MapReduce中的分区方法Partitioner
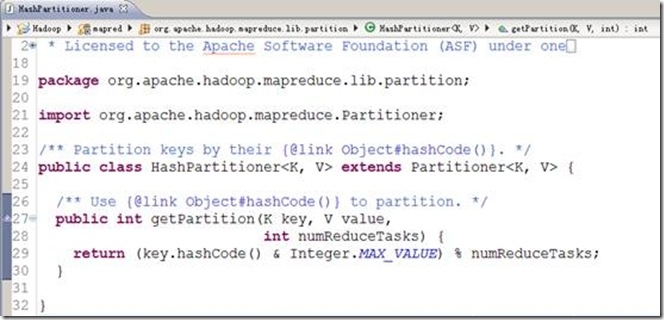
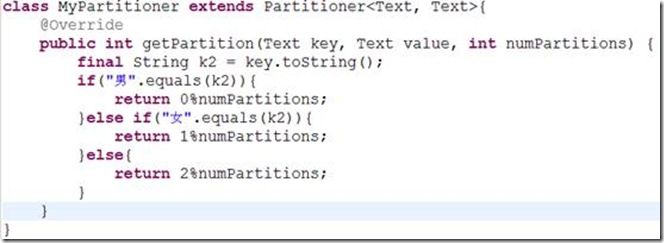
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。

MapReduce中的分区方法Partitioner的更多相关文章
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce中combine、partition、shuffle的作用是什么
http://www.aboutyun.com/thread-8927-1-1.html Mapreduce在hadoop中是一个比較难以的概念.以下须要用心看,然后自己就能总结出来了. 概括: co ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Mapreduce中的字符串编码
Mapreduce中的字符串编码 $$$ Shuffle的执行过程,需要经过多次比较排序.如果对每一个数据的比较都需要先反序列化,对性能影响极大. RawComparator的作用就不言而喻,能够直接 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
- Hadoop案例(七)MapReduce中多表合并
MapReduce中多表合并案例 一.案例需求 订单数据表t_order: id pid amount 1001 01 1 1002 02 2 1003 03 3 订单数据order.txt 商品信息 ...
随机推荐
- ionic 接触的第一个Hybrid项目
最近需要维护一个Hybird项目,使用的是ionic,由于是第一个Hybrid项目,在这里记录下基本的知识. 先看一下ionic的最基本介绍: http://my.oschina.net/u/2275 ...
- ffmpeg-20160617-git-bin.7z ffmpeg-20160626-git-bin.7z
ESC 退出 0 进度条开关 1 屏幕原始大小 2 屏幕1/2大小 3 屏幕1/3大小 4 屏幕1/4大小 S 下一帧 [ -2秒 ] +2秒 ; -1秒 ' +1秒 下一个帧 -> -5秒 f ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- 未将对象引用设置到对象的实例 启用 JIT 调试后,任何无法处理的异常
严谨!!!! DataSet ds = salarySum.GetDataSalarySum2(libUser.SelectedValue, dtpMonth.Value.Date); ...
- mysql探究之null与not null
相信很多用了mysql很久的人,对这两个字段属性的概念还不是很清楚,一般会有以下疑问: 1.我字段类型是not null,为什么我可以插入空值 2.为毛not null的效率比null高 3.判断字段 ...
- Hibernate双向多对多对象关系模型映射
1 双向many-to-many 业务模型: 描述员工和项目 一个员工同时可以参与多个项目 一个项目中可以包含多个员工 分析:数据库的数据模型,通过中间关系表,建立两个one-to-many构成man ...
- iOS进阶面试题----Block部分
1 什么是block 对于闭包 (block),有很多定义,其中闭包就是能够读取其它函数内部变量的函数,这个定义即接近本质又较好理解.对于刚接触Block的同学,会觉得有些绕, 因为我们习惯写这样的程 ...
- [Android Pro] Test win
http://www.cnblogs.com/mayingbao/ http://www.cnblogs.com/hyddd/
- 模拟赛1030d1
[问题描述]从1− ?中找一些数乘起来使得答案是一个完全平方数,求这个完全平方数最大可能是多少.[输入格式]第一行一个数字?.[输出格式]一行一个整数代表答案对100000007取模之后的答案.[样例 ...
- ASP.NET SignalR 与 LayIM2.0 配合轻松实现Web聊天室(三) 之 实现单聊,群聊,发送图片,文件。
上篇讲解了如何搭建聊天服务器,以及客户端js怎么和layui的语法配合.服务器已经连接上了,那么聊天还会远吗? 进入正题,正如上一篇提到的我们用 Client.Group(groupId)的方法向客户 ...