关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0
hive版本:1.2.1
需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spark-sql程序实现将该文件读取并以parquet的格式通过外部表的形式保存到hive中,最终要实现通过传参的形式,将该日期区间内的csv文件批量加载进去,方式有两种:
1、之传入一个参数,说明只加载一天的数据进去
2、传入两个参数,批量加载这两个日期区间的每一天的数据
最终打成jar包,进行运行
步骤如下:
1、初始化配置,先创建sparkSession(spark2.0版本开始将sqlContext、hiveContext同意整合为sparkSession)
//初始化配置
val spark = new sql.SparkSession
.Builder()
.enableHiveSupport() //操作hive这一步千万不能少
.appName("project_1")
.master("local[2]")
.getOrCreate()
2、先将文件读进来,并转换为DF
val data = spark.read.option("inferSchema", "true").option("header", "false") //这里设置是否处理头信息,false代表不处理,也就是说文件的第一行也会被加载进来,如果设置为true,那么加载进来的数据中不包含第一行,第一行被当作了头信息,也就是表中的字段名处理了
.csv(s"file:///home/spark/file/project/${i}visit.txt") //这里设置读取的文件,${i}是我引用的一个变量,如果要在双引号之间引用变量的话,括号前面的那个s不能少
.toDF("mac", "phone_brand", "enter_time", "first_time", "last_time", "region", "screen", "stay_time") //将读进来的数据转换为DF,并为每个字段设置字段名
3、将转换后的DF注册为一张临时表
data.createTempView(s"table_${i}")
4、通过spark-sql创建hive外部表,这里有坑
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) stored as parquet
|location 'hdfs://master:9000/project_dest/${i}'
""".stripMargin)
这里的见表语句需要特别注意,如果写成如下的方式是错误的:
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) row format delimited fields terminated by '\t' stored as parquet
|location /project_dest/${i}'
""".stripMargin)
(1)对于row format delimited fields terminated by '\t'这语句只支持存储文件格式为textFile,对于parquet文件格式不支持
(2)对于location这里,一定要写hdfs的全路径,如果向上面这样写,系统不认识,切记
5、通过spark-sql执行insert语句,将数据插入到hive表中
spark.sql(s"insert overwrite table ${i}visit select * from table_${i}".stripMargin)
至此,即完成了将本地数据以parquet的形式加载至hive表中了,接下来既可以到hive表中进行查看数据是否成功载入
贴一下完整代码:
package _sql.project_1 import org.apache.spark.sql /**
* Author Mr. Guo
* Create 2018/9/4 - 9:04
* ┌───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┐
* │Esc│ │ F1│ F2│ F3│ F4│ │ F5│ F6│ F7│ F8│ │ F9│F10│F11│F12│ │P/S│S L│P/B│ ┌┐ ┌┐ ┌┐
* └───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┘ └┘ └┘ └┘
* ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───────┐ ┌───┬───┬───┐ ┌───┬───┬───┬───┐
* │~ `│! 1│@ 2│# 3│$ 4│% 5│^ 6│& 7│* 8│( 9│) 0│_ -│+ =│ BacSp │ │Ins│Hom│PUp│ │N L│ / │ * │ - │
* ├───┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─────┤ ├───┼───┼───┤ ├───┼───┼───┼───┤
* │ Tab │ Q │ W │ E │ R │ T │ Y │ U │ I │ O │ P │{ [│} ]│ | \ │ │Del│End│PDn│ │ 7 │ 8 │ 9 │ │
* ├─────┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴─────┤ └───┴───┴───┘ ├───┼───┼───┤ + │
* │ Caps │ A │ S │ D │ F │ G │ H │ J │ K │ L │: ;│" '│ Enter │ │ 4 │ 5 │ 6 │ │
* ├──────┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴────────┤ ┌───┐ ├───┼───┼───┼───┤
* │ Shift │ Z │ X │ C │ V │ B │ N │ M │< ,│> .│? /│ Shift │ │ ↑ │ │ 1 │ 2 │ 3 │ │
* ├─────┬──┴─┬─┴──┬┴───┴───┴───┴───┴───┴──┬┴───┼───┴┬────┬────┤ ┌───┼───┼───┐ ├───┴───┼───┤ E││
* │ Ctrl│ │Alt │ Space │ Alt│ │ │Ctrl│ │ ← │ ↓ │ → │ │ 0 │ . │←─┘│
* └─────┴────┴────┴───────────────────────┴────┴────┴────┴────┘ └───┴───┴───┘ └───────┴───┴───┘
**/ object Spark_Sql_Load_Data_To_Hive {
//初始化配置
val spark = new sql.SparkSession
.Builder()
.enableHiveSupport()
.appName("project_1")
.master("local[2]")
.getOrCreate() //设置日志的级别
spark.sparkContext.setLogLevel("WARN") def main(args: Array[String]): Unit = { try {
if (args.length != 1) {
data_load(args(0).toInt)
} else if (args.length != 2) {
for (i <- args(0).toInt to args(1).toInt) {
data_load(i)
}
} else {
System.err.println("Usage:<start_time> or <start_time> <end_time>")
System.exit(1)
}
}catch {
case ex:Exception => println("Exception")
}finally{
spark.stop()
}
}
def data_load(i:Int): Unit = {
println(s"*******data_${i}********")
val data = spark.read.option("inferSchema", "true").option("header", "false")
.csv(s"file:///home/spark/file/project/${i}visit.txt")
.toDF("mac", "phone_brand", "enter_time", "first_time", "last_time", "region", "screen", "stay_time")
data.createTempView(s"table_${i}")
spark.sql("use project_1".stripMargin)
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) stored as parquet
|location 'hdfs://master:9000/project_dest/${i}'
""".stripMargin)
spark
.sql(s"insert overwrite table ${i}visit select * from table_${i}".stripMargin)
}
}
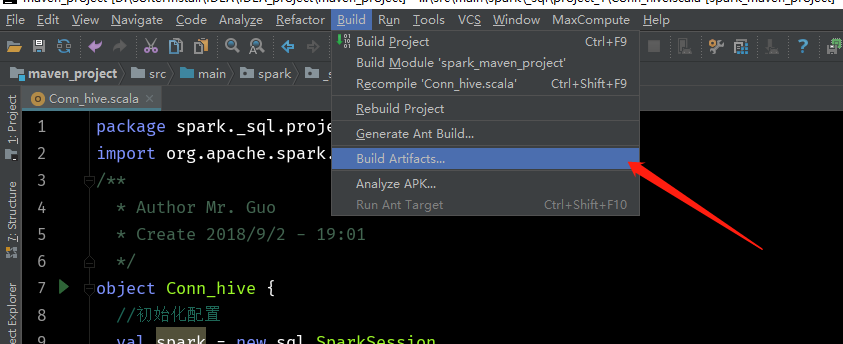
6、打成jar包(我的IDEA版本是2017.3版本)
如果没有上面这一栏,点击View,然后勾选Toolbar即可
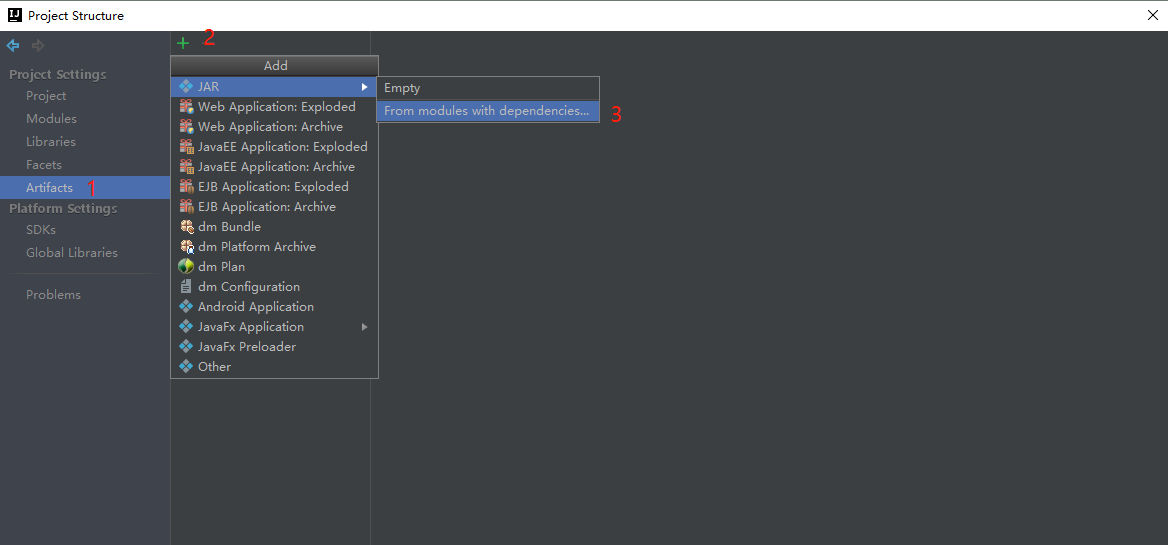
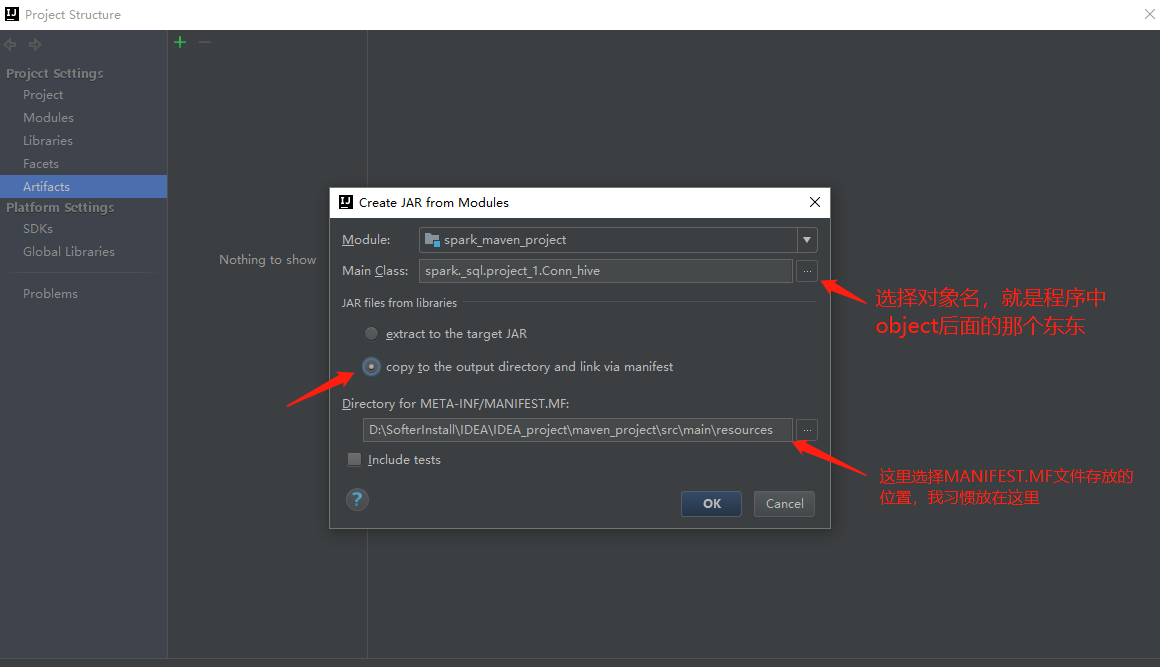
点击ok
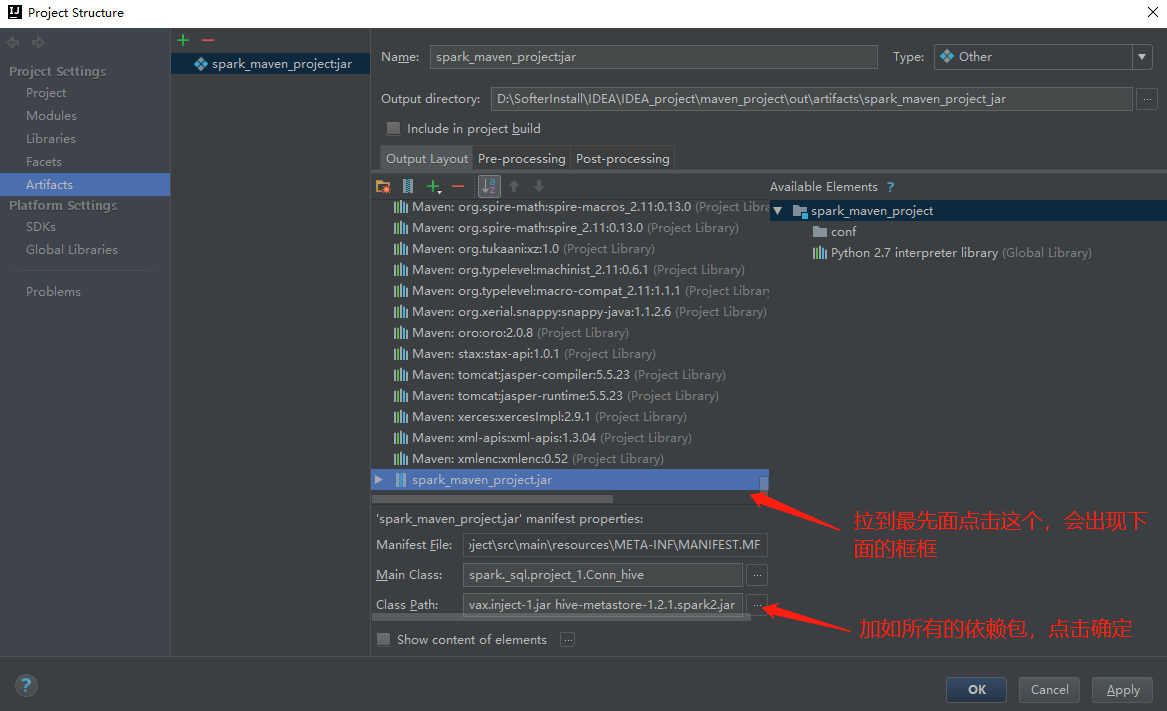
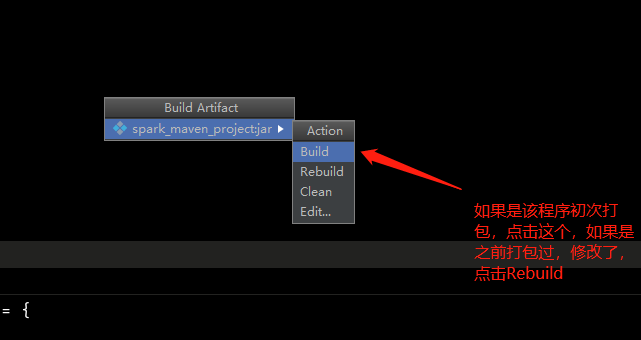
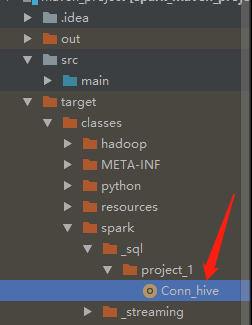
此时这里会成成这么一个文件,是编译之后的class文件

到这个目录下会找到这么一个jar包

找到该文件夹,上传到服务器,cd到该目录下运行命令:
spark-submit --class spark._sql.project_1.Conn_hive --master spark://master:7077 --executor-memory 2g --num-executors 3 /spark_maven_project.jar 20180901 20180910
关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中的更多相关文章
- jmeter读取本地CSV文件
用jmeter录制考试上传成绩等脚本时,出现的问题及解决方法如下: 1.beanshell前置处理器,不能读取本地csv文件里的数据: 方法一: 在beanshell里不能直接从本地的csv文件里读取 ...
- Mysql加载本地CSV文件
Mysql加载本地CSV文件 1.系统环境 系统版本:Win10 64位 Mysql版本: 8.0.15 MySQL Community Server - GPL Mysql Workbench版本: ...
- 读取gzmt.csv文件,计算均值及概率
问题: 读取gzmt.csv文件所有数据,选取收盘价格(倒数第二列),计算20天均值,权重取成交量(选做:时间权重为半衰期为15天):将该均值修剪为超过600的都设置为1000,并打印出该均值超过55 ...
- 读取本地json文件,并转换为dictionary
// 读取本地JSON文件 - (NSDictionary *)readLocalFileWithName:(NSString *)name { // 获取文件路径 NSString *path = ...
- jQuery ajax读取本地json文件
jQuery ajax读取本地json文件 json文件 { "first":[ {"name":"张三","sex": ...
- JavaScript读取本地json文件
JavaScript读取本地json文件 今天调试了一上午,通过jQuery读取本地json文件总是失败,始终找不出原因,各种方法都试了 开始总以为是不是json格式的问题.高了半天不行 后来读了一个 ...
- 读取本地json文件,转出为指定格式json 使用Base64进行string的加密和解密
读取本地json文件,转出为指定格式json 引用添加Json.Net 引用命名空间 using Newtonsoft.Json //读取自定目录下的json文件StreamReader sr = ...
- JAVA读取本地html文件里的html文本
/** * 读取本地html文件里的html代码 * @param file File file=new File("文件的绝对路径") * @return */ public s ...
- C语言读取写入CSV文件 [一]基础篇
本系列文章目录 [一] 基础篇 [二] 进阶篇--写入CSV [三] 进阶篇--读取CSV 什么是CSV? CSV 是一种以纯文本形式存储的表格数据,具体介绍如下(来自维基百科): 逗号分隔值(Com ...
随机推荐
- 20145326蔡馨熤《网络对抗》—— Web基础
20145326蔡馨熤<网络对抗>—— Web基础 1.实验后回答问题 (1)什么是表单. 表单是一个包含表单元素的区域,表单元素是允许用户在表单中输入信息的元素,表单在网页中主要负责数据 ...
- stm32最简单的实现BootLoader
BootLoader大家应该都知道是干什么的,简单的来说就是程序开始运行前的一段程序. 在成熟的产品中,通常都是采用BootLoader方式来升级产品的程序.也就是IAP升级.在了解完基本的实现原理后 ...
- java常用类-StringBuffer,Integer,Character
* StringBuffer: * 线程安全的可变字符串. * * StringBuffer和String的区别? * 前者长度和内容可变,后者不可变. * 如果使用前者做字符串的拼接,不会浪费太多的 ...
- Django框架 (一) 虚拟环境配置及简单使用
虚拟环境 什么是虚拟环境 对真实的python解释器的一个拷贝版本 是事实有效的,可以独立存在运行解释python代码 可以在计算机上拷贝多个虚拟环境 为什么要使用虚拟环境 保证真实环境的纯净性 框架 ...
- P5091 【模板】欧拉定理
思路 欧拉定理 当a与m互质时 \[ a^ {\phi (m)} \equiv 1 \ \ (mod\ m) \] 扩展欧拉定理 当a与m不互质且\(b\ge \phi(m)\)时, \[ a^b \ ...
- (转载)winform图片标尺控件
最近要做个winform的东西,要在里面集成一个类似Windows自带画图的标尺功能,还要能在图片上画矩形框.在网上找了好久也没找到写好的控件,无奈自己做了一个. 目前还有些bug,这里先做个分享.( ...
- 如何快速获取properties中的配置属性值
本文为博主原创,未经博主允许,不得转载: 在项目中,经常需要将一些配置的常量信息放到properties文件中,这样在项目的配置变动的时候,只需要修改配置文件中 对应的配置常量即可. 在项目应用中,如 ...
- TortoiseGit自动记住用户名密码的方法
TortoiseGit自动记住用户名密码的方法 windows下比较比较好用的git客户端有2种: msysgit + TortoiseGit(乌龟git) GitHub for Windows gi ...
- js旋转V字俄罗斯方块
实现效果如图,也就是一个图像的旋转.注意,旋转后的文字是相对应的,而且文字还是立起的.第一次点击时显示,第二次点击时开始旋转.下面是我做这个效果的记录,方法这么差,我也就不说什么了. 先上HTML/C ...
- java复制文件夹中的所有文件和文件夹到另一个文件夹中
1.复制文件夹 public static void copyDir(String oldPath, String newPath) throws IOException { File file = ...