mysql 查询优化~join算法
一简介:参考了几位师兄,尤其是M哥大神的博客,让我恍然大悟,赶紧记录下
二 原理:
mysql的三种算法
1 Simple Nested-Loop Join

将驱动表/外部表的结果集作为循环基础数据,然后循环从该结果集每次一条获取数据作为下一个表的过滤条件查询数据,然后合并结果。如果有多表join,则将前面的表的结果集作为循环数据,取到每行再到联接的下一个表中循环匹配,获取结果集返回给客户端。
注意点:单条记录一条一条进行 比如C 表有N条记录去匹配D表 M 条记录那么要执行 NXM次,如果多表join,那么次数会更多
关键字 笛卡尔积
2 Block Nested-Loop Join
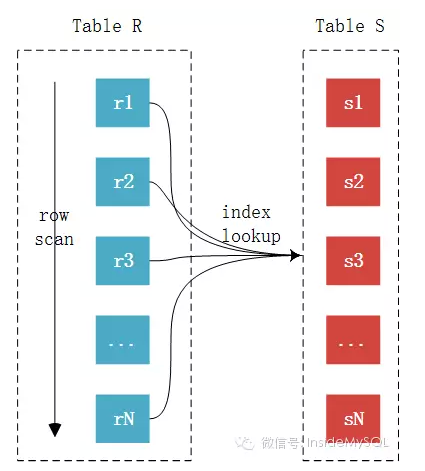
BNL优化,在join字段无索引的情况下
Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer,使用join buffer将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与非驱动表进行比较,这也来实现的话,可以将多次比较合并到一次,降低了非驱 动表的访问频率。也就是只需要访问一次S表。这样来说的话,就不会出现多次访问非驱动表的情况了,也只有这种情况下才会访问join buffer。
注意点:
1 此算法并非单条记录匹配,而是多条记录合并一起匹配,减少了匹配次数,提高了效率
2 此优化手段是在mysql5.5+版本开始出现,默认是打开状态
3 出现标识
explain生成解析树后出现 Using join buffer (Block Nested Loop) 连接字段无索引,但是利用了BNL优化了语句
4 能够被buffer的每一个join都会分配一个buffer, 也就是说一个query最终可能会使用多个join buffer
5 join buffer中只会保存参与join的列, 并非整个数据行。
6 只有在join类型为all, index, range的时候才可以使用join buffer。
3 Index Nested-Loop Join
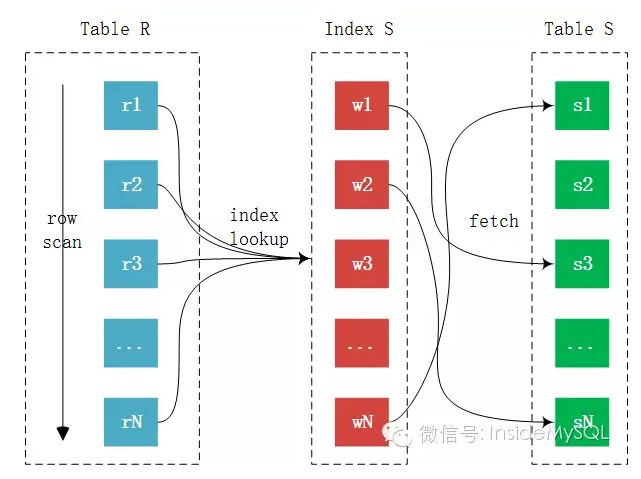
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。至于驱动表的选择,MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时候不排除会出现错误选择。
注意点:
mysql多表join速度之所以慢的原因之一 就是连接字段和查询条件都并非主键,访问辅助索引或者无索引列 一旦要获取列值,必然要回表,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。属于随机IO的操作
三 相关总结:
1 多表join查询要保证小结果集驱动大结果集作为优化选择
2 减少回表操作和匹配次数是算法的核心思想
3 多表join查询要保证连接join的字段都有索引
4 varchar作为主键进行连接查询是无法走索引的,会出现BNL优化(要特别注意)
5 对于无法走索引的join查询建议拆分或者更改条件
6 对于order by所选择的字段要尽量选用驱动表带索引字段
四 核心的东西来源于M哥的博客
mysql 查询优化~join算法的更多相关文章
- Mysql的join算法
本文转载自Mysql的join算法 导语 在Mysql中,使用Nested-Loop Join的算法思想去优化join,Nested-Loop Join翻译成中文则是"嵌套循环连接" ...
- MySQL Nested-Loop Join算法学习
不知不觉的玩了两年多的MySQL,发现很多人都说MySQL对比Oracle来说,优化器做的比较差,其实某种程度上来说确实是这样,但是毕竟MySQL才到5.7版本,Oracle都已经发展到12c了,今天 ...
- 关于join算法的四篇文章
MySQL Join算法与调优白皮书(一) MySQL Join算法与调优白皮书(二) MySQL Join算法与调优白皮书(三) MySQL Join算法与调优白皮书(四) MariaDB Join ...
- MySQL Join算法与调优白皮书(一)
正文 Inside君发现很少有人能够完成讲明白MySQL的Join类型与算法,网上流传着的要提升Join性能,加大变量join_buffer_size的谬论更是随处可见.当然,也有一些无知的PGer攻 ...
- MySQL Join算法与调优白皮书(二)
Index Nested-Loop Join (接上篇)由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大 ...
- mysql查询优化之二:查询优化器的局限性
在<mysql查询优化之一:mysql查询优化常用方式>一文中列出了一些优化器常用的优化手段.查询优化器在提供这些特性的同时,也存在一定的局限性,这些局限性往往会随着MySQL版本的升级而 ...
- MySQL查询优化(转)
在分析性能欠佳的查询时,应考虑: 1) 应用程序是否正获取超过需要的数据,即访问了过多的行或列. 2) Mysql服务器是否分析了超过需要的行. 如果发现访问的数据行数很大,而生成的结果中数据行很少, ...
- 010 --MySQL查询优化器的局限性
MySQL的万能"嵌套循环"并不是对每种查询都是最优的.不过还好,mysql查询优化器只对少部分查询不适用,而且我们往往可以通过改写查询让mysql高效的完成工作.在这我们先来看看 ...
- MySQL 查询优化之 Block Nested-Loop 与 Batched Key Access Joins
MySQL 查询优化之 Block Nested-Loop 与 Batched Key Access Joins 在MySQL中,可以使用批量密钥访问(BKA)连接算法,该算法使用对连接表的索引访问和 ...
随机推荐
- php-扩展模块查找下载网址
http://pecl.php.net/ 在该网页里面输入想要查找的扩展模块名 如: 搜索结果:
- BZOJ1251序列终结者——非旋转treap
题目描述 网上有许多题,就是给定一个序列,要你支持几种操作:A.B.C.D.一看另一道题,又是一个序列 要支持几种操作:D.C.B.A.尤其是我们这里的某人,出模拟试题,居然还出了一道这样的,真是没技 ...
- AC自动机-HDU2896-模板题
http://acm.hdu.edu.cn/showproblem.php?pid=2896 另一道AC自动机的模板题,不过这题需要记录一下具体的匹配情况. /*------------------- ...
- MT【214】焦点弦长公式
已知椭圆焦点为$F_1(-1,0),F_2(1,0)$,且椭圆与直线$y=x-\sqrt{3}$相切,求(1)椭圆的方程(2)过$F_1$作两条相互垂直的直线$l_1,l_2$与椭圆相交于$P,Q,M ...
- MT【210】四点共圆+角平分线
(2018全国联赛解答最后一题)在平面直角坐标系$xOy$中,设$AB$是抛物线$y^2=4x$的过点$F(1,0)$的弦,$\Delta{AOB}$的外接圆交抛物线于点$P$(不同于点$A,O,B$ ...
- Activity的跳转与传值
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://android.blog.51cto.com/268543/323982 Acti ...
- SQL Server 增、删、改、小部分查
--现有三个表Student.Score.Course.Teacher create table Student ( Sno ) not null,--学号 Sname ) not null,--姓名 ...
- windows & gcc & mingw & mysy 编译 openssl
今天有一个项目需要使用到 https, 以前一直用的都是http请求, 用 socket() 实现 https 请求我还真是头一回遇到. 先网上搜索了一下相关资料,明白了 https 相比较 http ...
- ReactNative快速入门
首先放图 这就是我通过简单的搭建环境写出的helloworld和使用的button组件. 那么搭建环境如何搭建呢? 使用的软件有:Node 最新版,Python2.7,Android环境要有配置And ...
- (stripTrailingZeros)A == B hdu2054
A == B ? 链接:http://acm.hdu.edu.cn/showproblem.php?pid=2054 Problem Description Give you two numbers ...