360搜索引擎取真实地址-python代码
还是个比较简单的,不像百度有加密算法
分析
http://www.so.com/link?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452&q=inurl%3Anews.do&ts=1488978912&t=89c5361a44fe3f52931d25c6de262bb&src=haosou
网址是上面这个样子,没加密直接取就好了,去掉头http://www.so.com/link?url=和尾&q=一直到末尾的部分,剩下的就可以吃了
那么规则我们就可以写出来了
a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]
a['href']是待处理网址,a['href'].index('?url='):a['href'].index('&q=')的部分为?url=http%3A%2F%2Fedu.sd.chinamobile.com%2Findex%2Fnews.do%3Faction%3DnoticeDetail%26id%3D22452
最后还需要用unquote解码
- 在python3中是
urllib.parse.unquote - 在python2中是
urllib.unquote
code
import requests
from bs4 import BeautifulSoup
from urllib.parse import unquote
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#爬取360搜索引擎真实链接,第一个参数关键词str,第二个参数爬取页数int
def parse360(keyword, pagenum):
keywordsBaseURL = 'https://www.so.com/s?q=' + str(keyword) + '&pn='
pnum = 1
while pnum <= int(pagenum):
baseURL = keywordsBaseURL + str(pnum)
try:
request = requests.get(baseURL, headers=headers)
soup = BeautifulSoup(request.text, "html.parser")
urls = [unquote(a['href'][a['href'].index('?url='):a['href'].index('&q=')][5:]) for a in soup.select('li.res-list > h3 > a')]
for url in urls:
yield url
except:
yield None
finally:
pnum += 1
用法示例:
def main():
for url in parse360("keyword",10):
if url:
print url
else:
continue
if __name__ == '__main__':
main()
最后上一张测试图
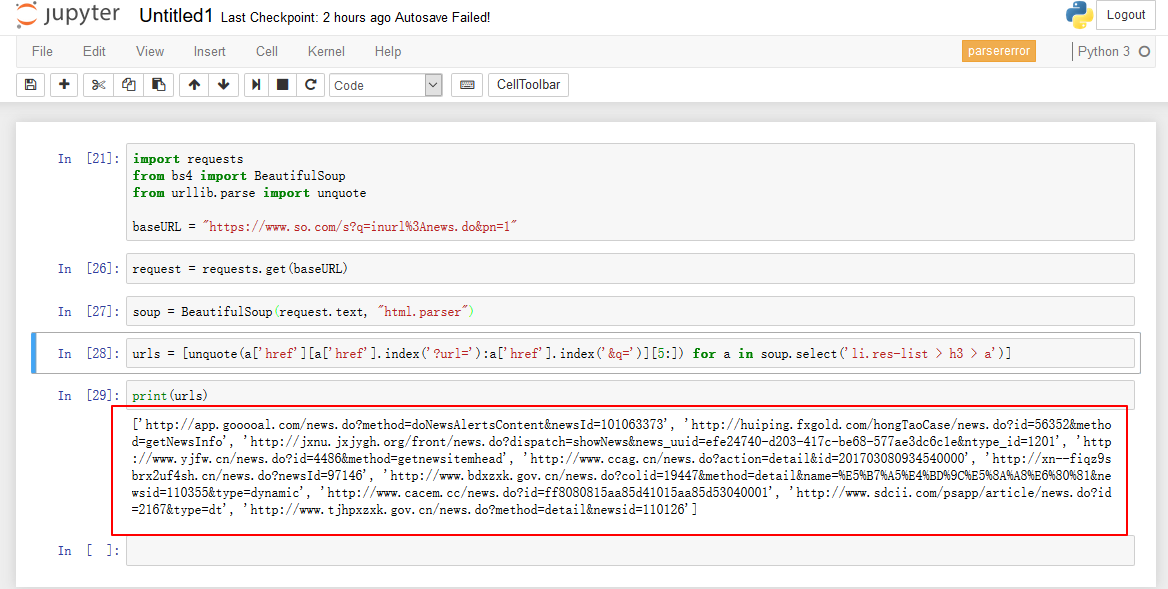
转载请注明出处
360搜索引擎取真实地址-python代码的更多相关文章
- 百度搜索引擎取真实地址-python代码
代码 def parseBaidu(keyword, pagenum): keywordsBaseURL = 'https://www.baidu.com/s?wd=' + str(quote(key ...
- 抓取oschina上面的代码分享python块区下的 标题和对应URL
# -*- coding=utf-8 -*- import requests,re from lxml import etree import sys reload(sys) sys.setdefau ...
- C#取真实IP地址及分析
说一哈,我也是转来的,不是想骗PV,方便自己查而已! 目前网上流行的所谓"取真实IP地址"的方法,都有bug,没有考虑到多层透明代理的情况. 多数代码类似: string IpAd ...
- JSP 获取真实IP地址的代码
[转载]JSP 获取真实IP地址的代码 JSP 获取真实IP地址的代码 在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的. ...
- 【转载】JSP 获取真实IP地址的代码
JSP 获取真实IP地址的代码 在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的. 但是在通过了 Apache,Squid ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
随机推荐
- 2017高教杯数学建模B 题分析
B题原文 "拍照赚钱"是移动互联网下的一种自助式服务模式.用户下载APP,注册成为APP的会员,然后从APP上领取需要拍照的任务(比如上超市去检查某种商品的上架情况),赚取APP对 ...
- <4>Cocos Creator基本概念(场景树 节点 坐标 组件 )
1.场景树 Cocos Creator是由一个一个的游戏场景组成,场景是一个树形结构,场景由 有各种层级关系的节点(下一节有具有介绍)组成: 如创建一个HelloWorld的默认项目NewProjec ...
- js切换背景颜色
我将全部的代码上传到了github,你可以下载查看 <!-------change the background color--------------> <script> f ...
- 【转】win中IDLE选择virtualenv的启动方法
从dos命令行运行.(virtualenv dir)\Scripts\activate.bat脚本激活环境,然后执行: python -m idlelib.idle 摘录:https://blog.c ...
- HttpServletRequestWrapper
1). why 需要改变从 Servlet 容器 (可能是任何的 Servlet 容器)中传入的 HttpServletRequest 对象的某个行为,该怎么办? 一. 继承 HttpServletR ...
- 怎么查 ODBC Driver for SQL Server
1)进入服务器,找到SQL Server 2016 Configuration... ,点进去就好了 2)
- java 泛型E T ?的区别
Java泛型中的标记符含义: E - Element (在集合中使用,因为集合中存放的是元素) T - Type(Java 类) K - Key(键) V - Value(值) N - Number ...
- flask 文件上传(单文件上传、多文件上传)
文件上传 在HTML中,渲染一个文件上传字段只需要将<input>标签的type属性设为file,即<input type=”file”>. 这会在浏览器中渲染成一个文件上传字 ...
- c# 图像呈现控件PictureBox
在c#中可以使用PictureBox控件来呈现图像,图像资源可以来自文件,也可以是存在内存中的位图对象.可以显示本地图像文件或来自网络的图片,也可以来自项目文件中的图像. 从URI加载图像文件. 调用 ...
- HashMap 和 ConcurrentHashMap比较
基础知识: 1. ConcurrentHashMap: (JDK1.7) segment数组,分段锁:segment 内部是 HashEnty数组,类似HashMap: 统计长度的方法,先不加锁统计两 ...