logistics回归简单应用——梯度下降,梯度上升,牛顿算法(一)
警告:本文为小白入门学习笔记
由于之前写过详细的过程,所以接下来就简单描述,主要写实现中遇到的问题。
数据集是关于80人两门成绩来区分能否入学:
数据集:
假设函数(hypothesis function):
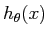 |
 |
 |
|
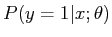 |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2018.9.7补充
近日看了周志华的机器学习书,有对logistics回归(又叫对数几率回归,是一个分类算法)有了新的理解,所以将对其中的数学原理进行描述。
对于二分类问题,最理想的是用单位阶跃函数来表示,例如当x满足条件时,y=1或y=0,但是问题是它不是一个连续函数,所以需要用一个连续函数来替换,于是就用到了对数几率函数来替换
于是就得到上面那样的假设函数。它的返回结果其实是一个概率值,也就是某一个点它属于正样本或负样本的概率是多少,如果是正样本的概率大那就划分到正样本,负样本同理。
对于概率 我们已经知道了训练样本中y和x的值,接下来如何求得参数theta的值。
首先补充一点概率论知识:
引自:https://blog.csdn.net/zengxiantao1994/article/details/72787849
其中:p(w):为先验概率,表示每种类别分布的概率: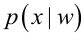
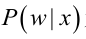
而我们需要求解的是后验问题,即知道某个样本是属于正类或负累,求解它是正类或负类的概率是多少。
对于这个我们该如何求参数theta和b呢?
于是,我们可以通过“”极大似然估计“”来估计theta和b的值。
总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
这里我就不推导公式,有兴趣可以查。求解参数的过程为:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数;
(4)解似然方程。
最终的表达式是

求解这个可以用梯度下降方法或牛顿方法
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
代价函数(cost function):
使用梯度下降算法求解theta:

使用MATLAB实现:
function [jVal] = logCostFunction2(a)
%LOGCOSTFUNCTION2 此处显示有关此函数的摘要
% 此处显示详细说明
g = inline('1.0 ./ (1.0 + exp(-z))');
x = load('ex4x.dat');
y = load('ex4y.dat');
m = length(y);
x = [ones(m, ), x];
theta = zeros(size(x(,:)))'; %3*1
%theta = ones(,);
J = zeros(,); for iter = :
w = zeros(,);
%梯度上升
for i = :m
c = x(i,:); %*
w = w + (g(c * theta) - y(i)) * c';
%w = w + (y(i) - g(c * theta)) * c';
end
%代价函数
f = ;
for j = :m
b = x(j,:);
f = f + (y(j) .* log(g(b * theta)) + ( - y(j)) .* log( - g(b * theta)));
end
%更新theta
theta = theta - (a * w / m);
%theta = theta + (a * w);
jVal = - ./ m .* f;
J(iter) = jVal;
end
disp(theta);
%迭代次数和代价函数值图像
figure();
plot(:,J(:),'r-');hold on;
xlabel('Number of iterations');
ylabel('Cost J');
%决策边界
figure();
x1 = x(:,);
x2 = - (theta() + theta() .* x1)./theta();
pos = find(y == );
neg = find(y == );
plot(x(pos,),x(pos,),'+');hold on;
plot(x(neg,),x(neg,),'o');hold on;
plot(x1(:m),x2,'r');
end
设置不同的learning rate,获得以下曲线:
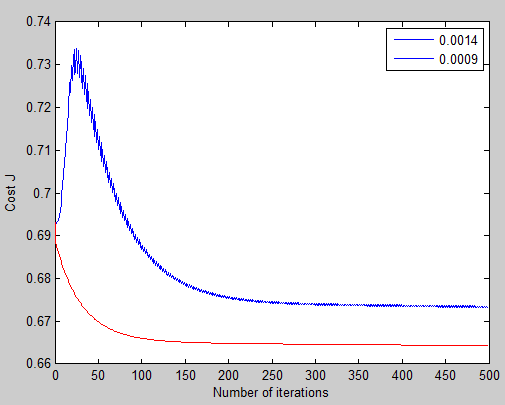
可以看出当alpha = 0.0014时,曲线是蓝色那条,可以看出曲线发生抖动,说明取值过大,其实我一开始就是应为选取alpha过大,导致一直获取抖动的曲线,还有就是迭代次数不够也会获取不到最小值。
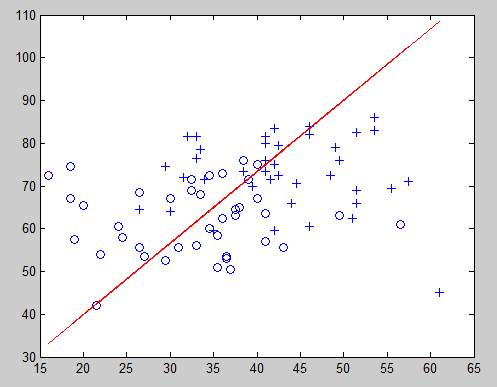
决策边界:
theta0 = -0.0193
theta1 = 0.0474
theta2 = -0.0236
y = theta‘ * x;
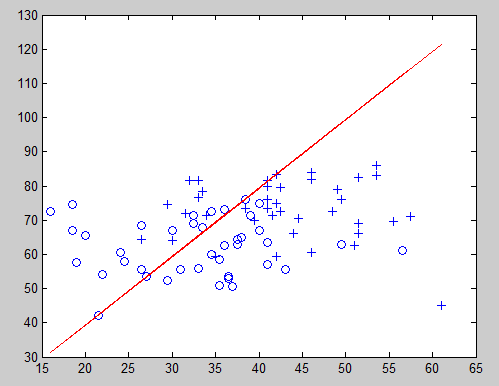
因为我是对照着开头网页上的内容去做的,那个网站上是使用牛顿算法求解,我使用的是梯度下降算法,我发现它们有很大误差,但是看迭代次数和损失函数图像,的确正常下降到最小值,但是误差怎么会这么大?百度了几篇博客学习:
----------------------------------------------------------------------------------------------------------------------------------------------
分界面怎么画呢?问题也就是在x1,x2坐标图中找到那些将x1,x2带入1/(1+exp(-wx))后,使其值>0.5的(x1,x2)坐标形成的区域,因为我们知道1/(1+exp(-wx))>0.5意味着该区域的(x1,x2)表示的成绩允许上大学的概率>0.5,那么其他的区域就是不被允许上大学,那么1/(1+exp(-wx))=0.5解出来的一个关于x1,x2的方程就是那个分界面。我们解出来以后发现,这个方程是一个直线方程:w(2)x1+w(3)x2+w(1)=0 注意我们不能因为这个分界面是直线,就认为logistic回归是一个线性分类器,注意logistic回归不是一个分类器,他没有分类的功能,这个logistic回归是用来预测概率的,这里具有分类功能是因为我们硬性规定了一个分类标准:把>0.5的归为一类,<0.5的归于另一类。这是一个很强的假设,因为本来我们可能预测了一个样本所属某个类别的概率是0.6,这是一个不怎么高的概率,但是我们还是把它预测为这个类别,只因为它>0.5.所以最后可能logistic回归加上这个假设以后形成的分类器
的分界面对样本分类效果不是很好,这不能怪logistic回归,因为logistic回归本质不是用来分类的,而是求的概率。
摘自 : https://www.cnblogs.com/happylion/p/4169945.html
----------------------------------------------------------------------------------------------------------------------------------------------
对此我还有一个问题,我发现同一个问题有的人用梯度上升方法求解,而用梯度下降法也能求解,所以有对梯度上升和梯度下降进行了了解:
这是合并后的代价函数:
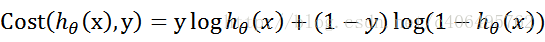
这个代价函数,是对于一个样本而言的。给定一个样本,我们就可以通过这个代价函数求出,样本所属类别的概率,而这个概率越大越好,所以也就是求解这个代价函数的最大值。既然概率出来了,那么最大似然估计也该出场了。
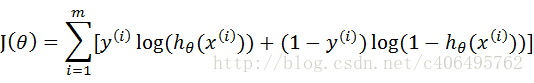
对比上面我使用的代价函数:
会发现区别,他们之间相差一个负号,这样就明白了。
于是我又用梯度上升方法实现一次:
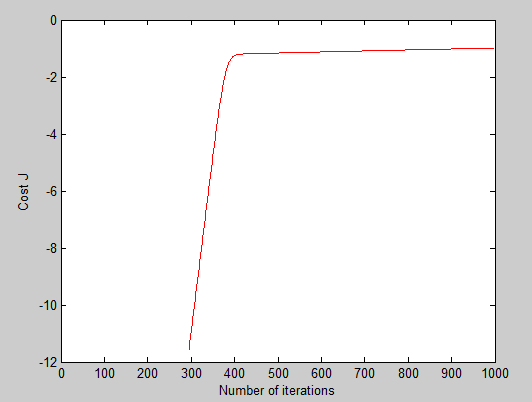
theta:
0.9781
0.2580
-0.1540
虽然alpha的取值,和最后theta值有很大的区别,但是最后的图像差不多一样不精确.
假如一个同学科目1为20 分,科目2为80分
0.21% 这个准确性的确很低
---------------------------------------------------------------------------------------------------------------------------------------------
对此我还是决定用牛顿方法再求解一次:
代价函数(cost Function):
牛顿方法是:
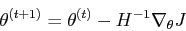

MATLAB实现:
function [ jVal ] = logNewton( )
g = inline('1.0 ./ (1.0 + exp(-z))');
x = load('ex4x.dat');
y = load('ex4y.dat');
m = length(y);
x = [ones(m, ), x];
theta = zeros(size(x(,:)))'; %3*1
%theta = ones(,);
J = zeros(,);
for iter = :
w = zeros(,);
%求偏导
for i = :m
c = x(i,:); %*
w = w + (g(c * theta) - y(i)) * c';
end
%Hessian
f = ;
for j = :m
b = x(j,:);
f = f + (g(b * theta) .* ( - g(b * theta)) * b' * b);
end
%代价函数
l = ;
for j = :m
b = x(j,:);
l = l + (y(j) .* log(g(b * theta)) + ( - y(j)) .* log( - g(b * theta)));
end
%更新theta
theta = theta - ( f\ w); %inv(f)*w
jVal = - ./ m .* l;
J(iter) = jVal;
end
disp(theta);
%迭代次数和代价函数值图像
figure();
plot(:,J(:),'o--');hold on;
xlabel('Number of iterations');
ylabel('Cost J');
%决策边界
figure();
x1 = x(:,);
x2 = - (theta() + theta() .* x1)./theta();
pos = find(y == );
neg = find(y == );
plot(x(pos,),x(pos,),'+');hold on;
plot(x(neg,),x(neg,),'o');hold on;
plot(x1(:m),x2,'r');
end
别人家的代码(只有迭代部分):https://www.cnblogs.com/tornadomeet/archive/2013/03/16/2963919.html
for i = :MAX_ITR
% Calculate the hypothesis function
z = x * theta;
h = g(z);%转换成logistic函数 % Calculate gradient and hessian.
% The formulas below are equivalent to the summation formulas
% given in the lecture videos.
grad = (/m).*x' * (h-y);%梯度的矢量表示法
H = (/m).*x' * diag(h) * diag(1-h) * x;%hessian矩阵的矢量表示法 % Calculate J (for testing convergence)
J(i) =(/m)*sum(-y.*log(h) - (-y).*log(-h));%损失函数的矢量表示法 theta = theta - H\grad;%是这样子的吗?
end
所以说熟练使用矩阵知识可以简单化很多问题。
图像:
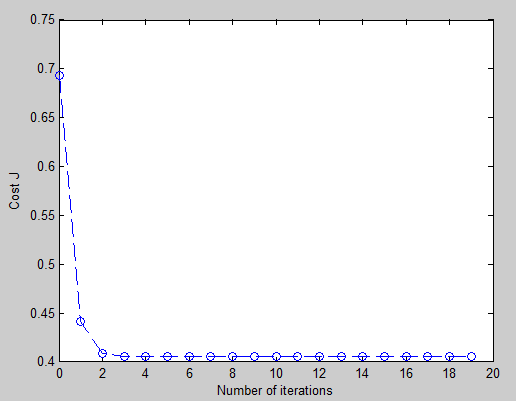
可以看出递归将近6次后就获取最小值;
决策边界:
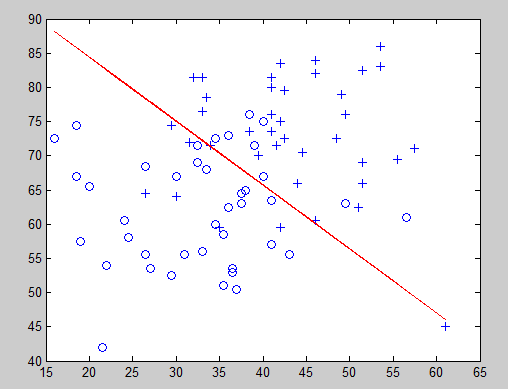
theta:
-16.3787
0.1483
0.1589
这样看起来要准确许多,接下来我们来预测一下,假如一个同学科目1为20 分,科目2为80分
那么被录取的可能性为33.17%
logistics回归简单应用——梯度下降,梯度上升,牛顿算法(一)的更多相关文章
- logistics回归简单应用(二)
警告:本文为小白入门学习笔记 网上下载的数据集链接:https://pan.baidu.com/s/1NwSXJOCzgihPFZfw3NfnfA 密码: jmwz 不知道这个数据集干什么用的,根据直 ...
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 线性回归和梯度下降代码demo
程序所用文件:https://files.cnblogs.com/files/henuliulei/%E5%9B%9E%E5%BD%92%E5%88%86%E7%B1%BB%E6%95%B0%E6%8 ...
- 机器学习(ML)十五之梯度下降和随机梯度下降
梯度下降和随机梯度下降 梯度下降在深度学习中很少被直接使用,但理解梯度的意义以及沿着梯度反方向更新自变量可能降低目标函数值的原因是学习后续优化算法的基础.随后,将引出随机梯度下降(stochastic ...
- Batch梯度下降
1.之前讲到随机梯度下降法(SGD),如果每次将batch个样本输入给模型,并更新一次,那么就成了batch梯度下降了. 2.batch梯度下降显然能够提高算法效率,同时相对于一个样本,batch个样 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 【IUML】回归和梯度下降
回归(Regression) 在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如local ...
- 逻辑回归(logic regression)的分类梯度下降
首先明白一个概念,什么是逻辑回归:所谓回归就是拟合,说明x是连续的:逻辑呢?就是True和False,也就是二分类:逻辑回归即使就是指对于二分类数据的拟合(划分). 那么什么是模型呢?模型其实就是函数 ...
随机推荐
- Lodop纯文本英文-等符号自动换行问题
ADD_PRINT_TEXT纯文本,宽度不够,高度足够,超宽会自动换行,高度不够会隐藏后面的内容.在超宽自动换行的时候,如果有-或()之类的,英文单词不拆分,或其他一些认为是不拆分的情况,会造成还没有 ...
- How to remove ROM in MAME
/usr/share/games/mame/roms/ /usr/local/share/games/mame/roms/ sudo rm /usr/local/share/games/mame/ro ...
- 学习 Spring (十四) Introduction
Spring入门篇 学习笔记 Introduction 允许一个切面声明一个实现指定接口的通知对象,并且提供了一个接口实现类来代表这些对象 由 中的 元素声明该元素用于声明所匹配的类型拥有一个新的 p ...
- MySQL数据库安装配置
1,下载MySQL 打开MySQL的官网www.mysql.com,发现有一个DOWNLOADS 点击它,进入到MySQL的下载页面,在页面的底部有一个MySQL Community Edition, ...
- Nginx 决策浏览器缓存是否有效
expires指令是告诉浏览器过期时间 syntax:expires [modified] time; eopch | max | off; default : off context :http,s ...
- Centos安装python3
安装环境 系统:阿里云服务器centos7.5系统 看见好多博客对centos安装python3的方式各不相同且都不完整,今天我来完整的演示安装python3 1.下载python3源码包 命令 wg ...
- mysql语句-DDL语句
SQL分类 1.DDL语句:数据定义语句,用来定义不同的数据段.数据库,表,列,索引等数据表对象,常用语句:create.drop.alter等. 2.DML语句:数据操作语句,用于添加.删除.更新和 ...
- jsp页面中 <%%> <%! %>, <%=%> <%-- --%>有什么区别
<%%> 可添加java代码片段 <%! %> 可添加java方法 <%=%> 变量或表达式值输出到页面 <%-- --%&g ...
- Luogu4389 付公主的背包(生成函数+多项式exp)
显然构造出生成函数,对体积v的物品,生成函数为1+xv+x2v+……=1/(1-xv).将所有生成函数乘起来得到的多项式即为答案,设为F(x),即F(x)=1/∏(1-xvi).但这个多项式的项数是Σ ...
- HDU 4344-Mark the Rope-大数素因子分解
注意只有一个素因子的情况. #include <cstdio> #include <algorithm> #include <cstring> using name ...