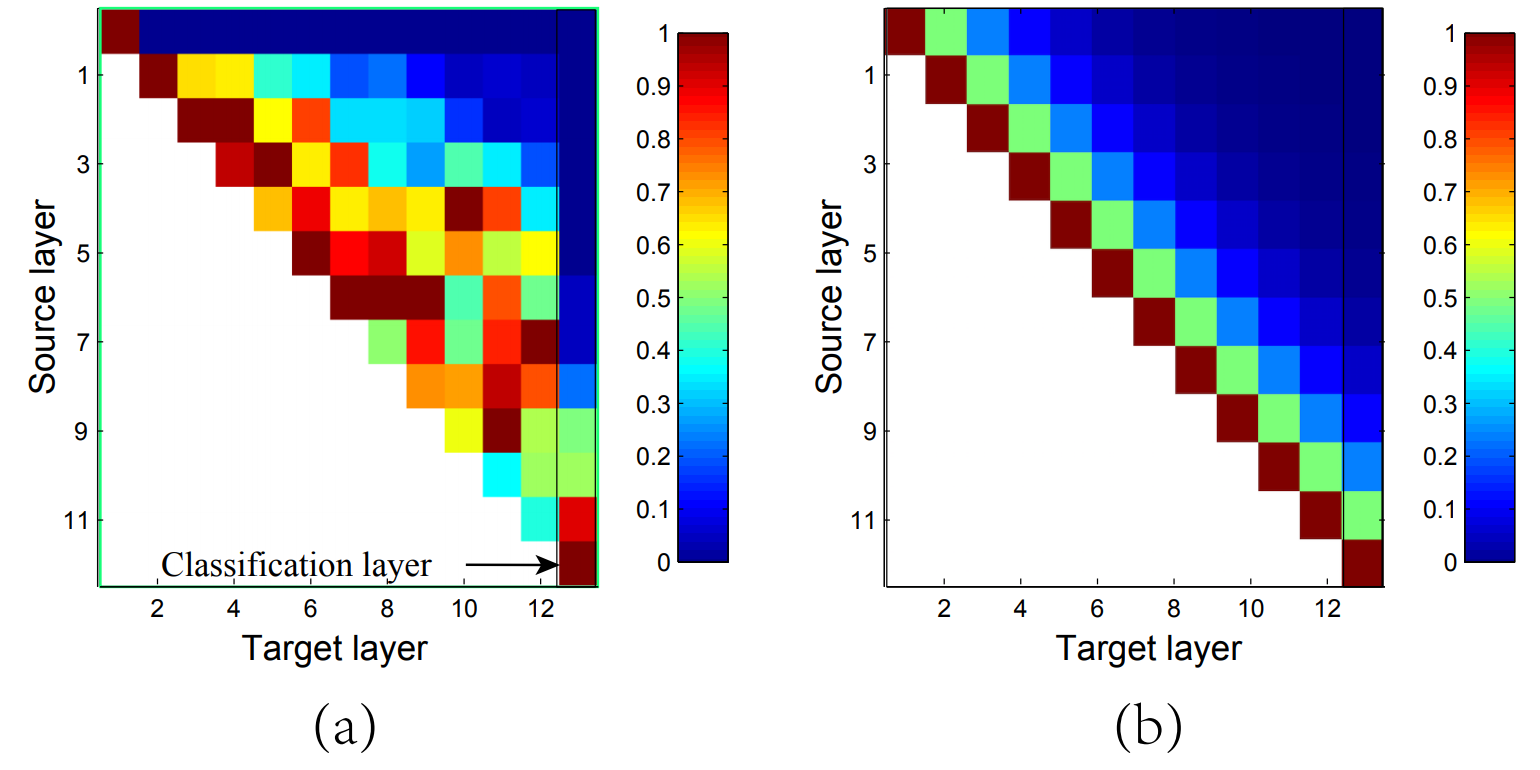
图 4:DenseNet [6] 和 ShuffleNet V2 中特征重用模式的图示。(a) 模型中卷积层的滤波器绝对权重平均值。像素颜色 (s,l) 编码连接层 s 和 l 的权重的平均 L1 范数。(b) 像素颜色 (s,l) 表示直接连接 ShuffleNet V2 中模块 s 和 l 的通道数量。所有像素值都归一化到 [0,1] 区间。
4 实验结果
本文的 Ablation 实验是在 ImageNet 2012 分类数据集上展开的。按照一般原则,所有的对比网络有四种不同的计算复杂度,分别是 40,140,300 和 500+ MFLOPs。这样的复杂度在移动端场景中很典型。超参数及其他设置与 ShuffleNet V1 一样。本文对比的网络架构分别是 ShuffleNet V1,MobileNet V2,Xception,DenseNet。具体结果如下表所示:

表 6:大模型的结果。
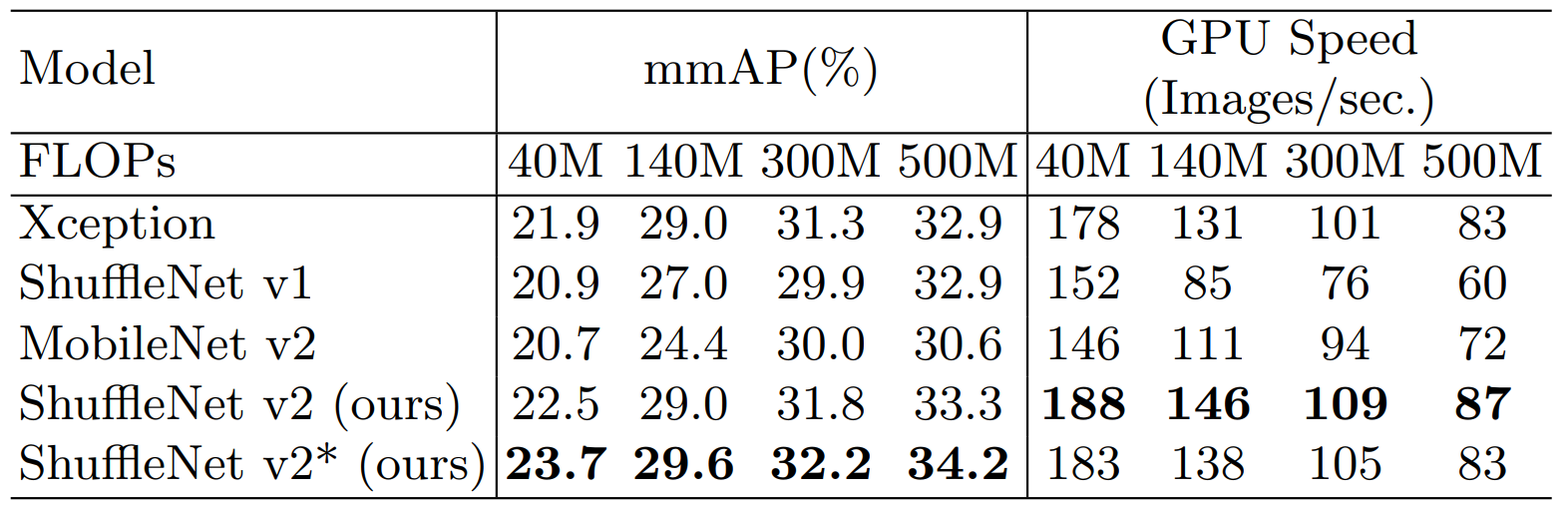
表 7:ShuffleNet V2 在 COCO 目标检测任务上的性能。输入图像大小是 800×1200。FLOPs 行列出了输入图像大小为 224×224 时的复杂度水平。至于 GPU 速度评估,批大小为 4。未测试 ARM,因为 [34] 中所需的 PSRoI 池化操作目前在 ARM 上不可行。

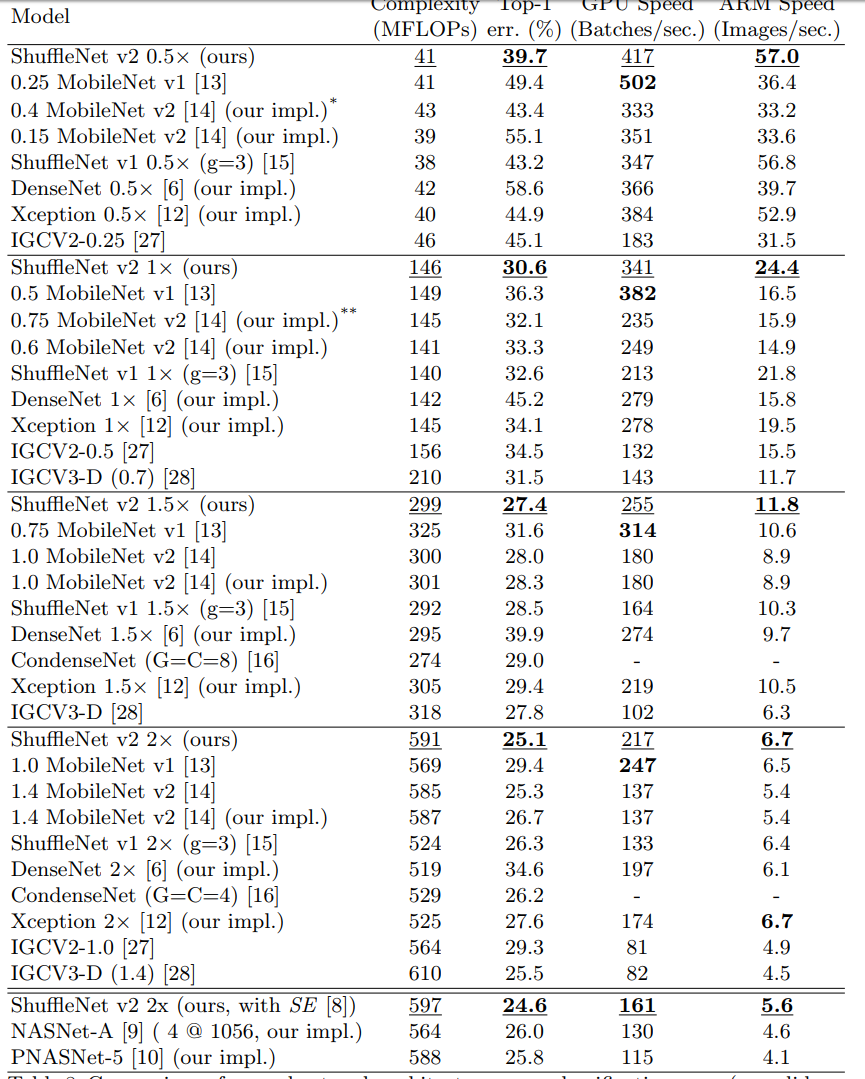
表 8:多个网络架构在两个平台、四个计算复杂度级别上的(验证集、单中心裁剪)分类误差和速度对比。为方便起见,结果按照复杂度级别分组。GPU 的批大小是 8,ARM 的批大小是 1。除了 [*] 160 × 160 和 [**] 192 × 192,图像大小均为 224×224。由于目前缺少高效实现,本文不提供 CondenseNets [16] 的速度测量结果。
5 结论
本文提出,网络架构设计应该考虑直接指标,比如速度,而不是间接指标,比如 FLOPs。更重要的是,本文还给出四个重要的实用设计准则,以及一个全新的架构——ShuffleNet V2,综合实验已经证实了其有效性。研究者希望本文的工作可以启迪未来的网络架构设计,更加具有平台意识,并朝着实用的方向发展。
论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design

论文下载地址:https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw
摘要:目前,神经网络架构设计主要由计算复杂度的间接指标(即 FLOPs)来指导。但是,直接指标(如速度)还依赖于其他因素,如内存访问成本和平台特点。因此,本文提出在目标平台上评估直接指标,而不是只考虑 FLOPs。基于一系列对比实验,本文得出多个高效、实用的网络设计准则,并据此得到了一个新的架构 ShuffleNet V2。综合对比实验证明了该模型在速度和精度的权衡方面达到当前最优水平。
轻量架构ShuffleNet V2:从理论复杂度到实用设计准则的更多相关文章
- 使用ConcurrentDictionary实现轻量缓存
项目中需要用到一个轻量缓存,存储重复使用的数据.在设计中需要考虑:1.做成通用组件,为未来其他模块方法操作结果做准备.2.缓存模块需要接口化,为未来替换使用外部缓存做准备.3.使用默认缓存过期时间,单 ...
- Raspkate - 基于.NET的可运行于树莓派的轻量型Web服务器
最近在业余时间玩玩树莓派,刚开始的时候在树莓派里写一些基于wiringPi库的C语言程序来控制树莓派的GPIO引脚,从而控制LED发光二极管的闪烁,后来觉得,是不是可以使用HTML5+jQuery等流 ...
- Vue.js:轻量高效的前端组件化方案
转发一篇尤老师对vue.js的介绍,了解vue.js的来龙去脉.不过现在已经是2.0了,也有添加一些新的东西,当然有些东西也改了. Vue.js:轻量高效的前端组件化方案 Vue.js 是我在2014 ...
- 基于netty轻量的高性能分布式RPC服务框架forest<下篇>
基于netty轻量的高性能分布式RPC服务框架forest<上篇> 文章已经简单介绍了forest的快速入门,本文旨在介绍forest用户指南. 基本介绍 Forest是一套基于java开 ...
- 基于netty轻量的高性能分布式RPC服务框架forest<上篇>
工作几年,用过不不少RPC框架,也算是读过一些RPC源码.之前也撸过几次RPC框架,但是不断的被自己否定,最近终于又撸了一个,希望能够不断迭代出自己喜欢的样子. 顺便也记录一下撸RPC的过程,一来作为 ...
- Vue.js:轻量高效的前端组件化方案(转载)
摘要:Vue.js通过简洁的API提供高效的数据绑定和灵活的组件系统.在前端纷繁复杂的生态中,Vue.js有幸受到一定程度的关注,目前在GitHub上已经有5000+的star.本文将从各方面对Vue ...
- vue-concise-slider 一个轻量的vue幻灯片组件
vue-concise-slider 一个轻量的vue幻灯片组件 阅读 541 收藏 35 2017-07-03 原文链接:github.com 外卖订单处理有烦恼?试试美团点评餐饮开放平台吧,可实现 ...
- 采用轻量ServiceMesh实现灰度发布的实践
软件总会有缺陷的,解决问题的同时往往会引入新的问题,关键是看这些问题是否在我们的控制范围内,“灰度发布”就是让问题受控的方法之一. 前言 我们的 CTO 经常说:“研发团队最首要的任务是提供稳定的服务 ...
- 【转】Vue.js:轻量高效的前端组件化方案
摘要:Vue.js通过简洁的API提供高效的数据绑定和灵活的组件系统.在前端纷繁复杂的生态中,Vue.js有幸受到一定程度的关注,目前在GitHub上已经有5000+的star.本文将从各方面对Vue ...
随机推荐
- idea中gitlab新创建分支查找不到的原因
问题: 很多人说是这样解决: https://blog.csdn.net/rodulf/article/details/51536532 然后对于我来说没用............ 这里先说下如何从m ...
- 引入springboot的两种方式以及springboot容器的引入
一.在项目中引入springboot有两种方式: 1.引入spring-boot-starter-parent 要覆盖parent自带的jar的版本号有两种方式: (1)在pom中重新引入这个jar, ...
- context configure and clock schedule
每个窗口都有自己的context,这里演示怎么配置context以及如何实现定时器...... #-*- coding:gbk -*- import pyglet platform=pyglet.wi ...
- JavaScript中的栈和堆内存,作用域
1.栈 stack”和“堆 heap” 简单的来讲,stack上分配的内存系统自动释放,heap上分配的内存,系统不释放,哪怕程序退出,那一块内存还是在那里.stack一般是静态 ...
- CodeForces - 615D Multipliers(数论)
http://codeforces.com/problemset/problem/615/D 题意 给出m个质因子,组成一个数n.问n的约数的乘积是多少,输出mod 1e+7的结果. 分析 从输入我们 ...
- UVALive - 7637 E - Balanced String(构造)
原题链接 题意:给出一个打乱顺序的序列,问是否能构造出一个括号匹配的字符串.每个数字为此前读取到的左括号数减去右括号数. 分析:有左括号开始构造,不够的话就找右括号.注意特殊情况待处理.详情看代码 # ...
- PHP7 学习笔记(九)phpsize动态编译openssl扩展 (微信公众平台)
先吐槽,微信公众平台授权出问题了,尽然访问不了 一.问题描述: 使用PHP中的库函数file_get_contents时出现Unable to find the wrapper "https ...
- C++ STL sort()函数用法
C++STL提供的在里的排序函数,有以下两种形式 此外还提供有稳定排序版本stable_sort(),用法类似. 第一种形式: template <class RandomAccessItera ...
- Python基础-day01
写在前面 先后接触过很多编程语言,最喜欢的就是C和Python,相比其他语言,C 是神器,优点太多了:个人而言,C 最重要的一点就是能够让你在敲代码的时候是以一个计算机科学家的角度去思考,而不是仅仅停 ...
- Linux下删除命令 硬盘空间查看... 常用命令
(此命令请慎重使用) 使用rm -rf命令即可. 使用rm -rf 目录名字 命令即可 -r 就是向下递归,不管有多少级目录,一并删除-f 就是直接强行删除,不作任何提示的意思 (警告:不作任何 ...