innodb二阶段日志提交机制和组提交解析
前些天在查看关于innodb_flush_log_at_trx_commit的官网解释时产生了一些疑问,关于innodb_flush_log_at_trx_commit参数的详细解释参见官网:
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
InnoDB log buffer are written to the log file after each transaction commit and the log file is flushed to disk approximately once per second.
注意redo和undo是在事务执行过程中就即时生成的,且早于数据库真正被修改,这被称作write ahead logging(WAL),undo的disk文件位置默认在系统表空间中,5.6以后也可以指定独立的undo表空间。
- sync_binlog=0:表示fsync()的调用完全交给操作系统,即文件系统缓存中的binlog是否刷新到disk完全由操作系统控制。
- sync_binlog=1:表示在发出事务提交请求时,binlog一定会被固化到disk,write()跳过文件系统缓存直接写入disk。
- sync_binlog=N(N>1):数据库崩溃时,可能会丢失N-1个事务。
- 此值为0表示:redo log buffer的内容每秒会被写入文件系统缓存的redo log里,同时被flush(固化)到disk上的redo log file中。
- 此值为1表示:redo log buffer的内容会在事务commit时被写入文件系统缓存的redo log里,同时被flush(固化)到disk上的redo log file中。
- 此值为2表示:redo log buffer的内容会在事务commit时被写入文件系统缓存的redo log里,而文件系统缓存的redo log每秒一次被flush(固化)到disk上的redo log file中。
以上介绍的使用 prepare_commit_mutex 来保证事务提交的顺序,只有当上一个事务 commit 后释放锁,下个事务才可以进行 prepare 操作,这样并发事务之间的mutex争用可能比较高。
此外由于内存数据写入磁盘的开销很大,如果频繁 fsync() 把日志数据永久写入磁盘,数据库的性能将会急剧下降。高并发事务带来的频繁磁盘写会导致事务提交等待带来性能瓶颈,为此提供 sync_binlog 参数来设置多少个 binlog 日志产生的时候调用一次 fsync() 把二进制日志刷入磁盘来提高整体性能,但这可能导致主从不一致。
因此针对innodb事务出现了binlog的组提交方式,其大致原理就是将多个并发事务的binlog(3个以上)通过队列批次写入磁盘,从而减小磁盘写次数,也避免了prepare_commit_mutex 的争用。
改进方案:
Mysql5.6 引入了组提交,并将提交过程分成 Flush stage、Sync stage、Commit stage 三个阶段。其实简单的说就是加入队列机制使得binlog写入顺序与事务执行顺序一致,加入队列的最大好处就是可以不获取prepare_commit_mutex锁也能实现不降低性能的日志顺序写。
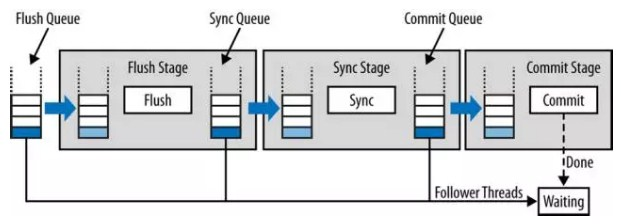
Binlog组提交的基本思想是,引入队列机制保证Innodb commit顺序与binlog落盘顺序一致,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目的。在MySQL数据库上层进行提交时首先按顺序将其放入一个队列中,队列中的第一个事务称为leader,其他事务称为follow,leader控制着follow的行为。
- Flush Stage
1) 持有Lock_log mutex [leader持有,follower等待]。
2) 获取队列中的一组binlog(队列中的所有事务)。
3) 将binlog buffer到I/O cache。
4) 通知dump线程dump binlog。
- Sync Stage
1) 释放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]。
2) 将一组binlog 落盘(sync动作,最耗时,假设sync_binlog为1)。
- Commit Stage
1) 释放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]。
2) 遍历队列中的事务,逐一进行innodb commit。
3) 释放Lock_commit mutex。
4) 唤醒队列中等待的线程。
说明:由于有多个队列,每个队列各自有mutex保护,队列之间是顺序的,约定进入队列的一个线程为leader,因此FLUSH阶段的leader可能是SYNC阶段的follower,但是follower永远是follower。当有一组事务在进行commit阶段时,其他新事物可以进行Flush阶段,从而使group commit不断生效。当然group commit的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果越明显,数据库性能的提升也就越大。
与 binlog 组提交相关的参数主要包括了如下两个:
- binlog_max_flush_queue_time
单位为微秒,用于从 flush 队列中取事务的超时时间,这主要是防止并发事务过高,导致某些事务的 RT 上升,详细内容可以查看函数MYSQL_BIN_LOG::process_flush_stage_queue() 。
注意:该参数在 5.7 之后已经取消了。
- binlog_order_commits
当设置为 0 时,事务可能以和 binlog 不同的顺序提交,其性能会有稍微提升,但并不是特别明显.
innodb二阶段日志提交机制和组提交解析的更多相关文章
- MySQL组提交(group commit)
MySQL组提交(group commit) 前提: 以下讨论的前提 是设置MySQL的crash safe相关参数为双1: sync_binlog=1 innodb_flush_log_at_trx ...
- mysql 5.6 binlog组提交
mysql 5.6 binlog组提交实现原理 http://blog.itpub.net/15480802/viewspace-1411356 Redo组提交 Redo提交流程大致如下 lock l ...
- mysql 5.6 binlog组提交实现原理(转载)
http://blog.itpub.net/15480802/viewspace-1411356/ Redo组提交 Redo提交流程大致如下 lock log->mutex write redo ...
- mysql复制那点事(2)-binlog组提交源码分析和实现
mysql复制那点事(2)-binlog组提交源码分析和实现 [TOC] 0. 参考文献 序号 文献 1 MySQL 5.7 MTS源码分析 2 MySQL 组提交 3 MySQL Redo/Binl ...
- InnoDB事务的二阶段提交
问题: 什么是二阶段提交 为什么需要二阶段提交 二阶段提交流程 什么是二阶段提交? ### 假设原来id 为10 的记录age 为5 begin; update student set age = 1 ...
- (转)MySQL 日志组提交
原文:https://jin-yang.github.io/post/mysql-group-commit.html 组提交 (group commit) 是为了优化写日志时的刷磁盘问题,从最初只支持 ...
- MYSQL学习笔记3--mysql 2PC二阶段协义 与 日志闪回
mysql两份日志: binlog :server innodb redo log:engine 两份日志顺序一致性:否则主备不一致 两份日志:原子性,同时都有,同时都无 2PC二阶段协义: 第一阶段 ...
- MySQL binlog 组提交与 XA(两阶段提交)
1. XA-2PC (two phase commit, 两阶段提交 ) XA是由X/Open组织提出的分布式事务的规范(X代表transaction; A代表accordant?).XA规范主要定义 ...
- MySQL binlog 组提交与 XA(分布式事务、两阶段提交)【转】
概念: XA(分布式事务)规范主要定义了(全局)事务管理器(TM: Transaction Manager)和(局部)资源管理器(RM: Resource Manager)之间的接口.XA为了实现分布 ...
随机推荐
- Go基础系列:struct的导出和暴露问题
struct的导出和暴露问题 关于struct的导出 struct的属性是否被导出,也遵循大小写的原则:首字母大写的被导出,首字母小写的不被导出. 所以: 如果struct名称首字母是小写的,这个st ...
- MONGODB(二)——索引操作
一.1.插入10w条数据> for(var i = 0;i<100000;i++){... var rand = parseInt(i*Math.random());... db.pers ...
- 了解golang的可变参数(... parameters),这一篇就够了
在实际开发中,总有一些函数的参数个数是在编码过程中无法确定的,比如我们最常用的fmt.Printf和fmt.Println: fmt.Printf("一共有%v行%v列\n", r ...
- C# 转换关键字 operator
operator 使用 operator 关键字重载内置运算符,或在类或结构声明中提供用户定义的转换. 假设场景,一个Student类,有语文和数学两科成绩,Chinese Math,加减两科成绩,不 ...
- 【转载】阿里云轻量应用型服务器和ECS服务器比较
在采购阿里云服务器的时候,我们会发现阿里云服务器分好多种,如GPU服务器.ECS服务器.轻量应用型服务器等.ECS服务器和轻量应用型服务器很多人无法搞明白其中的差别,个人的观点是轻量应用型服务器适合入 ...
- oracle表空间大小的限制和DB_BLOCK_SIZE的概念
之前接触的项目表空间最大也不超过10G,所以导入数据库时一直使用导入本地的oracle数据库文件的方法,即根据dmp文件大小设置一个数据文件,设定表空间最大值. --创建表空间,数据文件为'F:\ap ...
- T-SQL :编程理论 (一)
SQL代表结构化查询语言,是一种在关系数据库系统中查询和管理数据的标准语言.sql语句也有几个类别,包括定义语言(DDL),数据操作语言(DML),数据控制语言(DCL). DDL包括create,a ...
- php opcodes运行原理
谈下php的运行原理--Opcodes. 比如以下一段简单的代码: <?php echo '周伯通‘: ?> 执行这段代码会经过如下4个步骤(确切的来说,应该是PHP的语言引擎Zend) ...
- mybatis_05动态SQL_if和where
If标签:作为判断入参来使用的,如果符合条件,则把if标签体内的SQL拼接上. 注意:用if进行判断是否为空时,不仅要判断null,也要判断空字符串‘’: Where标签:会去掉条件中的第一个and符 ...
- Syncrhonized 和 Lock的区别和使用
相信很多小伙伴们初学多线程的时候会被这两个名词搞晕,所以这里专门介绍这两种实现多线程锁的方式的区别和使用场景 Synchronized 这个关键词大家肯定都不陌生,具体的用法就是使用在对象.类.方法上 ...