Java 持久化操作之 --XML
摘自:http://www.cnblogs.com/lsy131479/p/8728767.html
1)有关XML简介
XML(EXtensible Markup Language)可扩展标记语言
特点:XML与操作系统、编程语言的开发平台无关
实现不同系统之间的数据交换
作用:数据交换、配置应用程序和网站
大致文档结构:

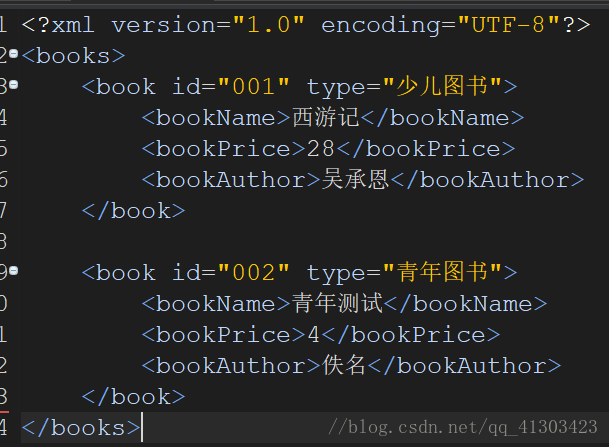
XML文档内容由一系列标签元素组成:


XML编写注意事项:
所有XML元素都必须有结束标签
XML标签对大小写敏感
XML必须正确的嵌套
同级标签以缩进对齐
元素名称可以包含字母、数字或其他的字符
元素名称不能以数字或者标点符号开始
元素名称中不能含空格
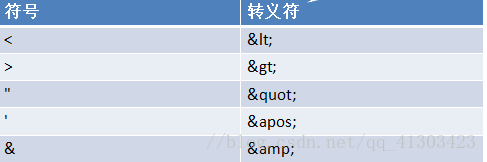
XML中的转义符列表:

2)解析XML技术:
DOM:
基于XML文档树结构的解析
适用于多次访问的XML文档
特点:比较消耗资源
SAX:
基于事件的解析
适用于大数据量的XML文档
特点:占用资源少,内存消耗小
DOMJ4:
非常优秀的java XML API
性能优异、功能强大
开放源代码
2-1)DOM解析XML:增删改查d
DOM介绍:文档对象模型(Document Object Model):DOM把XML文档映射成一个倒挂的树

代码演示DOM解析XML

package text; import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlText {
//private static Document parse;
public static void main(String[] args) throws Exception {
// text();
//add();
// delete();
//modfiy();
}
/**
* 循环解析XML
*
* @throws ParserConfigurationException
* @throws SAXException
* @throws IOException
*/
public static void text() throws ParserConfigurationException,
SAXException, IOException {
// 创建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 1.创建解析器对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 2.创建文档对象
Document document = builder.parse("lbl/NewFile.xml");
// 3.拿到节点集合
NodeList list = document.getElementsByTagName("book");
// 4.遍历集合
for (int i = 0; i < list.getLength(); i++) {
// 拿到每个节点
Element item = (Element) list.item(i);
// 解析每个节点属性的值
String bookid = item.getAttribute("id");
String bookType = item.getAttribute("type");
System.out.println(bookid + "\t" + bookType);
// 解析每个节点的子节点的值
String bookName = item.getElementsByTagName("bookName").item(0)
.getTextContent();
String bookprice = item.getElementsByTagName("bookPrice").item(0)
.getTextContent();
String bookAuthor = item.getElementsByTagName("bookAuthor").item(0)
.getTextContent();
System.out.println(bookName + "\t" + bookprice + "\t" + bookAuthor);
}
} /**
* 添加节点
*
* @throws Exception
*/
public static void add() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 伪造节点
Element createElement = document.createElement("book");
// 给节点属性赋值
createElement.setAttribute("id", "004");
createElement.setAttribute("type", "动漫专题");
// 伪造节点的子节点
Element bookName = document.createElement("bookName");
bookName.setTextContent("樱桃小丸子");
Element bookPrice = document.createElement("bookPrice");
bookPrice.setTextContent("20");
Element bookAuthor = document.createElement("bookAuthor");
bookAuthor.setTextContent("无名");
// 将三个节点绑定到一个节点下。变成某一节点的子节点
createElement.appendChild(bookName);
createElement.appendChild(bookPrice);
createElement.appendChild(bookAuthor);
// 把新建的节点,添加到根节点下
document.getElementsByTagName("books").item(0)
.appendChild(createElement);
// 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("add ok"); }
/**
* 修改节点
*
* @throws Exception
*/
public static void modfiy() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 拿到要修改的节点
Element item = (Element) document.getElementsByTagName("book").item(1);
item.getElementsByTagName("bookName").item(0).setTextContent("我是测试xx"); // 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("add ok");
} /**
* 删除节点
*
* @throws Exception
*/
public static void delete() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 拿到要删除的节点
Element item = (Element) document.getElementsByTagName("book").item(2);
document.getElementsByTagName("books").item(0).removeChild(item); // 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("delete ok");
}
}
2-2)使用SAX与DOM4J解析XML:增删改查读
需要结合DOM4j架包使用:下载链接地址如下:
需要先将架包引用到项目中:
代码演示如下:
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jXml {
public static void main(String[] args) throws Exception {
// 读取XML
// reader();
// 添加XML节点
// addXml();
// 修改节点数据
// modfiy();
// modfiy1();
// 删除节点
// delete();
// delete1();
}
/**
* 读取XML文件
*/
public static void reader() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 遍历根节点下的子节点信息
for (Object item : rootElement.elements()) {
// 拿到子节点下的值
String text = ((Element) item).element("bookName").getText();
System.out.println(text);
// 拿到当前节点的属性值
System.out.println(((Element) item).attribute("id").getText());
}
}
/**
* 向XML文件添加节点
*/
public static void addXml() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 创建要添加的节点
Element createElement = DocumentHelper.createElement("book");
createElement.setAttributeValue("id", "003");
createElement.setAttributeValue("type", "测试数据");
// 创建添加的节点的3个子节点
Element createElement1 = DocumentHelper.createElement("bookName");
createElement1.setText("唔明书");
Element createElement2 = DocumentHelper.createElement("bookPrice");
createElement2.setText("20");
Element createElement3 = DocumentHelper.createElement("bookAuthor");
createElement3.setText("测试");
// 把3个子节点 添加到book节点下
createElement.add(createElement1);
createElement.add(createElement2);
createElement.add(createElement3);
// 把book子节点添加到根节点下
rootElement.add(createElement);
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("add ok");
}
/**
* 修改节点信息
*/
public static void modfiy() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点
for (Object element : rootElement.elements()) {
if (((Element) element).attribute("id").getText().equals("003")) {
((Element) element).element("bookName").setText("数据测试!");
break;
}
}
/**
* ((Element) element).element("bookName").setName("数据测试!");修改节点name名称
*/
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("modfiy ok");
}
/**
* 修改节点信息方案二 Text
*/
public static void modfiy1() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点---方式二 Text true
@SuppressWarnings("unchecked")
List<Object> attributes = (rootElement.elements());
Element ment = (Element) attributes.get(1);
ment.element("bookName").setText("青年测试");
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("modfiy ok");
} /**
* 删除节点信息
*/
public static void delete() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点
for (Object element : rootElement.elements()) {
if (((Element) element).attribute("id").getText().equals("003")) {
rootElement.remove(((Element) element));
break;
}
}
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("delete ok");
} /**
* 删除节点方式二 Text true
*/
public static void delete1() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点---方式二 Text true
@SuppressWarnings("unchecked")
List<Object> attributes = (rootElement.elements());
Element ment = (Element) attributes.get(1);
rootElement.remove(ment);
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("delete ok"); }
}
1)有关XML简介
XML(EXtensible Markup Language)可扩展标记语言
特点:XML与操作系统、编程语言的开发平台无关
实现不同系统之间的数据交换
作用:数据交换、配置应用程序和网站
大致文档结构:
XML文档内容由一系列标签元素组成:
XML编写注意事项:
所有XML元素都必须有结束标签
XML标签对大小写敏感
XML必须正确的嵌套
同级标签以缩进对齐
元素名称可以包含字母、数字或其他的字符
元素名称不能以数字或者标点符号开始
元素名称中不能含空格
XML中的转义符列表:
2)解析XML技术:
DOM:
基于XML文档树结构的解析
适用于多次访问的XML文档
特点:比较消耗资源
SAX:
基于事件的解析
适用于大数据量的XML文档
特点:占用资源少,内存消耗小
DOMJ4:
非常优秀的java XML API
性能优异、功能强大
开放源代码
2-1)DOM解析XML:增删改查d
DOM介绍:文档对象模型(Document Object Model):DOM把XML文档映射成一个倒挂的树
代码演示DOM解析XML
package text; import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlText {
//private static Document parse;
public static void main(String[] args) throws Exception {
// text();
//add();
// delete();
//modfiy();
}
/**
* 循环解析XML
*
* @throws ParserConfigurationException
* @throws SAXException
* @throws IOException
*/
public static void text() throws ParserConfigurationException,
SAXException, IOException {
// 创建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 1.创建解析器对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 2.创建文档对象
Document document = builder.parse("lbl/NewFile.xml");
// 3.拿到节点集合
NodeList list = document.getElementsByTagName("book");
// 4.遍历集合
for (int i = 0; i < list.getLength(); i++) {
// 拿到每个节点
Element item = (Element) list.item(i);
// 解析每个节点属性的值
String bookid = item.getAttribute("id");
String bookType = item.getAttribute("type");
System.out.println(bookid + "\t" + bookType);
// 解析每个节点的子节点的值
String bookName = item.getElementsByTagName("bookName").item(0)
.getTextContent();
String bookprice = item.getElementsByTagName("bookPrice").item(0)
.getTextContent();
String bookAuthor = item.getElementsByTagName("bookAuthor").item(0)
.getTextContent();
System.out.println(bookName + "\t" + bookprice + "\t" + bookAuthor);
}
} /**
* 添加节点
*
* @throws Exception
*/
public static void add() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 伪造节点
Element createElement = document.createElement("book");
// 给节点属性赋值
createElement.setAttribute("id", "004");
createElement.setAttribute("type", "动漫专题");
// 伪造节点的子节点
Element bookName = document.createElement("bookName");
bookName.setTextContent("樱桃小丸子");
Element bookPrice = document.createElement("bookPrice");
bookPrice.setTextContent("20");
Element bookAuthor = document.createElement("bookAuthor");
bookAuthor.setTextContent("无名");
// 将三个节点绑定到一个节点下。变成某一节点的子节点
createElement.appendChild(bookName);
createElement.appendChild(bookPrice);
createElement.appendChild(bookAuthor);
// 把新建的节点,添加到根节点下
document.getElementsByTagName("books").item(0)
.appendChild(createElement);
// 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("add ok"); }
/**
* 修改节点
*
* @throws Exception
*/
public static void modfiy() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 拿到要修改的节点
Element item = (Element) document.getElementsByTagName("book").item(1);
item.getElementsByTagName("bookName").item(0).setTextContent("我是测试xx"); // 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("add ok");
} /**
* 删除节点
*
* @throws Exception
*/
public static void delete() throws Exception {
// 创建工厂
DocumentBuilderFactory newInstance = DocumentBuilderFactory
.newInstance();
// 创建解析器
DocumentBuilder newDocumentBuilder = newInstance.newDocumentBuilder();
// 创建文档对象
Document document = newDocumentBuilder.parse("lbl/NewFile.xml");
// 拿到要删除的节点
Element item = (Element) document.getElementsByTagName("book").item(2);
document.getElementsByTagName("books").item(0).removeChild(item); // 将修改后的文件,重写到硬盘
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 创建转换器
Transformer transfromer = transformerFactory.newTransformer();
// 要传入的数据源
Source source = new DOMSource(document);
// 要传入的路径
Result result = new StreamResult("lbl/NewFile.xml");
// 转换方法
transfromer.transform(source, result);
System.out.println("delete ok");
}
}
2-2)使用SAX与DOM4J解析XML:增删改查读
需要结合DOM4j架包使用:下载链接地址如下:
需要先将架包引用到项目中:
代码演示如下:
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jXml {
public static void main(String[] args) throws Exception {
// 读取XML
// reader();
// 添加XML节点
// addXml();
// 修改节点数据
// modfiy();
// modfiy1();
// 删除节点
// delete();
// delete1();
}
/**
* 读取XML文件
*/
public static void reader() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 遍历根节点下的子节点信息
for (Object item : rootElement.elements()) {
// 拿到子节点下的值
String text = ((Element) item).element("bookName").getText();
System.out.println(text);
// 拿到当前节点的属性值
System.out.println(((Element) item).attribute("id").getText());
}
}
/**
* 向XML文件添加节点
*/
public static void addXml() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 创建要添加的节点
Element createElement = DocumentHelper.createElement("book");
createElement.setAttributeValue("id", "003");
createElement.setAttributeValue("type", "测试数据");
// 创建添加的节点的3个子节点
Element createElement1 = DocumentHelper.createElement("bookName");
createElement1.setText("唔明书");
Element createElement2 = DocumentHelper.createElement("bookPrice");
createElement2.setText("20");
Element createElement3 = DocumentHelper.createElement("bookAuthor");
createElement3.setText("测试");
// 把3个子节点 添加到book节点下
createElement.add(createElement1);
createElement.add(createElement2);
createElement.add(createElement3);
// 把book子节点添加到根节点下
rootElement.add(createElement);
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("add ok");
}
/**
* 修改节点信息
*/
public static void modfiy() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点
for (Object element : rootElement.elements()) {
if (((Element) element).attribute("id").getText().equals("003")) {
((Element) element).element("bookName").setText("数据测试!");
break;
}
}
/**
* ((Element) element).element("bookName").setName("数据测试!");修改节点name名称
*/
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("modfiy ok");
}
/**
* 修改节点信息方案二 Text
*/
public static void modfiy1() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点---方式二 Text true
@SuppressWarnings("unchecked")
List<Object> attributes = (rootElement.elements());
Element ment = (Element) attributes.get(1);
ment.element("bookName").setText("青年测试");
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("modfiy ok");
} /**
* 删除节点信息
*/
public static void delete() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点
for (Object element : rootElement.elements()) {
if (((Element) element).attribute("id").getText().equals("003")) {
rootElement.remove(((Element) element));
break;
}
}
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("delete ok");
} /**
* 删除节点方式二 Text true
*/
public static void delete1() throws Exception {
// 创建读取器
SAXReader reader = new SAXReader();
// 读取xml文档
Document read = reader.read("lbl/NewFile.xml");
// 获取根节点
Element rootElement = read.getRootElement();
// 拿到要修改的节点---方式二 Text true
@SuppressWarnings("unchecked")
List<Object> attributes = (rootElement.elements());
Element ment = (Element) attributes.get(1);
rootElement.remove(ment);
// 重新将XML写入硬盘
OutputStream ou = new FileOutputStream("lbl/NewFile.xml");
Writer wr = new OutputStreamWriter(ou, "utf-8");
read.write(wr);
wr.close();
ou.close();
System.out.println("delete ok"); }
}
Java 持久化操作之 --XML的更多相关文章
- Java 持久化操作
持久化就是将内存中的数据保存起来,使之可以长期存在. 在Java中 可以做到持久化有很多种方法. 其中有: 1. 堵塞型IO,也就是我们经常说的io流: 2. 非堵塞型IO,通常称为New IO.也就 ...
- Java 持久化操作之 --io流与序列化
1)File类操作文件的属性 1.File类的常用方法 1. 文件的绝对完整路径:getAbsolutePath() 文件名:getName() 文件相对路径:getPath() 文件的上一级目录:g ...
- Java文件操作①——XML文件的读取
一.邂逅XML 文件种类是丰富多彩的,XML作为众多文件类型的一种,经常被用于数据存储和传输.所以XML在现今应用程序中是非常流行的.本文主要讲Java解析和生成XML.用于不同平台.不同设备间的数据 ...
- Hibernate 系列 03 - 使用Hibernate完成持久化操作
引导目录: Hibernate 系列教程 目录 康姆昂,北鼻,来此狗.动次打次,Hibernate继续走起. 目录: 使用Hibernate实现按主键查询 使用Hibernate实现数据库的增.删.改 ...
- python数据的存储和持久化操作
Python的数据持久化操作主要是六类:普通文件.DBM文件.Pickled对象存储.shelve对象存储.对象数据库存储.关系数据库存储. 普通文件不解释了,DBM就是把字符串的键值对存储在文件里: ...
- HDFS的Java客户端操作代码(HDFS的查看、创建)
1.HDFS的put上传文件操作的java代码: package Hdfs; import java.io.FileInputStream; import java.io.FileNotFoundEx ...
- Java文件操作源码大全
Java文件操作源码大全 1.创建文件夹 52.创建文件 53.删除文件 54.删除文件夹 65.删除一个文件下夹所有的文件夹 76.清空文件夹 87.读取文件 88.写入文件 99.写入随机文件 9 ...
- Java路径操作具体解释
1.基本概念的理解 绝对路径:绝对路径就是你的主页上的文件或文件夹在硬盘上真正的路径.(URL和物理路径)比如: C:\xyz\test.txt 代表了test.txt文件的绝对路径.http://w ...
- Java数据解析之XML
文章大纲 一.XML解析介绍二.Java中XML解析介绍三.XML解析实战四.项目源码下载 一.XML解析介绍 最基础的XML解析方式有DOM和SAX,DOM和SAX是与平台无关的官方解析方式 ...
随机推荐
- 014-并发编程-java.util.concurrent之-CountDownLatch
一.概述 CountDownLatch是JAVA提供在java.util.concurrent包下的一个辅助类,指定的一个或多个线程等待其他线程执行完成后执行. 能够使一个线程等待其他线程完成各自的工 ...
- 帝国cms建站总结-(分页)
帝国cms分页代码文件t_functions.php 代码为: <?php if(!defined('InEmpireCMS')) { exit(); } define('InEmpireCMS ...
- vue中使用lodash
1.安装:npm i --save lodash 2.引入:import _from 'lodash' 3.使用: <template> <div class="templ ...
- Elemet-技巧
<el-table-column prop="> </el-table-column> 效果: append-to-body 解决el-dialog 弹窗遮罩为题 & ...
- COFF,amd64.vc90.mfc两个布署的问题
今天解决了两个bug (1)一个是COFF文件损坏,因为装了vs2010和vs2013,搜索C:\Program Files(x86)文件夹下的cvtres.exe.出现了VC10和VC12的4个,x ...
- WIN32,_WIN32_WIN64
MSDN 里说,VC 有 3 个预处理常量,分别是 _WIN32,_WIN64,WIN32. 只要包含了 Windows.h,那么 WIN32 常量是肯定定义了的,所以不能用于判断平台环境(如果x64 ...
- [ Linux运维学习 ] 路径及实战项目合集
我们知道运维工程师(Operations)最基本的职责就是负责服务的稳定性并确保整个服务的高可用性,同时不断优化系统架构.提升部署效率.优化资源利用率,确保服务可以7*24H不间断地为用户提供服务. ...
- ios9 适配的坑
http://www.cocoachina.com/ios/20151016/13715.html
- JAVA比较两个List集合的方法
import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.H ...
- shell实现SSH自动登陆【转】
前言 公司开发使用docker,每次登陆自己开发机总要输入 ssh user_name@ip_string,然后再确认输入password,手快了还经常会输错.作为一个懒人,肯定要找一个取巧的方式,查 ...