清北学堂(2019 4 28 ) part 2
主要内容数据结构:
1.二叉搜索树
一棵二叉树,对于包括根节点在内的节点,所有该节点左儿子比此节点小,所有该节点右儿子比该节点大,(感觉好像二分...)
每个节点包含一个指向父亲的指针,和两个指向儿子的指针。如果没有则为空。每个节点还包含一个key值,代表他本身这个点的权值 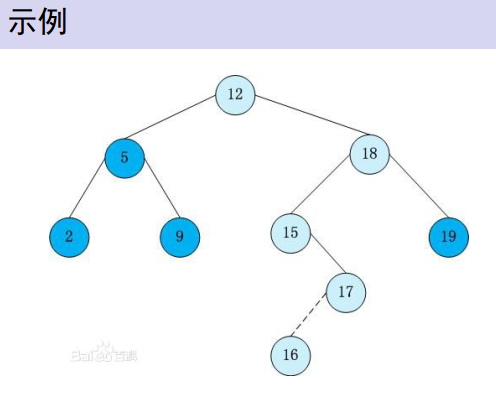
常用操作:
插入一个数,删除一个数,询问最大/最小值,询问第k大值。
插入操作:
现在我们要插入一个权值为x的节点。
为了方便,我们插入的方式要能不改变之前整棵树的形态。
首先找到根,比较一下key[root]和x,如果key[root] < x,节点应该插在root右侧,否则再左侧。看看root有没有右儿子,如果没有,那么直接把root的右儿子赋成x就完事了。
否则,为了不改变树的形态,我们要去右儿子所在的子树里继续这一操作,直到可以插入为止。
删除操作:
要删掉一个权值,首先要知道这个点在哪。
从root开始,像是插入一样找权值为x的点在哪。
定义x的后继y,是x右子树中所有点里,权值最小的点。
找这个点可以x先走一次右儿子,再不停走左儿子。
如果y是x的右儿子,那么直接把y的左儿子赋成原来x的左儿子,然后用y代替x的位置。
找第k大的数:
对每个节点在多记一个size[x]表示x这个节点子树里节点的个数。
从根开始,如果右子树的size ≥ k,就说明第k大值在右侧,往右边走。
如果右子树size + 1 = k,那么说明当前这个点就是第k大值。
否则,把k减去右子树size + 1,然后递归到左子树继续操作。
那么为什么呢?
证明:
由二叉搜索树性质可得,左边字数一定比其父节点小,右边则反之
看看正在处理的点的右子树根节点,对于其“size”,即节点个数,如果大于k,说明要找的树(或地址)肯定在右边
因为左边的恒比右边小,如果此时size>=k,说明右面至少还有k个没找过的数,我们要找的是第k大的数,并不能允许右边有多于k个比目标大的数,那么向右找
当找到当前节点的右子树根节点size+1=k时,说明这个数底下(包括自身)有k-1个比当前处理节点大的数,那么当前处理节点就是第k大的
如果没等找到size+1=k就size<k了怎么办?
说明右边比当前处理节点大的数并不足k,此时应向左找,找比当前节点小的数,也许时不时地向右子树找一下,最终找到第k大的数
(我因为仔细读问题,没看见第k“大”的数...当第k个(小)的数证的,百思不得其解...)
2.二叉堆
一只神仙提前讲过,我之前也整过,然而用的优先队列,因为对就是棵完全二叉树,(看题目,“二叉”堆吖~)
一直没有手写堆,今天试试。
代码:
#include<bits/stdc++.h> //本代码致力于维护小根堆
using namespace std;
int a[100005];
int n;
int size;
inline void up(int t){ //把数据上浮
while(a[t]<a[t>>1]&&t){
swap(a[t],a[t>>1]);
t>>=1;
}
}
inline void down(int t){ //下沉
while((t<<1)<=size){
int l=t*2;
int r=t*2+1;
if(r>size){ //对于某些奇怪的只有左儿子的树的特判
if(a[t]>a[l]){
swap(a[t],a[l]);
t=l;
}
break;
}
if(a[t]<=a[l]&&a[t]<=a[r])break;
else if(a[l]<a[r]){ //判断把哪个儿子拿上来当爹
swap(a[t],a[l]);
t=l;
}
else{
swap(a[t],a[r]);
t=r;
}
}
}
inline void pop(){ //弹出堆顶
swap(a[1],a[size]);
size--;
down(1);
}
inline void add(int now){ //添加新元素
a[++size]=now;
up(size);
}
int main(){
scanf("%d",&n);
while(n){
n--;
int x;
scanf("%d",&x);
add(x);
}
while(size){
printf("%d ",a[1]);
pop();
}
return 0;
}
p.s.我为了确保这玩意对,特意又交了一遍快排模板
(我写这玩意用了一晚上(并不怕笑话...),老师说下课时我差点脏话出口...我发誓这种情况不多见)
3.区间RMQ问题
举个例子(例题):
给出一个序列,每次询问区间最大值.
看上去暴力模拟能过吖...
然而
N ≤ 100000, Q ≤ 1000000.
所以我们需要一套好算法,比如这个RMBRMQ,
主要思路是将总区间不断二分,根据这些区间进行计算,如图:
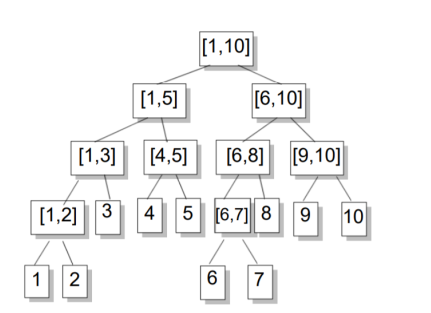
然后将所需访问区间拆分,但能保留的尽量大的区间一定要保留,因为大区间问问可以表示成许多小区间,只算大区间显然更快
延迟更新:
信息更新时,未必要真的做彻底的更新,可以只是将应该如何更新记录下来,等到真正需要查询准确信息时,才去更新 足以应付查询的部分。
在区间增加时,如果要加的区间正好覆盖一个节点,则增加其节 点的inc值和sum值,不再往下走.在区间询问时,还是采取正常的区间分解.
在上述两种操作中,如果我们到了区间[L, R]还要接着往下走,并且inc非0,说明子区间的信息是不对的,我们将inc传送到左儿子和右儿子上,并将inc赋成0,即完成了一次更新.
延迟更新可避免每次都赋值的麻烦情况,可极大省时
4.并查集
等我做出来村村通再整...
先整下按秩合并:
对每个顶点,再多记录一个当前整个结构中最深的点到根的深度deepx.
注意到两个顶点合并时,如果把比较浅的点接到比较深的节点上.
如果两个点深度不同,那么新的深度是原来较深的一个.
只有当两个点深度相同时,新的深度是原来的深度+1.
注意到一个深度为x的顶点下面至少有2x个点,所以x至多为log N.
那么在暴力向上走的时候,要访问的节点至多只有log个 。
然而路径压缩更好...虽有两种算法一起用的sao操作,但为了避免一种“玄学错误”(???)而并不这么用(起码用的肥肠少...)
5.树及LCA问题
在一棵有根树中,树上两点x, y的LCA指的是x, y向根方向遇到到第一个相同的点.
我们记每一个点到根的距离为deepx.
注意到x, y之间的路径长度就是deepx + deepy - 2 * deepLCA
两个点到根路径一定是前面一段不一样,(汇合)后面都一样.
注意到LCA的深度一定比x, y都要小.
利用deep,把比较深的点往父亲跳一格,直到x, y跳到同一个点上.
这样做复杂度是O(len).
首先不妨假设deepx < deepy.
为了后续处理起来方便,我们先把x跳到和y一样深度的地方.
如果x和y已经相同了,就直接退出.
否则,由于x和y到LCA的距离相同,倒着枚举步长,如果x, y的第2j个父亲不同,就跳上去.这样,最后两个点都会跳到离LCA距离为1的地方,在跳一步就行了.
时间复杂度O(N log N).
我..累了(QAQ)
清北学堂(2019 4 28 ) part 2的更多相关文章
- 清北学堂2019.8.10 & 清北学堂2019.8.11 & 清北学堂2019.8.12
Day 5 杨思祺(YOUSIKI) 今天的难度逐渐上升,我也没做什么笔记 开始口胡正解 今天的主要内容是最小生成树,树上倍增和树链剖分 最小生成树 Prim 将所有点分为两个集合,已经和点 1 连通 ...
- 清北学堂2019.7.18 & 清北学堂2019.7.19
Day 6 钟皓曦 经典题目:石子合并 可以合并任意两堆,代价为数量的异或(^)和 f[s]把s的二进制所对应石子合并成一堆所花代价 枚举s的子集 #include<iostream> u ...
- 清北学堂2017NOIP冬令营入学测试P4745 B’s problem(b)
清北学堂2017NOIP冬令营入学测试 P4745 B's problem(b) 时间: 1000ms / 空间: 655360KiB / Java类名: Main 背景 冬令营入学测试 描述 题目描 ...
- 清北学堂2017NOIP冬令营入学测试 P4744 A’s problem(a)
清北学堂2017NOIP冬令营入学测试 P4744 A's problem(a) 时间: 1000ms / 空间: 655360KiB / Java类名: Main 背景 冬令营入学测试题,每三天结算 ...
- 济南清北学堂游记 Day 1.
快住手!这根本不是暴力! 刷了一整天的题就是了..上午三道题的画风还算挺正常,估计是第一天,给点水题做做算了.. rqy大佬AK了上午的比赛! 当时我t2暴力写挂,还以为需要用啥奇怪的算法,后来发现, ...
- 清明培训 清北学堂 DAY1
今天是李昊老师的讲授~~ 总结了一下今天的内容: 1.高精度算法 (1) 高精度加法 思路:模拟竖式运算 注意:进位 优化:压位 程序代码: #include<iostream>#in ...
- 7月清北学堂培训 Day 3
今天是丁明朔老师的讲授~ 数据结构 绪论 下面是天天见的: 栈,队列: 堆: 并查集: 树状数组: 线段树: 平衡树: 下面是不常见的: 主席树: 树链剖分: 树套树: 下面是清北学堂课程表里的: S ...
- 清北学堂(2019 4 28 ) part 1
今天主要用来铺路,打基础 枚举 没什么具体算法讲究,但要考虑更优的暴力枚举方法,例如回文质数,有以下几种思路: 1.挨个枚举自然数,再一起判断是否是回文数和质数,然而一看就不是最优 2.先枚举质数再判 ...
- <知识整理>2019清北学堂提高储备D2
简单数据结构: 一.二叉搜索树 1.前置技能: n/1+n/2+……+n/n=O(n log n) (本天复杂度常涉及) 2.入门题引入: N<=100000. 这里多了一个删除的操作,因此要 ...
随机推荐
- Long类型参数传到前端精度丢失的解决方案
由于公司数据库表的id是利用雪花算法生成的,所以实体类里面定义的数据类型为Long.但是这个数据传到前端时,发生了精度丢失的现象.本文记录了从java后端的角度如何解决这个精度丢失的问题,便于 ...
- kafka模型理解
1.消息发送至一个topic,而这个topic可以由多个partition组成,每条消息在partition中的位置称为offset 2.消息存在有效期,如果设置为2天,则消息2天后会被删除 3.每个 ...
- .NetCore SignalR 踩坑记
背景 由于最近公司要做微信小程序聊天,所以.NetFramwork版本的SignalR版本的不能用了.因为小程序里没有windows对象,导致JQuery无法使用.而Signalr的 js客户端是依赖 ...
- Jmeter(三十八)while控制器实现ssh三次重连
在jmeter中,可以使用SSH协议连接主机进行相关操作, 步骤如下 首先添加一个ssh command 我们的测试交流群:317765580 在command中填写远程连接的必要信息 结果树中可以 ...
- 第八次oo作业
作业五 作业五是当前最后一次电梯作业,也是我们第一次接触到多线程编程,输入方式也由之前的一次性输入变为了实时输入,其中涉及到大量的同步和冲突,其中学习多线程的使用也花了大量的时间,但总的来说为以后的作 ...
- VirtualBox安装复制Centos6.6配置网络
由于要搭建mongodb的集群,先用虚拟机做下相关实验,以前都用VM Vare,但是现在这个电脑的配置不是太好,VM Vare比较耗资源,所以选择VirtualBox. 1.下载VirtualBox和 ...
- Python_每日习题_0006_斐波那契数列
程序设计: 斐波那契数列(Fibonacci sequence),从1,1开始,后面的每一项等于前面两项之和. 图方便就递归实现,图性能就用循环. # for 循环 target = int(inpu ...
- UVA - 12169 -扩展欧几里得算法
#include<iostream> #include<string.h> #include<algorithm> #include<stdio.h> ...
- CPU-bound(计算密集型) 和I/O bound(I/O密集型)
概念 概念I/O系统,英文全称为“Input output system”,中文全称为“输入输出系统”,由输入输出控制系统和外围设备两部分组成,是计算机系统的重要组成部分.在计算机系统中,通常把处理器 ...
- Day1 初步认识Python
天气有点阴晴不定~ (截图来自----------金角大王) 1.学习了计算机概论(CPU/Memory/Disk,memory的存在是为了解决信息传输产生的时延) CPU:精简指令集(RISC)-- ...