【算法】BM算法
一. 字符串比较的分析
如果要判定长度为\(n\)两个字符串相等,比较中要进行\(n\)比较,但是如果要判定两个字符串不相等,只需要找出一个不相等的位置,因此可以得到如下结论:
结论1:判定字符串相等和判定字符串不相等的代价不同,判定不相等的代价更小
在KMP算法中,每发生一次失配时,算法总是尝试根据已经获得的匹配成功的信息来确定一个新的对齐位置,也即KMP算法是在尝试判断两个字符串相等,根据结论1,这种做法的代价要大于判定字符串不相等的代价。因此BM算法是尝试判定两个字符串不相等。
如果局部匹配成功,对于文本串\(P\)和局部的模式串\(partT\),我们有如下结论:
结论2:
\]
因此文本串\(P\)和局部的模式串\(partT\)对应位置字符相等是匹配成功的一个必要条件,根据这个必要条件我们可以得到BM算法的朴素思想。
二.BM算法的思想
以下面插图为例:
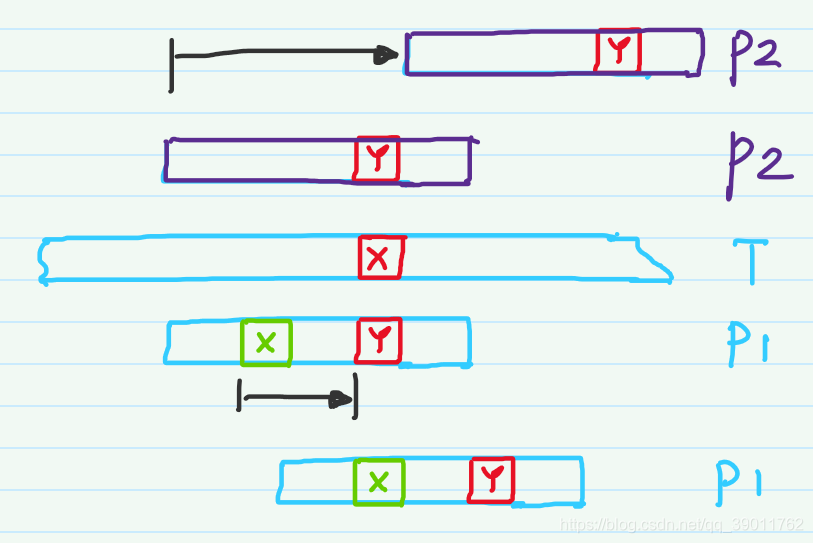
文本串\(T\)和模式串\(P_1\)进行匹配时,文本串中的字符X和模式串中的字符Y失配,此时需要重新选定匹配位置。观察模式串发现,在字符Y的前面,存在一个字符X,此时可以将绿色的X和红色的X对齐,然后再从头开始对比。
当模式串为\(P_2\)时,失配之后发现在字符Y的前面没有字符X,这说明了无论这部分进行怎样的局部匹配,最终都不可能匹配成功。因此可以直接跨过文本串字符X以前的位置。
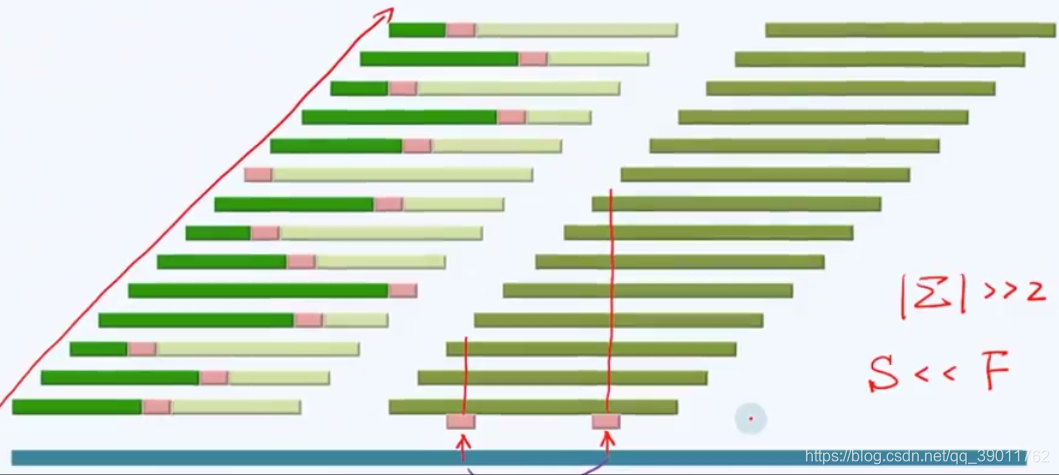
为了在一次失配出现时能够排除更多的对齐位置,我们考虑不同失配位置的信息量的大小。从下面的插图可以得到结论:
结论3:失配的位置越靠后,能够排除的对齐位置越多
因此BM算法不同于KMP算法,它的每次比对是逆向进行的。
三.算法实现
只要我们记录下每个字符在模式串中的位置,当匹配失败时,找到一个新的位置进行比对即可,为此我们构造一个bc[ ]数组。
考虑两种边界情况:
- 模式串中的字符Y前面不存在字符X;
- 模式串中最右边的字符X在Y的后面;
第一种情况我们只需要令\(bc['X'] = -1\)即可,也就是使用通配哨兵。
第二种情况如果不特殊处理,会使模式串往回移动,出现该种情况使,我们只需要令模式串前进一个单位即可。
算法分为两个部分:构造bc[ ]数组和串匹配。
//构造bc[]
int *buildBc(const string &s){
int *bc = new int [256];//一定要分配空间!!!
for(int i = 0; i < 256; ++i)bc[i] = -1;
for(int i = 0; i < s.size(); ++i)bc[s[i]] = i;
return bc;
}
//串匹配
int bc(const string &s1, const string &s2){
int *bc = buildBc(s2);
int n = s1.size(), m = s2.size();
int i = 0, j = 0;
while(i + m < n){
for(j = m - 1; j >= 0; --j){
if(s1[i + j] != s2[j])break;
}
if(j < 0)break;
int d = max(1, j - bc[s1[i + j]]);
i += d;
}
return i;
}
【算法】BM算法的更多相关文章
- Berlekamp_Massey 算法 (BM算法) 学习笔记
原文链接www.cnblogs.com/zhouzhendong/p/Berlekamp-Massey.html 前言 BM算法用于求解常系数线性递推式. 它可以在 $O(n^2)$ 的时间复杂度内解 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- hrbustoj 1551:基础数据结构——字符串2 病毒II(字符串匹配,BM算法练习)
基础数据结构——字符串2 病毒IITime Limit: 1000 MS Memory Limit: 10240 KTotal Submit: 284(138 users) Total Accepte ...
- BM算法详解
http://www-igm.univ-mlv.fr/~lecroq/string/node14.html http://www.cs.utexas.edu/users/moore/publicati ...
- Boyer-Moore(BM)算法,文本查找,字符串匹配问题
KMP算法的时间复杂度是O(m + n),而Boyer-Moore算法的时间复杂度是O(n/m).文本查找中“ctrl + f”一般就是采用的BM算法. Boyer-Moore算法的关键点: 从右遍历 ...
- BM算法
BM算法 用来求解一个数列的递推式. 即给定\(\{x_i\}\)求解一个\(\{a_i\}\),满足\(|a|=m,x_n=\sum_{i=1}^ma_i*x_{n-i}\). 考虑增量法构造. 假 ...
- 数据结构 BM算法
BM算法是比KMP算法更快的字符串模式匹配算法.BM算法最好情况下的时间复杂度是O(n),KMP算法最好情况下的时间复杂度是O(n+m),两者最坏情况下的时间复杂度均是O(m*n).其中,n指目标串长 ...
- BM算法--串匹配
BM(Boyer-Moore)算法,后缀匹配,是指模式串的比较从右到左,模式串的移动也是从左到右的匹配过程,一般情况比KMP算法要快.时间复杂度O(m/n) C++描述(教师版) int BM(cha ...
- BoyerMoore(BM)算法--C#
因项目需要使用字符串查询算法,在网上搜搜了半天,没有找到C#版的. 索性根据BM机制,用C#实现了一遍.现在贴出了,以备忘记. /// <summary> /// BM算法 /// < ...
随机推荐
- dis集群研究和实践(基于redis 3.0.5) 《转载》
https://www.cnblogs.com/wxd0108/p/5798498.html 前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的 ...
- WebApi的好处和MVC的区别
1.WebApiwebapi有自己的路由. webservice和wcf的协议都是soap协议,数据的序列化和反序列化都是soap的格式.而webapi是Json的数据传递 webapi的优点有哪些? ...
- springboot vue简单整合
1.vue项目 (1)修改config/index.js (2)执行 npm run build 生成静态文件,在dist目录 2.springboot项目 (1)在src/main/resource ...
- DLC 数制与数制的转换
进位计数值:用进位的方法进行计数 常用数值有十进制.二进制.八进制.十六进制等. 进位计数制把包括基数与权两个基本问题.
- 【HDFS API编程】查看文件块信息
现在我们把文件都存在HDFS文件系统之上,现在有一个jdk.zip文件存储在上面,我们想知道这个文件在哪些节点之上?切成了几个块?每个块的大小是怎么样?先上测试类代码: /** * 查看文件块信息 * ...
- 【HP-UNIX】修改HP-UNIX主机名称
原文链接:https://blog.csdn.net/lantianbaiyunbj/article/details/53434537 HP-UX修改主机IP地址 方法一 1.set_parms ho ...
- 解决uni-app props 传递数组修改后不能使用问题
1.子组件页面结构 //NoticesMarquee 组件 <view v-for="(item, index) in tempList" :key="index& ...
- LeetCode 105. Construct Binary Tree from Preorder and Inorder Traversal 由前序和中序遍历建立二叉树 C++
Given preorder and inorder traversal of a tree, construct the binary tree. Note:You may assume that ...
- (12)SecureCRT中文乱码问题
Options -- Session Options -- Appearance --Character encoding:选择UTF-8
- [C#]打包项目[转]
原文:https://www.cnblogs.com/danyu/p/7243706.html 加入自定义操作:https://blog.csdn.net/ristal/article/details ...