Hadoop学习笔记(五):java开发MapReduce
1. MapReduce的流程图(摘自马士兵老师视频),我们开发的就是其中的这两个(红框)过程。简述一下这个图,input就是我们需要处理的文件(datanode上文件的一个分块);Split就是将这个文件进行拆分,默认的就是按照行来拆分,拆分的结果是一个key-value对,key是这一行起始的位置,value就是这一行的内容;map是我们需要开发的内容,也就是对这一行数据的处理,产生的结果也是一个key-value对;shuffle是把上一步处理后的数据进行一个汇总,把同样的key合并到一起,把所有的value放到一个容器里;reduce缩减,就是将上一步容器里的值进行求和,也是一个key-value对;output就是输出。

2. 如果是在windows机器上进行开发,需要对环境进行一些配置:
a). 首先添加hadoop的环境变量HADOOP_HOME指向hadoop的安装目录:
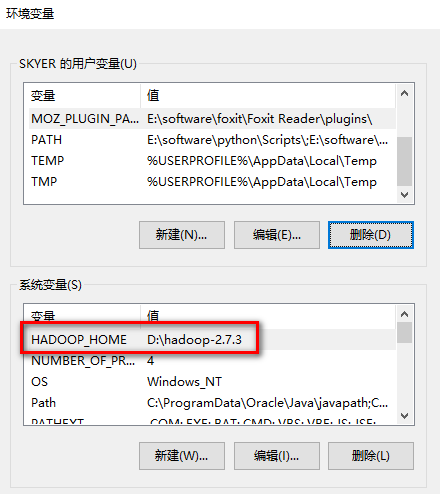
b). 把HADOOP_HOME/bin加到PATH环境变量(非必要)
c). 覆盖HADOOP_HOME/bin(到此处https://github.com/srccodes/hadoop-common-2.2.0-bin下载bin文件)
d). 将hadoop.dll复制到c:\windows\system32目录下(重启电脑)
3. 新建java项目,引入相应的jar包,jar包都位于HADOOP_HOME目录下的share/hadoop中,以下是jar清单:
a). common下hadoop-common-2.7.3.jar,已经common/lib下所有jar包。
b). hdfs下所有jar包,以及hdfs/lib下所有jar包。
c). mapreduce下所有jar包,以及mapreduce/lib下所有jar包。
d). yarn下所有jar包,以及yarn/lib下所有jar包。
4. 编写map层代码,新建WordMapper.java类:
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
final IntWritable ONE = new IntWritable(1);
String s = value.toString();
String[] words = s.split(" ");
for (String word : words) {
context.write(new Text(word), ONE);
}
}
}
5. 编写reduce层代码,新建WordReduce.java文件:
import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordReduce extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context content) throws IOException, InterruptedException {
long count = 0;
for (IntWritable v : values) {
count += v.get();
}
content.write(key, new LongWritable(count));
}
}
6. 编程测试层代码,新建Test.java(程序可以在windows独立运行,不用启动hadoop服务)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Test {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReduce.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, "E:/input.txt");
FileOutputFormat.setOutputPath(job, new Path("E:/out/")); job.waitForCompletion(true);
}
}
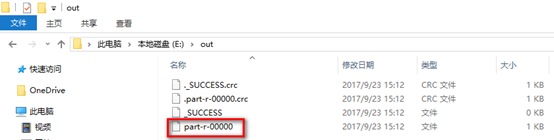
7. 运行测试代码,去到输出目录进行查看:
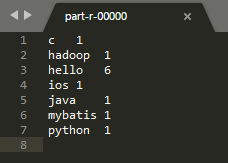
8. 打开该文件,查看运行结果:
9. 下面将这个程序扔到hadoop中运行。
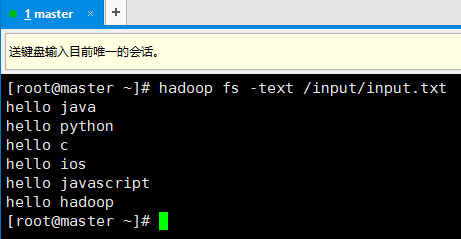
10. 首先在hadoop上准备一个需要处理文件
11. 修改测试代码,只要修改两行就好了,然后运行(记得启动hadoop和yarn):
FileInputFormat.setInputPaths(job, "hdfs://192.168.74.100:9000/input");
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.74.100:9000/output"));
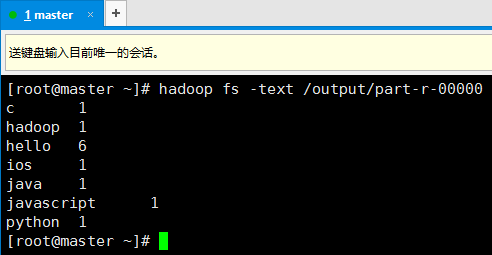
12. 在hadoop中查看运行结果
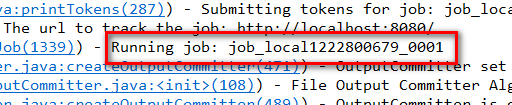
13. 需要注意的是(观看Eclipse的控制台),这个任务仍然是在本地执行的,也就是说,这个程序需要先将需要处理的文件下载的本地,然后再进行处理,显而易见,如果文件很大,这是很不合适的。
14. 我们要做的是将程序给hadoop执行,而不是将datanode的文件下载到本地,然后用本地的程序执行。修改后测试代码如下,注意,这里需要进行两个配置,在windows的host文件中添加master的ip:

然后,将项目打成jar包放到项目根目录下:
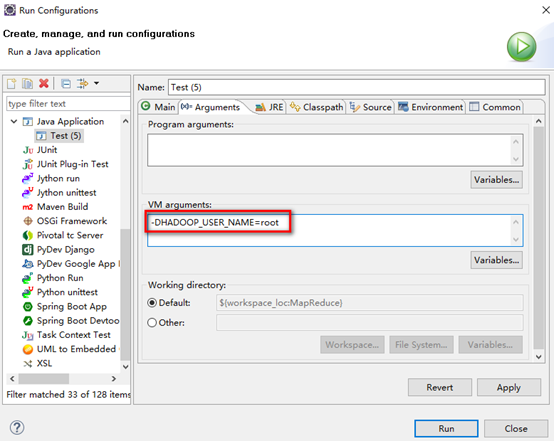
运行的时候,右击测试文件,选择Run Configurations,在Arguments的VM arguments中输入-DHADOOP_USER_NAME=root,然后点击Run
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Test {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.74.100:9000/");
conf.set("mapreduce.job.jar", "mr.jar");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "master");
conf.set("mapreduce.app-submission.cross-platform", "true"); Job job = Job.getInstance(conf); job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReduce.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, "/input/");
FileOutputFormat.setOutputPath(job, new Path("/output2/")); job.waitForCompletion(true);
}
}
15. 查看该任务ID

16. 运行完上述代码,查看测试结果(自行查看),宿主机浏览器查看刚才的任务,发现刚才的任务是在slave3上执行的。
Hadoop学习笔记(五):java开发MapReduce的更多相关文章
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- Java学习笔记二:Java开发工具Eclipse的安装与使用
Java开发工具Eclipse的安装与使用 正如office一样我们在开发java语言过程中同样需要依款不错的开发工具,目前市场上的IDE很多,这里只演示Eclipse的安装: 一:下载软件: 1.下 ...
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- Hadoop学习笔记五
一.uber(u:ber)模式 MapReduce以Uber模式运行时,所有的map,reduce任务都在一个jvm中运行,对于小的mapreduce任务,uber模式的运行将更为高效. uber模式 ...
- Java学习笔记五:Java中常用的运算符
Java中常用的运算符 运算符是一种“功能”符号,用以通知 Java 进行相关的运算.譬如,我们需要将变量 score 的值设置为 20 ,这时候就需要一个“=”,告诉程序需要进行赋值操作. Java ...
- Java基础学习笔记五 Java基础语法之面向对象
面向对象 理解什么是面向过程.面向对象 面向过程与面向对象都是我们编程中,编写程序的一种思维方式.面向过程的程序设计方式,是遇到一件事时,思考“我该怎么做”,然后一步步实现的过程.例如:公司打扫卫生( ...
- Java 学习笔记 (五) Java Compile\Build\Make的区别
以下内容引自: http://blog.51cto.com/lavasoft/436216 Compile.Make和Build的区别 原创leizhimin2010-11-30 11:30:20评论 ...
- Vue学习笔记(五)——配置开发环境及初建项目
前言 在上一篇中,我们通过初步的认识,简单了解 Vue 生命周期的八个阶段,以及可以应用在之后的开发中,针对不同的阶段的钩子采取不同的操作,更好的实现我们的业务代码,处理更加复杂的业务逻辑. 而在这一 ...
- 【原】Java学习笔记001 - JAVA开发环境搭建
1.JDK下载并安装,以jdk-7u45-windows-i586.exe为例(注意JDK的安装和JRE的安装是分开的) 2.“我的电脑”右键属性,找到“高级系统设置”,找到“高级”tab下的“环境变 ...
随机推荐
- 论Activity的转换
论Activity的互相转换 这次任务是实现 1.在主屏幕输入自己的姓名,单击评估按钮 2.进入第二个界面,并将主屏幕输入的姓名传递给第二个界面 3.在第二个界面进行问题回答: 4.第二个界面的回答结 ...
- C#中get和set属性的作用
c#在定义类时,通常要把类中声明的对象封装起来,使得外界不能访问这个属性.上述代码中如果去掉set部分,则外界只能读取name的值,如果去掉get部分,则只能给name赋值.这样就可以控制外界对私有属 ...
- django中使用memcache的一些注意事项
最近写django项目时在保存验证码方面要用到memcached,于是便查看了一些教程进行操作,结果确遇到了一系列问题,以下是一些容易遇到的雷区: 1.windows下memcached安装: -wi ...
- [小结] 中山纪念中学2018暑期训练小结(划掉)(颓废记)-Day10
[小结] 中山纪念中学2018暑期训练小结(划掉)(颓废记)-Day10 各位看众朋友们,你们好,今天是2018年08月14日,星期二,农历七月初四,欢迎阅看今天的颓废联编节目 最近发生的灵异事件有 ...
- eslint 的 env 配置是干嘛使的?
这笔修改体现了 env 和 global 的关系: https://github.com/g8up/youDaoDict/commit/8b05616f 官方文档表述: https://eslint. ...
- C++ Error C2664:无法将参数 1 从“const char [9]”转换为“LPCWSTR”解决方案
问题出现 编译平台:VS2013 Windows 出现地方:在使用LoadLibrary( )函数动态链接DLL文件时出现的一个问题 Eg. 在使用 UNICODE字符的工程中, HIN ...
- Jmeter学习过程中遇到的那些坑
开个新帖,持续记录学习jmeter过程中遇到的坑... (1)出师不利 由于公司的产品都是客户端模式,所以所有的接口测试都从获取access-token开始.妹的...上来就是一个坑... 一开始的配 ...
- Docker构建JDK环境
创建目录mkdir oracle-jdk 构建文件touch Dockerfile # Docker for jdk-8u181 FROM centos:7 MAINTAINER ggza " ...
- Hadoop-2.0 目录简介
Hadoop-2.0 目录简介 一.目录结构 将下载的压缩包解压: 解压后文件夹如下: 二.各文件夹目录结构 1.bin:Hadoop2.0的最基本管理脚本和使用脚本所在目录.这些脚本是sbin目录下 ...
- JS中创建多个相同的变量出现的问题
在做轮播图的时候出现了一个问题:如果定义两个完全相同的变量会发生什么: 1.两个全局变量: var num = 10; var num =100; 这种情况下很明显输出num的话会是100,但是内存中 ...