Python基础知识2-内置数据结构(上)
分类

数值型

用浮点型的时候注意别和"=="一起使用。
数字的处理函数

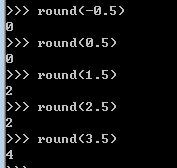
注意round()函数的特殊:四舍六入五取偶

类型判断


列表list

列表list定义 初始化

列表索引访问

列表查询

如何查帮助
列表元素修改、增加、插入、删除
注意:不能一边迭代该列表,一边删除或者增加该列表




列表其他操作

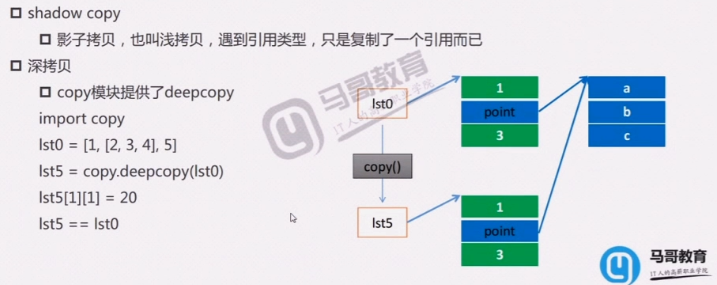
列表复制

"=="比较的是两个对象的"值"是否相等
"is"比较的是两个对象在内存中的地址是否相等
两者的区别可参考:https://www.cnblogs.com/CheeseZH/p/5260560.html
事实上Python 为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间。而Python 对小整数的定义是 [-5, 257),只有数字在-5到256之间它们的id才会相等,超过了这个范围就不行了,
同样的道理,字符串对象也有一个类似的缓冲池,超过区间范围内自然不会相等了。
总的来说,只有数值型和字符串型,并且在通用对象池中的情况下,a is b才为True,否则当a和b是int,str,tuple,list,dict或set型时,a is b均为False。

随机数

列表练习


合数:一个正整数,除了1和它本身以外,还能被其他正整数整除,这个数就叫做合数。如4、6、9、10等。
合数是除了1和其本身外具有其他正因数的正整数。依照定义,每一个大于1的整数若不是质数,就会是合数。而0与1则被认为不是质数,也不是合数。例如,整数14是一个合数,因为它可以被分解成2 × 7。
注意上述第二种方法中for循环和else的组合:
当i不属于primenumber列表中的元素时,则会执行else中的语句!
#杨辉三角
def fun():
L = [1]
while True:
for i in range(len(L)):
print(L[i],end=' ')
print()
yield L
L = [1] + [L[i] + L[i + 1] for i in range(len(L) - 1)] + [1]

#利用合数是几个质数的乘积(未优化,有大量多余计算)
s = []
start1=datetime.datetime.now()
for x in range(2,n):
for i in s:
if x%i == 0:
break
else:
s.append(x)
delta1=(datetime.datetime.now()-start1).total_seconds()
print(len(s))
print(delta1)
#计算结果:
9592
4.54826
#上述代码的优化
import datetime
import math
n=100000
pn=[]
flag=False
start=datetime.datetime.now()
for x in range(2,n):
for i in pn:
if x%i==0:
flag=True
break
if i>=math.ceil(x**0.5):
flag=False
break
if not flag:
pn.append(x)
delta=(datetime.datetime.now()-start).total_seconds()
print(len(pn))
print(delta)
#计算结果:
9592
0.377021
元组

元组的定义初始化

元组元素的访问

元组查询

元组其他操作

命名元祖nametuple

冒泡法

冒泡法代码实现(一)

注意冒泡排序在有序的时候效率最差!
因此在有序的时候交换次数为0,但是比较次数没变,因为我们可以考虑设置一个标记变量来判断序列是否已经有序从而提前结束循环,提高效率!
冒泡法代码实现(二)
#优化后的冒泡排序
lst = [1,2,3,4,5,6,7,8,9]
count=0#用于统计比较次数
count_swap=0#用于统计交换次数
length = len(lst) for i in range(length-1):
flag = False
for j in range(length-1-i):
count+=1
if lst[j+1]<lst[j]:#满足条件必定会交换
lst[j+1],lst[j]=lst[j],lst[j+1]
flag=True
count_swap += 1
if not flag:
break
冒泡法总结

字符串

字符串的定义初始化

字符串元素的访问---下标

字符串"+"连接

字符串"join"连接

注意:连接字符串的时候应优先使用join而不是+。
因为当用操作符+连接字符串的时候,由于字符串是不可变对象,其工作原理实际上是这样的:如果要连接如下字符串S1+S2+...+SN,执行一次+操作便会在内存中申请一块新的内存空间,
并将上一次操作的结果和本次操作的右操作数复制到新申请的内存空间,即当执行S1+S2的时候会申请一块内存,并将S1+S2复制到该内存中,以此类推,在N个字符串连接的过程中,会产
生N-1个中间结果,每产生一个中间结果都需要申请和复制一次内存,总共需要申请N-1次内存,从而严重影响执行效率。因此,整个字符串连接的过程相当于S1被复制N-1次,S2被复制
N-2次,...,SN复制一次,所以字符串的连接时间复杂度近似为O(n^2)。
而当用join()方法连接字符串的时候,会首先计算需要申请的总的内存空间,然后一次申请所需内存并将字符序列中的每一个元素复制到内存中去,所以join()操作的时间复杂度为O(n)。
字符串分割

s = 'aaa sss ddd'
print(s.split(' '))
print(s.partition(' '))
#输出如下:
['aaa', 'sss', 'ddd']
('aaa', ' ', 'sss ddd')
split分割



partition分割

字符串大小写

字符串排版

字符串修改


字符串查找*

注意find()方法的小坑,[start,end)是一个左开右闭的区间,且find和rfind分别是在其区间内从左至右和从右至左。



字符串判断*

字符串判断is系列

字符串格式化


字符串格式化最常用的还是format!



print("{:*^10}".format("center"))
#输出如下:
**center**
*octets中表示参数分解!
#题目输入一个字符串统计其中每个字符出现的次数:
num = ""
while True:
num = input("Please a integer :").strip()
if num.isdigit():
break
else:
print("Plesae input Again!")
#有需要优化的地方(可以使用字典提高效率)
count =[0]*10
for i in range(10):
count[i] = num.count(str(i)) for i in range(10):
if count[i]:
print(i,count[i])
Python基础知识2-内置数据结构(上)的更多相关文章
- Python的4个内置数据结构
Python提供了4个内置数据结构(内置指可以直接使用,无需先导入),可以保存任何对象集合,分别是列表.元组.字典和集合. 一.列表有序的可变对象集合. 1.列表的创建例子 list1 = []lis ...
- Python第五章-内置数据结构05-集合
Python内置数据结构 五.集合(set) python 还提供了另外一种数据类型:set. set用于包含一组无序的不重复对象.所以set中的元素有点像dict的key.这是set与 list的最 ...
- Python第五章-内置数据结构01-字符串
Python 内置的数据结构 到目前为止,我们如果想保存一些数据,只能通过变量.但是如果遇到较多的数据要保存,这个时候时候用变量就变的不太现实. 我们需要能够保存大量数据的类似变量的东东,这种 ...
- python的四种内置数据结构
对于每种编程语言一般都会规定一些容器来保存某些数据,就像java的集合和数组一样python也同样有这样的结构 而对于python他有四个这样的内置容器来存储数据,他们都是python语言的一部分可以 ...
- Python第五章-内置数据结构02-列表
Python 内置的数据结构 二.列表(list) 想一想: 前面学习的字符串可以用来存储一串信息,那么想一想,怎样存储咱们班所有同学的名字呢? 定义100个变量,每个变量存放一个学生的姓名可行吗?有 ...
- Python第五章-内置数据结构04-字典
Python 内置的数据结构 四.字典(dict) 字典也是 python 提供给我们的又一个非常重要且有用的数据结构. 字典在别的语言中有时叫关联数组.关联内存.Map等. 字典中存储的是一系列的k ...
- Python第五章-内置数据结构03-元组
Python 内置的数据结构 三.元组(tuple) python 作为一个发展中的语言,也提供了其他的一些数据类型. tuple也是 python 中一个标准的序列类型. 他的一些操作和str和li ...
- python 基础知识-day6(内置函数)
1.sorted():用于字典的排序 dict1={"name":"cch","age":"3","sex&q ...
- python面试总结4(算法与内置数据结构)
算法与内置数据结构 常用算法和数据结构 sorted dict/list/set/tuple 分析时间/空间复杂度 实现常见数据结构和算法 数据结构/算法 语言内置 内置库 线性结构 list(列表) ...
- Python的内置数据结构
Python内置数据结构一共有6类: 数字 字符串 列表 元组 字典 文件 一.数字 数字类型就没什么好说的了,大家自行理解 二.字符串 1.字符串的特性(重要): 序列化特性:字符串具有一个很重要的 ...
随机推荐
- 【转】java将excel文件转换成txt格式文件
在实际应用中,我们难免会遇到解析excel文件入库事情,有时候为了方便,需要将excel文件转成txt格式文件.下面代码里面提供对xls.xlsx两种格式的excel文件解析,并写入到一个新的txt文 ...
- 第11章 AOF持久化
AOF持久化在硬盘上保存的是对Redis进行的逻辑操作,类似InnoDB中的bin log.说白了就是你对一个Redis输入了哪些语句,AOF文件都会原封不动的保存起来,等到需要回复Redis的时候再 ...
- nginx+tomcat9+redisson+redis+jdk1.8简单实现session共享
一.环境安装 由于资源限制,在虚拟机中模拟测试,一台虚拟机,所有软件均安装到该虚拟机内 安装系统:CentOS Linux release 7.4.1708 (Core) CentOS安装选择版本:B ...
- Python实现分发数据块到多台服务器上
代码如下: # coding: utf-8 import paramiko import re import os from time import sleep # 定义一个类,表示一台远端linux ...
- CSS选择器之基本选择器总结
一.元素选择器(所有浏览器支持) 元素选择器(标签名选择器)其实就是文档的元素,如html,body,p,div等等, 下面例子中选择了span元素,并设置了字体颜色为红色. <body> ...
- 在开发框架中使用FTP辅助类上传或者下载文件,方便管理附件内容
在有些系统应用里面,我们需要对应用服务器.数据库服务器.文件服务器进行分开,文件路径等信息存储在数据库服务器里面,但文件内容则存储在文件服务器里面,通过使用FTP进行文件的上传下载,从而实现更加高效的 ...
- Grafana+Telegraf+Influxdb监控Tomcat集群方案
前言 前一段时间自家养的几只猫经常出问题,由于没有有效的监控预警手段,以至于问题出现或者许久一段时间才会被通知到.凌晨一点这个锅可谁都不想背,为此基于目前的情况搭建了以下这么一套监控预警系统. 相关软 ...
- 显式与隐式(ExplicitAndImplicit)
显式与隐式(Explicit And Implicit) 1.概念 1.1 显式 实现的单词Explicit意思是清楚的.明确的.详述的.所以,显式的“显”是指明显且清楚的实现,相对于接口来说,就是明 ...
- RabbitMQ 发布订阅
互联网公司对消息队列是深度使用者,因此需要我们了解消息队列的方方面面,良好的设计及深入的理解,更有利于我们对消息队列的规划. 当前我们使用消息队列中发现一些问题: 1.实际上是异步无返回远程调用,由发 ...
- portscaner 多线程、多协程并发端口扫描
import socket,time,re,sys,os,threading import gevent from gevent import monkey monkey.patch_all() so ...