065 updateStateByKey的函数API
一:使用场景
1.应用场景
数据的累加
一段时间内的数据的累加
2.说明
每个批次都输出自己批次的数据,
这个时候,可以使用这个API,使得他们之间产生联系。
3.说明2
在累加器的时候,起到的效果和这里的说明想法有些相同,都可以输出上一个批次的信息
二:程序
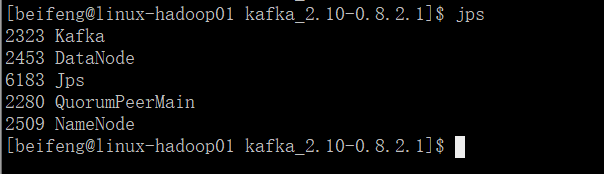
1.需要启动一些服务
需要使用hadoop
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"smallest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
}
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
三:updateStateByKey的优化
1.说明
主要的情况是,程序停止,刚刚累加的数据不再存在。
重启后效果如下:
只剩下,已经被checkPoint的数据,后面的数据不再存在。
2.优化的程序
多加两个参数。
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object UpdateStateByKeyKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"largest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") // 初始化updateStateByKey用到的状态值
// 从保存状态值的地方(HBase)读取状态值, 这里采用模拟的方式
val initialRDD: RDD[(String, Long)] = sc.parallelize(
Array(
("hadoop", 100L),
("spark", 25L)
)
) /**
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)]
*/ val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
.updateStateByKey(
(values: Seq[Int], state: Option[Long]) => {
// 从value中获取累加值
val sum = values.sum // 获取以前的累加值
val oldStateSum = state.getOrElse(0L) // 更新状态值并返回
Some(oldStateSum + sum)
},
new HashPartitioner(ssc.sparkContext.defaultParallelism), // 分区器
initialRDD // 初始化状态值
) resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
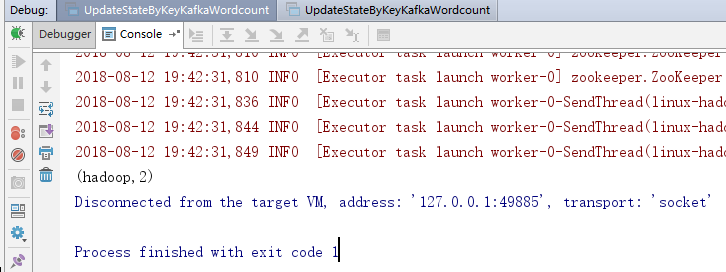
3.运行效果

4.注意点
需要有checkPoint的路径。
累加值存在硬盘中,长时间不访问会被删除。
065 updateStateByKey的函数API的更多相关文章
- HTML5 Audio标签方法和函数API介绍
问说网 > 文章教程 > 网页制作 > HTML5 Audio标签方法和函数API介绍 Audio APIHTML5HTML5 Audio预加载 HTML5 Audio标签方法和函数 ...
- MySQL Crash Course #05# Chapter 9. 10. 11. 12 正则.函数. API
索引 正则表达式:MySQL only supports a small subset of what is supported in most regular expression implemen ...
- Unix/Linux系统时间函数API
首先说明关于几个时间的概念: 世界时:起初,国际上的标准时间是格林尼治标准时间,以太阳横穿本初子午线的时刻为标准时间正午12点.它根据天文环境来定义,就像古代人们根据日晷来计时一样,如下图: 原子时: ...
- Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx
Atitit.跨平台预定义函数 魔术方法 魔术函数 钩子函数 api兼容性草案 v2 q216 java c# php js.docx 1.1. 预定义函数 魔术方法 魔术函数是什么1 1.2. & ...
- kotlin函数api
原 Kotlin学习(4)Lambda 2017年09月26日 21:00:03 gwt0425 阅读数:551 记住Lambda的本质,还是一个对象.和JS,Python等不同的是,Kotlin ...
- jQuery函数API,各版本新特性汇总
jQuery API 速查表 选择器 基本 #id element .class * selector1,selector2,selectorN 层级 ancestor descendant pare ...
- Azure 静态 web 应用集成 Azure 函数 API
前几次我们演示了如果通过Azure静态web应用功能发布vue跟blazor的项目.但是一个真正的web应用,总是免不了需要后台api服务为前端提供数据或者处理数据的能力.同样前面我们也介绍了Azur ...
- cocosCreator 新版本的动作函数API的应用
利用触摸位置判断,点击的是屏幕的左侧还是右侧,控制主角左右移动: 见代码: InputControl:function () { var self=this; //cc.systemEvent sel ...
- 【原创】自己动手写的一个查看函数API地址的小工具
C开源代码如下: #include <stdio.h> #include <windows.h> #include <winbase.h> typedef void ...
随机推荐
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- STM32L476应用开发之三:串行通讯实验
在我们的项目需求中,有两个串口应用需求,一个是与炭氢传感器的通讯,另一个是与显示屏的通讯.鉴于此,我们需要实验串行通讯. 1.硬件设计 串行通讯一个采用RS232接口,另一个直接采用TTL方式.我们在 ...
- 机器学习之高斯混合模型及EM算法
第一部分: 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类 ...
- Confluence 6 属性的一个示例
下面是有关 Confluence 页面被调用的前几行的访问概述. [344ms] - /display/ds/Confluence+Overview [313ms] - SiteMesh: parse ...
- Confluence 6 SQL 异常的问题解决
如果你得到了与下面显示内容类似的信息话,那么你最好考虑修改 Confluence 的日志级别输出更多的信息.如果你考虑通过 Atlassian support 获得帮助,那么这些详细的错误信息能够更好 ...
- ionic3 出现莫名广告
应用上线出现 有莫名其妙的广告弹出. 1,DNS被劫持 2,第三方包带广告 3,Http被劫持 wifi和4G网都出现了广告,所以可以直接排除DNS被劫持的问题 广告页只会在H5的页面出现,所以基本可 ...
- 使用Spring配置数据源JdbcTemplate
c3p0作为演示 1.编写资源文件(db.properties) jdbc.user=root jdbc.password=root jdbc.jdbcUrl=jdbc:mysql://localho ...
- laravel 获取当前月,当前星期,当天起始时间方法
获取当前月起始时间: 1. $time=time(); $start=date('Y-m-01',$time);//获取指定月份的第一天 $end=date('Y-m-t',$time); //获取指 ...
- java常用的中间件
tomcatWeblogicJBOSSColdfusionWebsphereGlassFish 一般本地开发的话建议使用tomcat. linux系统建议使用jetty或apache hpptd 大型 ...
- ajax---获取XMLHttpReuquest 对象
ajax的异步和同步(Asynchronus Javascript and Xml) 同步:一个时间段只能干一件事:即按部就班,一件事一件事的做. 异步:相同的时间段做多件事,同时进行.依靠 XMLH ...