MapReduce中的分区方法Partitioner
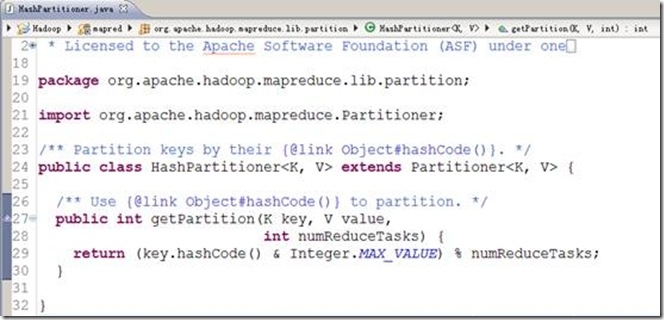
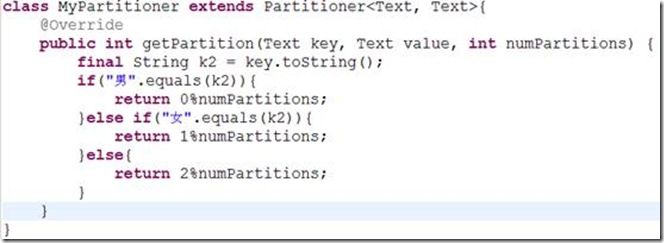
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。

MapReduce中的分区方法Partitioner的更多相关文章
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce中combine、partition、shuffle的作用是什么
http://www.aboutyun.com/thread-8927-1-1.html Mapreduce在hadoop中是一个比較难以的概念.以下须要用心看,然后自己就能总结出来了. 概括: co ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Mapreduce中的字符串编码
Mapreduce中的字符串编码 $$$ Shuffle的执行过程,需要经过多次比较排序.如果对每一个数据的比较都需要先反序列化,对性能影响极大. RawComparator的作用就不言而喻,能够直接 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
- Hadoop案例(七)MapReduce中多表合并
MapReduce中多表合并案例 一.案例需求 订单数据表t_order: id pid amount 1001 01 1 1002 02 2 1003 03 3 订单数据order.txt 商品信息 ...
随机推荐
- ios 关于使用异步网络请求时block回调的内存注意
在一个controller中,使用 NSURLSessionDataTask *dataTask = [[NSURLSession sharedSession] dataTaskWithRequest ...
- nginx服务器设置url的优雅链接
对于LNMP这样架构的网站来说,一般都是基于php框架开发,php框架一般都会讲究优雅链接,比如Laravel,CodeIgniter,ThinkPHP等都是支持这种链接模式的,在服务器配置上也叫作u ...
- Effective C++ -----条款43:学习处理模板化基类内的名称
可在derived class templates内通过“this->“指涉base class templates内的成员名称,或藉由一个明白写出的”base class资格修饰符”完成.
- cmd导入oracle数据
ctrl+r 输入imp
- CSS3 -web-box-shadow实现阴影效果
-webkit-box-shadow:2px -2px 10px #06c; 给元素添加阴影效果 text-shadow 是给文本添加阴影效果属性同上 形成的阴影跟阴影本体大小一致,四个属性分别代表 ...
- 【C语言】结构体
不能定义 struct Node { struct Node a; int b; } 这样的结构,因为为了建立Node 需要 建立一个新的Node a, 可为了建立Node a, 还需要再建立Node ...
- POJ 1681 Painter's Problem (高斯消元)
题目链接 题意:有一面墙每个格子有黄白两种颜色,刷墙每次刷一格会将上下左右中五个格子变色,求最少的刷方法使得所有的格子都变成yellow. 题解:通过打表我们可以得知4*4的一共有4个自由变元,那么我 ...
- Jquery选中行实现行中的Checkbox的选中与取消选中
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs& ...
- Android笔记:管理所有活动
以关闭所有活动为例 public class ActivityCollector { public static List<Activity> activities = new Array ...
- 解决eclipse ctrl+鼠标左键不能用
选择[Window]菜单 Preferences ——>General——>Editors——>Text Editors——>Hyperlinking 把勾都点上,然后确定KE ...