T-SQL基础(六)之可编程对象
变量
-- 声明变量
DECLARE @variable_name [AS] variable_type;
-- 变量赋值
SET @variable_name = variable_value;
示例如下:
DECLARE @age INT;
-- SET一次只能操作一个变量
SET @age = 26;
T-SQL提供了使用SELECT语句来给变量赋值的扩展功能:
SELECT @age = 30;
也可以使用子查询来给变量赋值:
USE WJChi;
SET @age =
(
SELECT Age FROM dbo.UserInfo WHERE Name = '雪飞鸿'
);
注意,上述SET语句中的子查询必须只能返回标量,否则会报错,示例如下:
USE WJChi;
SET @age =
(
SELECT Age FROM dbo.UserInfo
);
执行报错:
子查询返回的值不止一个。当子查询跟随在 =、!=、<、<=、>、>= 之后,或子查询用作表达式时,这种情况是不允许的。
批
批是一条或多条被客户端作为整体发送给SQL Server进行执行的T-SQL语句,SQL Server以GO命令来标识一个批的结束,注意,GO语句不能使用分号结尾。SQL Server以批为单位进行词法、语法分析及语句执行等工作。一个批中的错误不会影响另一个批中语句的执行,因为不同的批在逻辑上彼此独立,不同批中包含的语句互相独立,彼此互不影响。
批是一个解析单元,因此,即便在同一个批中修改了表结构,然后执行增删改查操作会引发解析错误,因为在同一批中的增删改查语句并不知道表结构已发生了变化。
GO n:表示执行n次批中的语句,如:
USE WJChi;
SELECT * FROM dbo.UserInfo;
GO 5
流程控制
IF...ELSE...
句式结构如下:
IF condition
BEGIN
-- do something
END
ELSE IF condition
BEGIN
-- do something
END
ELSE
BEGIN
-- do something
END;
IF...ELSE...支持嵌套
WHILE
句式结构如下:
WHILE condition
BEGIN
-- do something
END;
TRY...CATCH... & 错误处理
句式结构如下:
BEGIN TRY
-- do something
END TRY
BEGIN CATCH
-- do something
END CATCH;
SQL Server提供了一组描述错误的函数:
| 函数 | 作用 |
|---|---|
| ERROR_NUMBER() | 获取错误编号 |
| ERROR_MESSAGE() | 获取错误的文本信息 |
| ERROR_SEVERITY() | 获取错误严重级别 |
| ERROR_STATE() | 获取错误状态 |
| ERROR_LINE() | 获取错误发生行号 |
| ERROR_PROCEDURE() | 获取错误发生的过程名 |
也可以通过语句:
SELECT * FROM sys.messages;
来获取错误相关信息。可以使用THROW语句来抛出错误。
其它
RETURN、CONTINUE、BREAK、WAITFOR、GOTO
更多详细内容,参考微软官方文档:Control-of-Flow
临时表
SQL Server支持三种临时表:本地临时表、全局临时表和表变量。这三种临时表创建后都存储在tempdb数据库中。
本地临时表
创建本地临时表的方式与普通的数据表相同,但本地临时表仅在它被创建的会话中可见,会话结束后,临时表也会被销毁。
临时表以#开头,如:#UserInfo。临时表中的数据存储在磁盘中,可使用以下语句判断临时表是否存在:
IF OBJECT_ID('tempdb.dbo.#table_name') IS NOT NULL
全局临时表
与本地临时表最大的不同是:全局临时表对所有会话可见,当全局临时表不在被任何会话引用时,会被SQL Server销毁。
全局临时表以##开头,如:##UserInfo。
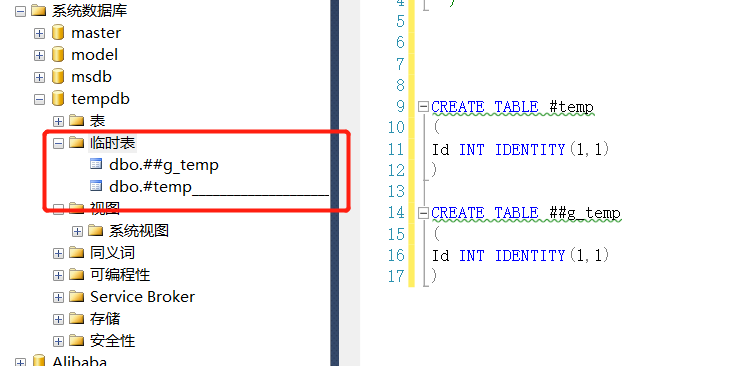

可通过语句:
SELECT * FROM tempdb..sysobjects WHERE name LIKE '%temp%'
来查看创建的临时表信息:


表变量
表变量的声明与普通变量一样,使用DECLARE语句,但相比于普通变量,表变量具有一些表的特征,如:可以执行INSERT、DELETE等操作。表变量只在创建它的会话中可见,且只对当前批可见。超出作用域或语句执行完毕,表变量便不可用。
一个显式事务回滚,事务中对临时表的修改也会回滚,但对已完成的表变量修改,则不会回滚。数据量较少时建议使用表变量,数据量较大时推荐使用临时表,微软文档中说大于100行就要考虑使用临时表了。
表变量 vs 临时表
表变量与临时表类似,但二者有所区别。临时表更多的强调它是数据表,表变量着重点则在于变量上。
关于表变量是在内存中存储数据,还是在硬盘上存储数据,可以参考stackoverflow上的讨论:
A table variable is not a memory-only structure. Because a table variable might hold more data than can fit in memory, it has to have a place on disk to store data. Table variables are created in the tempdb database similar to temporary tables. If memory is available, both table variables and temporary tables are created and processed while in memory (data cache).
个人理解:表变量和临时表对象的信息都存储在tempdb中,但临时表会将数据放到硬盘上,而表变量优先将数据放到内存中,必要时才会放到硬盘上,所以小数据量的话表变量更有性能优势。
SQL Server本身也在不断的进化,有关最新版本(这里是2019)中关于临时表和表变量的优化,可以参考:Faster temp table and table variable by using memory optimization
表类型
当创建了表类型,就会在数据库中保留表的定义,可以复用它创建表变量,也可作为存储过程和自定义函数的输入参数。
CREATE TYPE TableType AS TABLE
(
Id INT PRIMARY KEY
);
DECLARE @t TableType;

DROP TYPE TableType;
点击此处,查看有关类型的更多内容。
动态执行SQL
SQL Server中可以使用两种方式来执行动态SQL:EXEC命令与sql_executesql存储过程。
EXEC
EXEC是T-SQL提供的执行动态SQL的原始技术,接收一个字符串作为输入并执行字符串中的语句:
USE WJChi;
EXEC('SELECT * FROM dbo.UAddress');
EXEC支持正则与Unicode字符作为输入。
sql_executesql
sql_executesql存储过程在EXEC命令之后引入,与EXEC相比,sql_executesql更安全,更灵活,可以支持输入与输出参数。但,sql_executesql只支持Unicode字符作为输入。
ADO.NET发送到SQL Server的参数化查询语句就是使用sql_executesql来执行的,参数化查询可以有效避免SQL注入攻击。示例如下:
exec sp_executesql N'SELECT * FROM dbo.UAddress WHERE ShortAddress=@sd AND LongAddress=@ld',N'@sd nvarchar(4000),@ld nvarchar(4000)',@sd=N'河南省',@ld=N'河南省郑州市'
函数 & 存储过程 & 触发器
函数
使用函数的目的在于计算逻辑的封装及代码的复用。SQL Server中函数返回值分为:标量与表值两种。
创建函数的CREATE FUNCTION语句必须是当前批中的第一条语句,否则报错:'CREATE FUNCTION' 必须是查询批次中的第一个语句。
创建标量值函数:
CREATE FUNCTION dbo.GetSum
(
@left AS INT,
@right AS INT
)
RETURNS INT
AS
BEGIN
RETURN @left+@right;
END;


创建表值函数:
CREATE FUNCTION dbo.TableFunc
(
@name AS VARCHAR(8)
)
RETURNS TABLE
AS
RETURN
(
SELECT *
FROM dbo.UserInfo
WHERE Name = @name
);

修改函数定义,将创建函数语句中的CREATE换为ALTER即可。如下所示:
ALTER FUNCTION [dbo].[TableFunc]
(
@name AS VARCHAR(8)
)
RETURNS TABLE
AS
RETURN
(
SELECT * FROM dbo.UserInfo WHERE Name=@name
);
删除函数:
DROP FUNCTION function_name;
存储过程
存储过程与函数有相似之处,如都体现了封装的思想,但存储过程可以执行更为复杂的逻辑,可以有多个返回值。创建存储过程语句如下:
CREATE PROCEDURE HumanResources.uspGetEmployeesTest2
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
GO
更多详细内容,请参阅:存储过程(数据库引擎)
⚠️存储过程移植比较困难
触发器
触发器是特殊的存储过程,在满足条件时(事件被触发),会隐式执行,从这个角度讲,触发器会增加复杂性。
触发器个人接触和使用较少,这里不多介绍。详细内容可参考:CREATE TRIGGER (Transact-SQL)
小结
本章内容较为杂乱,但也都是平时编写T-SQL代码时较为常用的内容。
推荐阅读
T-SQL基础(六)之可编程对象的更多相关文章
- 《SQL Server 2012 T-SQL基础》读书笔记 - 10.可编程对象
Chapter 10 Programmable Objects 声明和赋值一个变量: DECLARE @i AS INT; SET @i = 10; 变量可以让你暂时存一个值进去,然后之后再用,作用域 ...
- [SQL] SQL 基础知识梳理(六)- 函数、谓词、CASE 表达式
SQL 基础知识梳理(六)- 函数.谓词.CASE 表达式 目录 函数 谓词 CASE 表达式 一.函数 1.函数:输入某一值得到相应输出结果的功能,输入值称为“参数”,输出值称为“返回值”. 2. ...
- sql server查询可编程对象定义的方式对比以及整合
本文目录列表: 1.sql server查看可编程对象定义的方式对比 2.整合实现所有可编程对象定义的查看功能的存储dbo.usp_helptext2 3.dbo.helptext2的选择性测试 4. ...
- JAVA基础知识之JDBC——编程步骤及执行SQL
JDBC编程步骤 下面以mysql数据库为例, 1.加载驱动 首先需要下载数据库的驱动jar文件,并且在eclipse包中加入到class path中去, 例如mysql的驱动文件 mysql-con ...
- SQL Server ->> Database Promgramming Object Security Control(数据库编程对象安全控制)
对于SQL Server内编程对象的安全控制是今天我在思考的问题.在MSDN上找到了几篇有用的文章. 首先微软推荐了三种做法: 1)第一种做法是在SQL Server中对一个应用程序对应创建应用程序角 ...
- SQL Server ->> 重新创建Assembly和自动重建相关的数据库编程对象(存储过程,函数和触发器)
在SQL Server中,一旦一个Assembly被其他的数据库编程对象(存储过程,函数和触发器)引用了,这个Assembly就不能被删除.但是问题是,在SQL Server要更新一个Assembly ...
- [SQL]SQL语言入门级教材_跟我学SQL(六)
跟我学SQL:(一)数据查询 且不说你是否正在从事编程方面的工作或者不打算学习SQL,可事实上几乎每一位开发者最终都会遭遇它.你多半还用不着负责创建和维持某个,但你怎么着也该知道以下的一些有关的SQL ...
- Java基础教程:JDBC编程
Java基础教程:JDBC编程 1.什么是JDBC JDBC 指 Java 数据库连接,是一种标准Java应用编程接口( JAVA API),用来连接 Java 编程语言和广泛的数据库. JDBC A ...
- 《SQL基础教程》+ 《SQL进阶教程》 学习笔记
写在前面:本文主要注重 SQL 的理论.主流覆盖的功能范围及其基本语法/用法.至于详细的 SQL 语法/用法,因为每家 DBMS 都有些许不同,我会在以后专门介绍某款DBMS(例如 PostgreSQ ...
- 常见SQL语句和SQL基础知识
引自:http://blog.csdn.net/u012467492/article/details/46790205 SQL语句考察(一) 1.查询出每门课都大于80 分的学生姓名 name k ...
随机推荐
- G++与C++的区别
C++是一门计算机编程语言,G++不是语言,是一款编译器中编译C++程序的命令而已. 不同的编译器,会对代码做出一些不同的优化 比如说: a++; 和 ++a; 如果从标准C的角度去理解.a++这个 ...
- jQuery-实现图片轮播
html部分: <!DOCTYPE html><html> <head> <meta charset="UTF-8"> <ti ...
- 一次 Java 内存泄漏的排查
由来 前些日子小组内安排值班,轮流看顾我们的服务,主要做一些报警邮件处理.Bug 排查.运营 issue 处理的事.工作日还好,无论干什么都要上班的,若是轮到周末,那这一天算是毁了. 不知道是公司网络 ...
- Android开发 - 掌握ConstraintLayout(八)障碍线(Barrier)
本文我们来介绍障碍线(Barrier)的使用,平常在开发中用的相对要少一些,但是在需要时会非常方便. 它的作用是将多个元素放到这个障碍线里面使时,其中的任何元素的大小或位置变化时都会使它的位置进行改变 ...
- BATJ等公司必问的8道Java经典面试题,你都会了吗?
1.谈谈你对 Java 平台的理解?“Java 是解释执行”,这句话正确吗? 考点分析: 对于这类笼统的问题,你需要尽量表现出自己的思维深入并系统化,Java 知识理解得也比较全面,一定要避免让面试官 ...
- 教你一招用 IDE 编程提升效率的骚操作!
阅读本文大概需要 3 分钟. IDEA 有个很牛逼的功能,那就是后缀补全(不是自动补全),很多人竟然不知道这个操作,还在手动敲代码. 这个功能可以使用代码补全来模板式地补全语句,如遍历循环语句(for ...
- JavaScript中的日期时间函数
1.Date对象具有多种构造函数,下面简单列举如下 new Date() new Date(milliseconds) new Date(datestring) new Date(year, mont ...
- 第61节:Java中的DOM和Javascript技术
Java中的DOM和Javascript技术 DOM是一门技术,是文档对象模型.所需的文档只有标记型文档,如我们所学的html文档(文档中的所有标签都封装成为对象了) DOM: 为Document O ...
- Maven相关命令
mvn comile 编译(main - >java) mvn test 测试 mvn package 打成 jar / war 包 mvn install 将模块放入本地仓库 mvn cl ...
- Jdk_API——1.8和Jdk_API1.6下载分享
1.JDK API 1.6 链接:https://pan.baidu.com/s/1bZKfldtqjCOsaYaT1Q9RcQ 提取码:t9ad 2.JDK API 1.8 链接:https ...