Python中结巴分词使用手记
手记实用系列文章:
3 自然语言处理手记
结巴分词方法封装类
from __future__ import unicode_literals
import sys
sys.path.append("../") import jieba
import jieba.posseg
import jieba.analyse print('='*40)
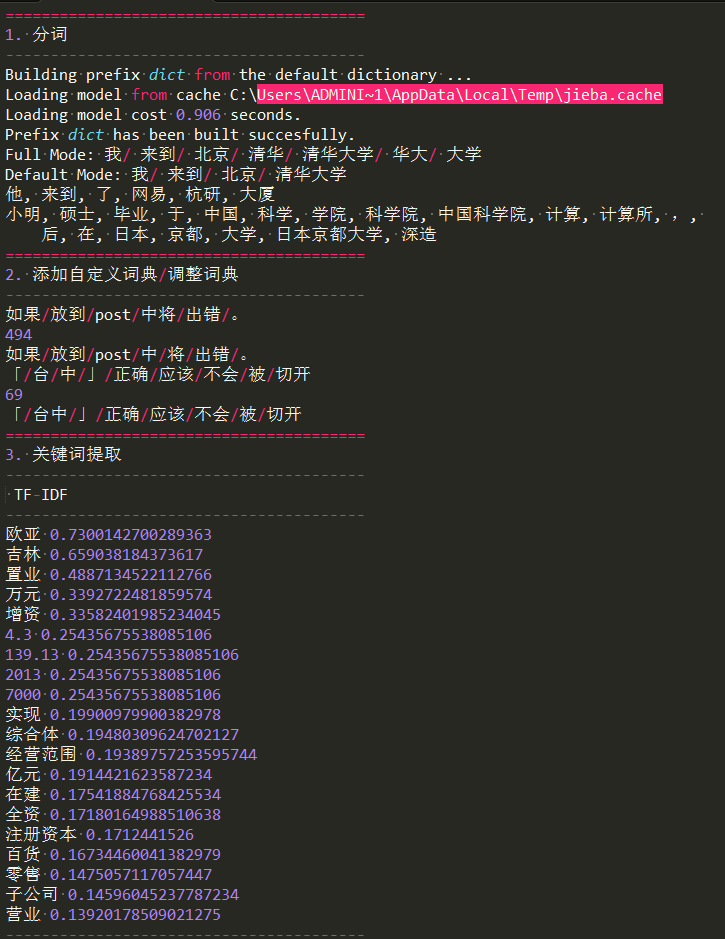
print('1. 分词')
print('-'*40) seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式 seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list)) print('='*40)
print('2. 添加自定义词典/调整词典')
print('-'*40) print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开 print('='*40)
print('3. 关键词提取')
print('-'*40)
print(' TF-IDF')
print('-'*40) s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w)) print('-'*40)
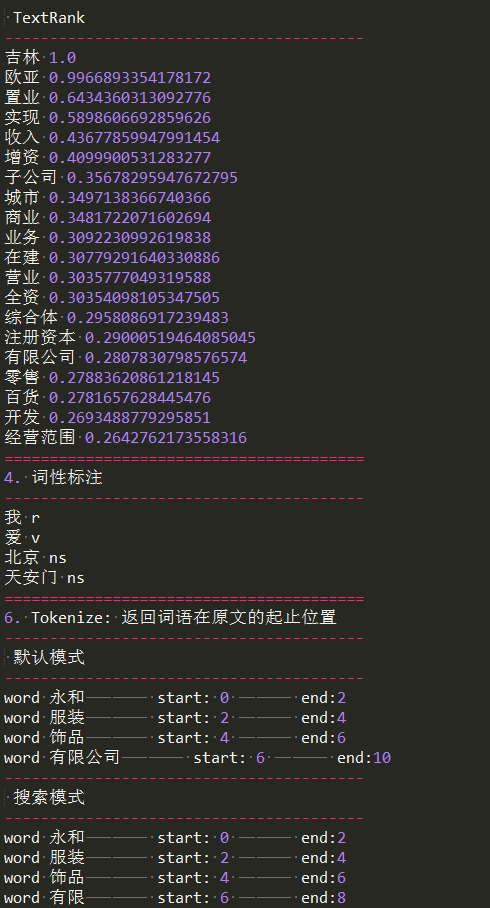
print(' TextRank')
print('-'*40) for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w)) print('='*40)
print('4. 词性标注')
print('-'*40) words = jieba.posseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag)) print('='*40)
print('6. Tokenize: 返回词语在原文的起止位置')
print('-'*40)
print(' 默认模式')
print('-'*40) result = jieba.tokenize('永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2])) print('-'*40)
print(' 搜索模式')
print('-'*40) result = jieba.tokenize('永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
结巴分词的运行结果
Python中结巴分词使用手记的更多相关文章
- python调用hanlp分词包手记
python调用hanlp分词包手记 Hanlp作为一款重要的分词工具,本月初的时候看到大快搜索发布了hanlp的1.7版本,新增了文本聚类.流水线分词等功能.关于hanlp1.7版本的新功能,后 ...
- 结巴分词和自然语言处理HanLP处理手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- Python中调用自然语言处理工具HanLP手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- Python中文语料批量预处理手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- Python 结巴分词(1)分词
利用结巴分词来进行词频的统计,并输出到文件中. 结巴分词github地址:结巴分词 结巴分词的特点: 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
随机推荐
- 步步为营-70-asp.net简单练习(文件的上传和下载)
大文件的上传一般通过FTP协议,而一般小的文件可以通过http协议来完成 1 通过asp.net 完成图片的上传 1.1 创建html页面 注意:1 method="post" ; ...
- POJ 1017 Packets【贪心】
POJ 1017 题意: 一个工厂制造的产品形状都是长方体,它们的高度都是h,长和宽都相等,一共有六个型号,他们的长宽分别为 1*1, 2*2, 3*3, 4*4, 5*5, 6*6. 这些产品通常 ...
- POJ 1328 Radar Installation【贪心】
POJ 1328 题意: 将一条海岸线看成X轴,X轴上面是大海,海上有若干岛屿,给出雷达的覆盖半径和岛屿的位置,要求在海岸线上建雷达,在雷达能够覆盖全部岛屿情况下,求雷达的最少使用量. 分析: 贪心法 ...
- BZOJ1192 [HNOI2006]鬼谷子的钱袋 数学推理
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1192 题意概括 把一个数m拆成很多数字. 问至少拆成多少个数字,1~m中的所有数字才可以用这些数字 ...
- Unity 脚本中的主要函数的 执行顺序及其介绍
Awake ->OnEable-> Start -> FixedUpdate-> Update -> LateUpdate ->OnGUI ->OnDisa ...
- python实现用户登陆(sqlite数据库存储用户信息)
python实现用户登陆(sqlite数据库存储用户信息) 目录 创建数据库 数据库管理 简单登陆 有些地方还未完善. 创建数据库 import sqlite3 #建一个数据库 def create_ ...
- docker 搭建nginx
docker pull nginx 先用docker 去把镜像拉下来 $ docker run --name tmp-nginx-container -d nginx $ docker cp tmp- ...
- jupyter notebook connecting to kernel problem
前几天帮同学配置 python 和 anaconda 环境,在装 jupyter notebook 时,出了点问题,搞了一天半终于搞好了,也是在 github 里找到了这个问题的解答. 当时显示的是无 ...
- 不一样的go语言-不同的OO
前言 go语言因为产生时代的原因,大神们在设计go时,不得不考虑业界的流行趋势(编程理念),使得go既可以面向过程编程,也可以面向对象编程.这里不探讨两者的优劣,存在即是合理,面向过程编程经久不衰 ...
- Spring MVC 注解 @RequestParam解析
在Spring MVC 后台控制层获取参数的方式主要有两种,一种是requset.getParameter(“name”),另一种是用注解@Resquest.Param直接获取. 一.基本使用获取提交 ...