065 updateStateByKey的函数API
一:使用场景
1.应用场景
数据的累加
一段时间内的数据的累加
2.说明
每个批次都输出自己批次的数据,
这个时候,可以使用这个API,使得他们之间产生联系。
3.说明2
在累加器的时候,起到的效果和这里的说明想法有些相同,都可以输出上一个批次的信息
二:程序
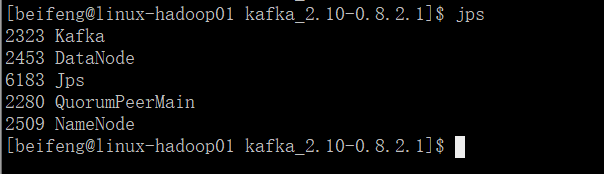
1.需要启动一些服务
需要使用hadoop
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"smallest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
}
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
三:updateStateByKey的优化
1.说明
主要的情况是,程序停止,刚刚累加的数据不再存在。
重启后效果如下:
只剩下,已经被checkPoint的数据,后面的数据不再存在。
2.优化的程序
多加两个参数。
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"largest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") // 初始化updateStateByKey用到的状态值
// 从保存状态值的地方(HBase)读取状态值, 这里采用模拟的方式
val initialRDD: RDD[(String, Long)] = sc.parallelize(
Array(
("hadoop", 100L),
("spark", 25L)
)
) /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
},
new HashPartitioner(ssc.sparkContext.defaultParallelism), // 分区器
initialRDD // 初始化状态值
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
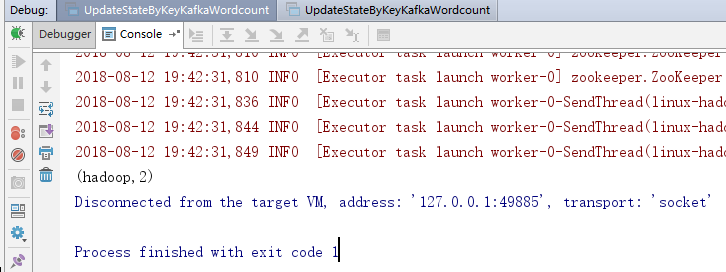
3.运行效果

4.注意点
需要有checkPoint的路径。
累加值存在硬盘中,长时间不访问会被删除。
065 updateStateByKey的函数API的更多相关文章
- HTML5 Audio标签方法和函数API介绍
问说网 > 文章教程 > 网页制作 > HTML5 Audio标签方法和函数API介绍 Audio APIHTML5HTML5 Audio预加载 HTML5 Audio标签方法和函数 ...
- MySQL Crash Course #05# Chapter 9. 10. 11. 12 正则.函数. API
索引 正则表达式:MySQL only supports a small subset of what is supported in most regular expression implemen ...
- Unix/Linux系统时间函数API
首先说明关于几个时间的概念: 世界时:起初,国际上的标准时间是格林尼治标准时间,以太阳横穿本初子午线的时刻为标准时间正午12点.它根据天文环境来定义,就像古代人们根据日晷来计时一样,如下图: 原子时: ...
- Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx
Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx 1.1. 预定义函数 魔术方法 魔术函数是什么1 1.2. & ...
- kotlin函数api
原 Kotlin学习(4)Lambda 2017年09月26日 21:00:03 gwt0425 阅读数:551 记住Lambda的本质,还是一个对象.和JS,Python等不同的是,Kotlin ...
- jQuery函数API,各版本新特性汇总
jQuery API 速查表 选择器 基本 #id element .class * selector1,selector2,selectorN 层级 ancestor descendant pare ...
- Azure 静态 web 应用集成 Azure 函数 API
前几次我们演示了如果通过Azure静态web应用功能发布vue跟blazor的项目.但是一个真正的web应用,总是免不了需要后台api服务为前端提供数据或者处理数据的能力.同样前面我们也介绍了Azur ...
- cocosCreator 新版本的动作函数API的应用
利用触摸位置判断,点击的是屏幕的左侧还是右侧,控制主角左右移动: 见代码: InputControl:function () { var self=this; //cc.systemEvent sel ...
- 【原创】自己动手写的一个查看函数API地址的小工具
C开源代码如下: #include <stdio.h> #include <windows.h> #include <winbase.h> typedef void ...
随机推荐
- iOS 横屏模态进入下一级界面, 竖屏退出
首先 Deployment Info 设置 除了 Upside Down 都勾选 然后,在AppDelegate.h 文件中 添加属性 @property(nonatomic,assign)NSI ...
- Confluence 6 使用 JConsole 监控远程 Confluence
针对生产系统中,我们推荐你使用远程监控,这个将不会消耗你远程 Confluence 服务器的资源. 启动远程监控: 添加下面的属性到 setenv.sh / setenv.bat 文件中,端口你可以定 ...
- Confluence 6 附件存储选项
在早期的 Confluence 版本中,我们允许存储附件到 WebDav 或者 Confluence 数据库中.针对新的 Confluence 安装,我们不再支持这 2 种存储了. 本地文件系统 在默 ...
- Confluence 6 安装 Oracle
如果你还没有在安装可以连接的 Oracle 数据库,请先下载后进行安装.请参考 Oracle 文档 来获取有关安装的指南. 当你设置你的 Oracle 服务器的时候: 字符集 必须使用 AL32UTF ...
- 基于 Confluence 6 数据中心的 SAML 单点登录设置你的身份提供者
如果你希望 Confluence 提供 SSO,将需要将 Confluence 添加到你的 IdP 中.一些后续的步骤将会与你的 IdP 有关,但是你通常需要: 在你的 IdP 中定义一个 'appl ...
- 分布式通讯架构RPC简单实现
什么是RPC: RPC(Remote Procedure Call,远程过程调用),一般用来实现部署在不同机器上的系统之间的方法调用,使得程序能够像访问本地系统资源一样,通过网络传输去访问远端系统资源 ...
- LeetCode(95): 不同的二叉搜索树 II
Medium! 题目描述: 给定一个整数 n,生成所有由 1 ... n 为节点所组成的二叉搜索树. 示例: 输入: 3 输出: [ [1,null,3,2], [3,2,null,1], ...
- log4j2的配置文件log4j2.xml笔记
一.背景 最近由于项目的需要,我们把log4j 1.x的版本全部迁移成log4j 2.x 的版本,那随之而来的slf4j整合log4j的配置(使用Slf4j集成Log4j2构建项目日志系统的完美解决方 ...
- yslow V2 准则详细讲解
主要有12条: 1. Make fewer HTTP requests 尽可能少的http请求..我们有141个请求(其中15个JS请求,3个CSS请求,47个CSS background ima ...
- javascript 自动填充功能
javascript 自动填充功能 javascript: (function(){ $("#zipcode").val("zip");$("#pho ...