深入理解java虚拟机---对象的结构(九)

注意: 我们可以看到的就是InstanceData的数据.
先转载一篇文章作为开头,因为讲的非常详细,我就简单加工下放到这里:
对象结构
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。下图是普通对象实例与数组对象实例的数据结构:
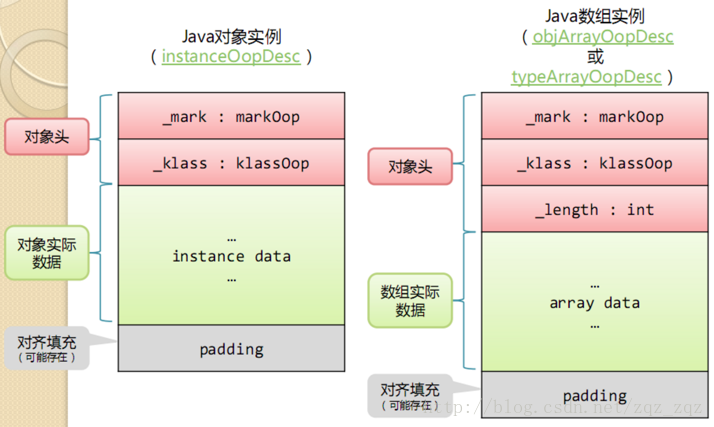
对象头
HotSpot虚拟机的对象头包括两部分信息:
- markword
第一部分markword,用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称它为“MarkWord”。 - klass
对象头的另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例. - 数组长度(只有数组对象有)
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度.
实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充
第三部分对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
对象大小计算
要点
1. 在32位系统下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
2. 在64位系统下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
3. 64位开启指针压缩的情况下,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。 数组长度4字节+数组对象头8字节(对象引用4字节(未开启指针压缩的64位为8字节)+数组markword为4字节(64位未开启指针压缩的为8字节))+对齐4=16字节。
4. 静态属性不算在对象大小内。
以上内容转载自http://blog.csdn.net/lihuifeng/article/details/51681146
补充:
HotSpot对象模型
HotSpot中采用了OOP-Klass模型,它是描述Java对象实例的模型,它分为两部分:
- 类被加载到内存时,就被封装成了klass,klass包含类的元数据信息,像类的方法、常量池这些信息都是存在klass里的,你可以认为它是java里面的java.lang.Class对象,记录了类的全部信息;
- OOP(Ordinary Object Pointer)指的是普通对象指针,它包含MarkWord 和元数据指针,MarkWord用来存储当前指针指向的对象运行时的一些状态数据;元数据指针则指向klass,用来告诉你当前指针指向的对象是什么类型,也就是使用哪个类来创建出来的;
- 那么为何要设计这样一个一分为二的对象模型呢?这是因为HotSopt JVM的设计者不想让每个对象中都含有一个vtable(虚函数表),所以就把对象模型拆成klass和oop,其中oop中不含有任何虚函数,而klass就含有虚函数表,可以进行method dispatch。
HotSpot中,OOP-Klass实现的代码都在/hotspot/src/share/vm/oops/路径下,oop的实现为instanceOop 和 arrayOop,他们来描述对象头,其中arrayOop对象用于描述数组类型。
以下就是oop.hhp文件中oopDesc的源码,可以看到两个变量_mark就是MarkWord,_metadata就是元数据指针,指向klass对象,这个指针压缩的是32位,未压缩的是64位;
volatile markOop _mark; //标识运行时数据
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata; //klass指针
- 1
- 2
- 3
- 4
- 5
- 6
一个Java对象在内存中的布局可以连续分成两部分:instanceOop(继承自oop.hpp)和实例数据;
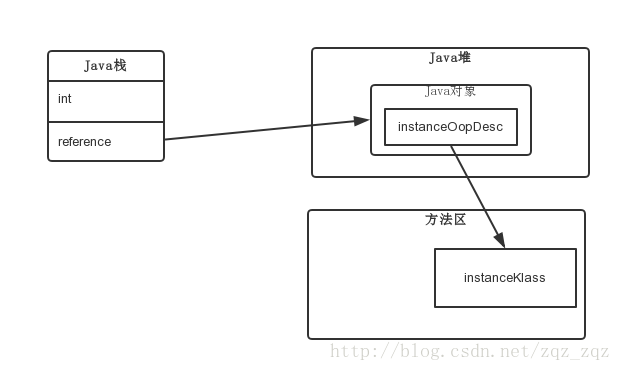
上图可以看到,通过栈帧中的对象引用reference找到Java堆中的对象,再通过对象的instanceOop中的元数据指针klass来找到方法区中的instanceKlass,从而确定该对象的类型。
下面来分析一下,执行new A()的时候,JVM 做了什么工作。首先,如果这个类没有被加载过,JVM就会进行类的加载,并在JVM内部创建一个instanceKlass对象表示这个类的运行时元数据(相当于Java层的Class对象)。初始化对象的时候(执行invokespecial A::),JVM就会创建一个instanceOopDesc对象表示这个对象的实例,然后进行Mark Word的填充,将元数据指针指向Klass对象,并填充实例变量。
元数据—— instanceKlass 对象会存在元空间(方法区),而对象实例—— instanceOopDesc 会存在Java堆。Java虚拟机栈中会存有这个对象实例的引用。
成员变量重排序
为了提高性能,每个对象的起始地址都对齐于8字节,当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
- double (8字节) 和 long (8字节)
- int (4字节) 和 float (4字节)
- short (2字节) 和 char (2字节):char在java中是2个字节。java采用unicode,2个字节(16位)来表示一个字符。
- boolean (1字节) 和 byte (1字节)
- reference引用 (4/8 字节)
子类字段重复上述顺序。
我们可以测试一下java对不同类型的重排序,使用jdk1.8,采用反射的方式先获取到unsafe类,然后获取到每个field在类里面的偏移地址,就能看出来了
测试代码如下:
import java.lang.reflect.Field;
import sun.misc.Contended;
import sun.misc.Unsafe;
public class TypeSequence {
@Contended
private boolean contended_boolean;
private volatile byte a;
private volatile boolean b;
@Contended
private int contended_short;
private volatile char d;
private volatile short c;
private volatile int e;
private volatile float f;
@Contended
private int contended_int;
@Contended
private double contended_double;
private volatile double g;
private volatile long h;
public static Unsafe UNSAFE;
static {
try {
@SuppressWarnings("ALL")
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws NoSuchFieldException, SecurityException{
System.out.println("e:int \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("e")));
System.out.println("g:double \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("g")));
System.out.println("h:long \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("h")));
System.out.println("f:float \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("f")));
System.out.println("c:short \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("c")));
System.out.println("d:char \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("d")));
System.out.println("a:byte \t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("a")));
System.out.println("b:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("b")));
System.out.println("contended_boolean:boolean\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_boolean")));
System.out.println("contended_short:short\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_short")));
System.out.println("contended_int:int\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_int")));
System.out.println("contended_double:double\t"+UNSAFE.objectFieldOffset(TypeSequence.class.getDeclaredField("contended_double")));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
以上代码运行结果如下
e:int 12
g:double 16
h:long 24
f:float 32
c:short 38
d:char 36
a:byte 40
b:boolean 41
contended_boolean:boolean 170
contended_short:short 300
contended_int:int 432
contended_double:double 568- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
除了int字段跑到了前面来了,还有两个添加了contended注解的字段外,其它字段都是按照重排序的顺序,类型由最长到最短的顺序排序的;
对象头对成员变量排序的影响
有的童鞋疑惑了,为啥int跑到前面来了呢?这是因为int字段被提升到前面填充对象头了,对象头有12个字节,会优先在字段中选择一个或多个能够将对象头填充为16个字节的field放到前面,如果填充不满,就加上padding,上面的例子加上一个4字节的int,正好是16字节,地址按8字节对齐;
扩展contended对成员变量排序的影响
那么contended注解呢?这个注解是为了解决cpu缓存行伪共享问题的,cpu缓存伪共享是并发编程性能杀手,不知道什么是伪共享的可以查看我前面写的LongAdder类的源码解读 或者《java 中的锁 – 偏向锁、轻量级锁、自旋锁、重量级锁》这篇文章都有讲到,加了contended注解的字段会按照声明的顺序放到末尾,contended注解如果是用在类的field上会在该field前面插入128字节的padding,如果是用在类上则会在类所有field的前后都加上128字节的padding。
深入理解java虚拟机---对象的结构(九)的更多相关文章
- 深入理解java虚拟机---对象的访问定位(十)
引用其他人的文章: https://www.cnblogs.com/YYfish/p/6722258.html 那是怎么访问对象呢? java 程序是通过栈上的reference数据来操作堆上的具体对 ...
- 《深入理解java虚拟机》-目录结构
第一部分 走进Java第1章 走进Java 第二部分 自动内存管理机制 第2章 Java内存区域与内存溢出异常2.1 概述2.2 运行时数据区域2.2.1 程序计数器2.2.2 java虚拟机栈2.2 ...
- 《深入理解java虚拟机》读书笔记九——第十章
第十章 早期(编译期)优化 1.Javac的源码与调试 编译期的分类: 前端编译期:把*.java文件转换为*.class文件的过程.例如sun的javac.eclipseJDT中的增量编译器. JI ...
- 《深入理解Java虚拟机》读书笔记九
第十章 早期(编译期)优化 1.Javac的源码与调试 编译期的分类: 前端编译期:把*.java文件转换为*.class文件的过程.例如sun的javac.eclipseJDT中的增量编译器. JI ...
- 深入理解Java虚拟机—JVM内存结构
1.概述 jvm内存分为线程共享区和线程独占区,线程独占区主要包括虚拟机栈.本地方法栈.程序计数器:线程共享区包括堆和方法区 2.线程独占区 虚拟机栈 虚拟机栈描述的是java方法执行的动态内存模型, ...
- 深入理解java虚拟机---对象的创建过程(八)
1.对象的创建过程 由于类的加载是一个很复杂的过程,所以这里暂时略过,后面会详细讲解,默认为是已加载过的类.着重强调对象的创建过程. 注意: 最后一步的init方法是代码块和构造方法. 以上是总图,下 ...
- 深入理解java虚拟机---java内存区域与内存溢出异常---1内存结构
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
- 《深入理解 Java 虚拟机》笔记整理
正文 一.Java 内存区域与内存溢出异常 1.运行时数据区域 程序计数器:当前线程所执行的字节码的行号指示器.线程私有. Java 虚拟机栈:Java 方法执行的内存模型.线程私有. 本地方法栈:N ...
- 《深入理解Java虚拟机》虚拟机性能监控与故障处理工具
上节学习回顾 从课本章节划分,<垃圾收集器>和<内存分配策略>这两篇随笔同属一章节,主要是从理论+实验的手段来讲解JVM的内存处理机制.好让我们对JVM运行机制有一个良好的概念 ...
随机推荐
- makefile 里的vpath
https://www.cmcrossroads.com/article/basics-vpath-and-vpath Only missing prerequisites matching the ...
- AngularJS参数绑定 --AngularJS
AngularJS参数绑定有三种方式.第一种插值表达式“{{}}”表示,第二种在标签中使用ng-bind属性表示,第三种针对input框(标签)的ng-module属性表示.针对三种参数绑定方式,设定 ...
- 11月29日 The Rails philosophy 完成rails on guide 的第一章getting started with rails
the rails philosophy includes two major guiding principles: Don't repeat yourself: DRY is a principl ...
- sass制作雪碧图
1.配置文件config.rb http_path = "../../../" css_dir = "Content/css" sass_dir = " ...
- 架构探险笔记11-与Servlet API解耦
Servlet API解耦 为什么需要与Servlet API解耦 目前在Controller中是无法调用Servlet API的,因为无法获取Request与Response这类对象,我们必须在Di ...
- find xss
from :http://blog.sina.com.cn/s/blog_68d342d90100nh7b.html 什么是XSS跨站攻击: http://baike.baidu.com/view/5 ...
- QPS 机器计算公式
QPS = req/sec = 请求数/秒 QPS = 总请求数 / ( 进程总数 * 请求时间 )QPS: 单个进程每秒请求服务器的成功次数 原理:每天80%的访问集中在20%的时间里,这20%时间 ...
- linux 查看日志命令
linux中命令cat.more.less均可用来查看文件内容, 区别:cat是一次性显示整个文件的内容,还可以将多个文件连接起来显示,它常与重定向符号配合使用,适用于文件内容少的情况:more和le ...
- JAVA正则表达式:Pattern、Matcher、String
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包.它包括两个类:Pattern和Matcher Pattern 一个Pattern是一个正则表达式经编译后的表 ...
- Spring注解之 @SuppressWarnings注解
简介:java.lang.SuppressWarnings是J2SE5.0中标准的Annotation之一.可以标注在类.字段.方法.参数.构造方法,以及局部变量上.作用:告诉编译器忽略指定的警告,不 ...