Python深度学习案例1--电影评论分类(二分类问题)
我觉得把课本上的案例先自己抄一遍,然后将书看一遍。最后再写一篇博客记录自己所学过程的感悟。虽然与课本有很多相似之处。但自己写一遍感悟会更深
电影评论分类(二分类问题)
本节使用的是IMDB数据集,使用Jupyter作为编译器。这是我刚开始使用Jupyter,不得不说它的自动补全真的不咋地(以前一直用pyCharm)但是看在能够分块运行代码的份上,忍了。用pyCharm敲代码确实很爽,但是调试不好调试(可能我没怎么用心学),而且如果你完全不懂代码含义的话,就算你运行成功也不知道其中的含义,代码有点白敲的感觉,如果中途出现错误,有的时候很不好找。但是Jupyter就好一点,你可以使用多个cell,建议如果不打印一些东西,cell还是少一点,不然联想功能特别弱,敲代码特别难受。
1. 加载IMDB数据集
仅保留前10000个最常出现的单词,低频单词被舍弃
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
train_data[0]
train_labels[0]
max([max(sequence) for sequence in train_data])
下面这段代码:将某条评论迅速解码为英文单词
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
2. 将整数序列编码为二进制矩阵
# 对列表进行one-hot编码,将其转换为0和1组成的向量
def vectorize_sequences(sequences, dimension=10000):
# 创建一个形状为(len(sequences), dimension)的零矩阵
# 序列[3, 5]将会被转换成10000维向量,只有索引3和5的元素为1,其余为0
results = np.zeros((len(sequences), dimension)) # 将results[i]指定索引设为1
for i, sequence in enumerate(sequences):
results[i, sequence] = 1
return results
# 将训练数据向量化
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
x_train[0]
标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
3. 模型定义
from keras import models
from keras import layers model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
4. 编译模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
5. 配置优化器
from keras import optimizers model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])
6. 使用自定义的损失和指标
from keras import losses
from keras import metrics model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=losses.binary_crossentropy, metrics=[metrics.binary_crossentropy])
7. 留出验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:] y_val = y_train[:10000]
partial_y_train = y_train[10000:]
8. 训练模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val)) history_dict = history.history
history_dict.keys()
9. 绘制训练损失和验证损失
import matplotlib.pyplot as plt history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss'] epochs = range(1, len(loss_values) + 1) plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend() plt.show()
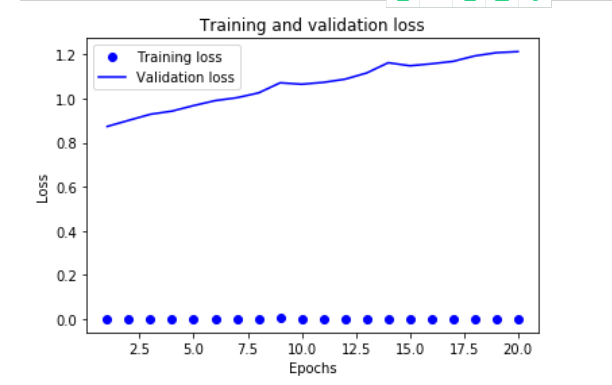
损失降得太狠了,训练的损失和精度不太重要,反应训练集的训练程度。重点是验证精度
10. 绘制训练精度和验证精度
plt.clf() # 清除图像
acc = history_dict['acc']
val_acc = history_dict['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend() plt.show()
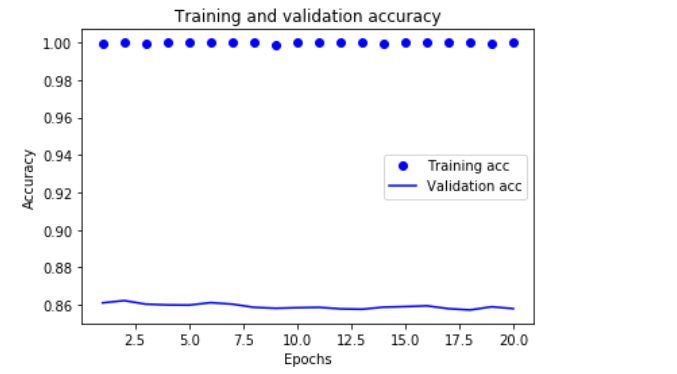
可以看到验证的精度并不高,只有86%左右。而训练的精度达到几乎100%,两者精度相差太大,出现了过拟合。为了防止过拟合,可以在3轮之后停止训练。还有很多方法降低过拟合。我们一般看验证精度曲线就是找最高点对应的轮次,然后从头开始训练一个新的模型
11. 从头开始训练一个模型
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
最终结果如下:
results [0.28940243008613586, 0.88488] 得到了88%的精度,还有待优化的空间
12. 使用训练好的模型在新数据上生成预测结果
model.predict(x_test)
array([[0.20151292],
[0.9997969 ],
[0.9158534 ],
...,
[0.1382984 ],
[0.0817486 ],
[0.69964325]], dtype=float32)
可见。网络对某些样本的结果是非常确信(大于等于0.99),但对其他结果却不怎么确信
13. 总结
1. 加载数据集->对数据集进行预处理->模型定义->编译模型->配置优化器->使用自定义的损失和指标->留出验证集->训练模型->绘制图像
2. 对于二分类问题,网络的最后一层应该是只有一个单元并使用sigmoid激活Dense层,网络输出应该是0~1范围内的标量,表示概率值
3. 对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy(二元交叉熵)损失函数。
Python深度学习案例1--电影评论分类(二分类问题)的更多相关文章
- 基于Keras的imdb数据集电影评论情感二分类
IMDB数据集下载速度慢,可以在我的repo库中找到下载,下载后放到~/.keras/datasets/目录下,即可正常运行.)中找到下载,下载后放到~/.keras/datasets/目录下,即可正 ...
- Python深度学习案例2--新闻分类(多分类问题)
本节构建一个网络,将路透社新闻划分为46个互斥的主题,也就是46分类 案例2:新闻分类(多分类问题) 1. 加载数据集 from keras.datasets import reuters (trai ...
- 参考分享《Python深度学习》高清中文版pdf+高清英文版pdf+源代码
学习深度学习时,我想<Python深度学习>应该是大多数机器学习爱好者必读的书.书最大的优点是框架性,能提供一个"整体视角",在脑中建立一个完整的地图,知道哪些常用哪些 ...
- 利用python深度学习算法来绘图
可以画画啊!可以画画啊!可以画画啊! 对,有趣的事情需要讲三遍. 事情是这样的,通过python的深度学习算法包去训练计算机模仿世界名画的风格,然后应用到另一幅画中,不多说直接上图! 这个是世界名画& ...
- 好书推荐计划:Keras之父作品《Python 深度学习》
大家好,我禅师的助理兼人工智能排版住手助手条子.可能非常多人都不知道我.由于我真的难得露面一次,天天给禅师做底层工作. wx_fmt=jpeg" alt="640? wx_fmt= ...
- 7大python 深度学习框架的描述及优缺点绍
Theano https://github.com/Theano/Theano 描述: Theano 是一个python库, 允许你定义, 优化并且有效地评估涉及到多维数组的数学表达式. 它与GPUs ...
- 基于python深度学习的apk风险预测脚本
基于python深度学习的apk风险预测脚本 为了有效判断安卓apk有无恶意操作,利用python脚本,通过解包apk文件,对其中xml文件进行特征提取,通过机器学习构建模型,预测位置的apk包是否有 ...
- Python深度学习读书笔记-6.二分类问题
电影评论分类:二分类问题 加载 IMDB 数据集 from keras.datasets import imdb (train_data, train_labels), (test_data, t ...
- Python深度学习 deep learning with Python
内容简介 本书由Keras之父.现任Google人工智能研究员的弗朗索瓦•肖莱(François Chollet)执笔,详尽介绍了用Python和Keras进行深度学习的探索实践,涉及计算机视觉.自然 ...
随机推荐
- android屏蔽系统锁屏的办法
最近在开发一个第三方锁屏,使用中需要屏蔽系统锁屏,故代码如下: 在第三方锁屏的服务中onCreate()方法中(第三方锁屏服务启动时关闭一次系统锁屏服务即可) KeyguardManager mKey ...
- 【ARTS】01_16_左耳听风-20190225~20190303
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- 解决64bit不能连接access的问题
原有的程序迁移至64位,结果调用数据库时出错,原因是jet驱动没有64位的,得换用64位的驱动程序: 1. 下载运行 AccessDatabaseEngine_x64.exe (http://ww ...
- GBT MBR
MBR最大支持2.2TB磁盘,它无法处理大于2.2TB容量的磁盘.MBR还只支持最多4个主分区——如果你想要更多分区,你需要创建所谓“扩展分区”,并在其中创建逻辑分区. GPT的全称是Globally ...
- GetCheckProxy
@echo off setlocal enabledelayedexpansion set infile=free.txt set url=https://www.google.com/?gws_rd ...
- MinGW GCC 7.2.0 2017年8月份出炉啦
GCC720-for-MSYS2.7z for x86 x64 63.72 MB 发布日期: 2017-08-14 下载地址: https://forum.videohelp.com/attachme ...
- (常用)configparser,hashlib,hamc模块
configparser模块 #专门解析my.ini这种形式的文件(cnf) import configparser config=configparser.ConfigParser() conf ...
- OpenStack实践系列⑨云硬盘服务Cinder
OpenStack实践系列⑨云硬盘服务Cinder八.cinder8.1存储的三大分类 块存储:硬盘,磁盘阵列DAS,SAN存储 文件存储:nfs,GluserFS,Ceph(PB级分布式文件系统), ...
- nodejs process.memoryUsage() rss等参数啥含义
1 前言 使用process.memoryUsage() ,然后可以得到一个对象如下: { rss: 4935680, heapTotal: 1826816, heapUsed: 650472, ex ...
- C#生成不重复的N位随机数
直接上代码: #region 生成N位随机数 /// <summary> /// 生成N位随机数 /// </summary> /// <param name=" ...