嘿!我用python帮我干这些事
python 无疑是当下火上天的语言,但是我们又不拿来工作,那么能拿来干啥呢?我是这么干的。
1. 平时工作开发用不上,就当个计算器吧!
python
# 加减乘除
>>> (3 + 2) - 5 * 1
5
# 位运算
>>> 3 << 2
12
# x ^ y 幂次方运算,不能开方运算
>>> 3 ** 2
9
# 用另一种计算幂次方的运算,可以开方运算
>>> pow(9, 0.5)
3.0
# 作进制转换,如二进制转换,十进制转n进制
>>> bin(2)
'0b10'
>>> hex(25)
'0x19'
>>> oct(10)
''
>>> int('e0', 16)
224
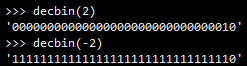
# 将十进制转换为二进制,以全0占位形式显示二进制,更方便查看,默认为32位,使用如下图所示
def decbin(i, bit=32):
return (bin(((1 << bit) - 1) & i)[2:]).zfill(bit)
2. 做简单爬虫
#!/usr/bin/python
# -*- coding: UTF-8 -*- import urllib,urllib2
import re
import os
import HTMLParser
dirbase = '/tmp'
urlbase = 'http://hg.openjdk.java.net'
url= urlbase + '/jdk8u/jdk8u/jdk/file/dddb1b026323/src' #/jdk,/hotspot
skip_to_p = ''
skip_find = False;
textmod ={'user':'admin','password':'admin'}
textmod = urllib.urlencode(textmod)
print(url)
req = urllib2.Request(url = '%s%s%s' % (url,'?',textmod))
res = urllib2.urlopen(req)
res = res.read()
alink = re.findall(r'<a',res)
allflist = [] table=re.findall(r'<tbody class="stripes2">(.+)<\/tbody>',res, re.S) harr = re.findall(r'href="(/jdk8u[\w\/\._]+)">(?!\[up\])', table[0]) def down_src_recursion(harr):
global allflist,skip_find;
if(not harr):
return False;
i=0; arrlen = len(harr)
lock_conflict_jump_max = 2; # 遇到文件锁时跳过n个文件,当前仍需跳过的文件数量
lock_conflict_jumping = 0;
print("in new dir cur...")
if(len(allflist) > 1500):
print('over 1500, cut to 50 exists...')
allflist = allflist[-800:]
for alink in harr:
i += 1;
alink = alink.rstrip('/')
if(skip_to_p and not skip_find):
if(alink != skip_to_p):
print('skip file, cause no find..., skip=%s,now=%s' % (skip_to_p, alink))
continue;
else:
skip_find = True;
if(alink in allflist):
print('目录已搜寻过:' + alink)
continue;
pa = dirbase + alink
if(os.path.isfile(pa)):
print('文件已存在,无需下载: ' + pa)
continue;
lockfile=pa+'.tmp'
if(os.path.isfile(lockfile)):
lock_conflict_jumping = lock_conflict_jump_max;
print('文件正在下载中,跳过+%s...: %s' % (lock_conflict_jumping, lockfile))continue;
else:
if(lock_conflict_jumping > 0):
lock_conflict_jumping -= 1;
print('文件正在下载中,跳过+%s...: %s' % (lock_conflict_jumping, lockfile))continue;
# 首先根据后缀把下载中的标识标记好,因为网络下载时间更慢,等下载好后再加标识其实已为时已晚
if(pa.endswith(('.gif','.jpg','.png', '.xml', '.cfg', '.properties', '.make', '.sh', '.bat', '.html', '.c','.cpp', '.h', '.hpp', '.java', '.1'))):
os.mknod(lockfile);
reqt = urllib2.Request(urlbase + alink)
rest = urllib2.urlopen(reqt)
rest = rest.read()
allflist.append(alink)
if(rest.find('class="sourcefirst"') > 0):
print('这是个资源文件:%s %d/%d' % (alink, i, arrlen))
if(not os.path.isfile(lockfile)):
os.mknod(lockfile);
filename = alink.split('/')[-1]
linearr = re.findall(r'<span id=".+">(.+)</span>', rest)
fileObject = open(dirbase + alink, 'w')
for line in linearr:
try:
line = HTMLParser.HTMLParser().unescape(line)
except UnicodeDecodeError as e:
print('oops, ascii convert error accour:', e)
fileObject.write(line + '\r\n')
fileObject.close()
os.remove(lockfile);
else:
print('这是目录:%s %d/%d' % (alink, i, arrlen))
if(not os.path.exists(pa)):
print('创建目录:%s' % alink)
os.makedirs('/tmp' + alink, mode=0777)
ta=re.findall(r'<tbody class="stripes2">(.+)<\/tbody>',rest, re.S)
ha = re.findall(r'href="(/jdk8u[\w\/\._]+)">(?!\[up\])', ta[0])
down_src_recursion(ha) # go...
down_src_recursion(harr);
以上python2 版本的爬虫,在python3中则要改编下呢!
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# for python3 import urllib.parse
import urllib.request
import re
import os
import html
dirbase = '/tmp'
urlbase = 'http://hg.openjdk.java.net'
url= urlbase + '/jdk8u/jdk8u/jdk/file/478a4add975b/src/share/classes/sun/misc'
#skip_to_p = '/jdk8u/jdk8u/jdk/file/478a4add975b/src/share/classes/sun/misc'
skip_to_p = ''
skip_find = False;
textmod ={'user':'admin','password':'admin'}
textmod = urllib.parse.urlencode(textmod)
print(url)
res = urllib.request.urlopen(url = '%s%s%s' % (url,'?',textmod))
res = res.read().decode('utf-8')
alink = re.findall(r'<a', res)
allflist = [] table=re.findall(r'<tbody class="stripes2">(.+)<\/tbody>',res, re.S) harr = re.findall(r'href="(/jdk8u[\w\/\._]+)">(?!\[up\])', table[0]) def down_src_cur(harr):
global allflist,skip_find;
if(not harr):
return False;
i=0;
arrlen = len(harr);
print("- In new dir cur...")
if(len(allflist) > 1500):
print('- Over 1500, cut to 50 exists...')
allflist = allflist[-800:]
for alink in harr:
i += 1;
alink = alink.rstrip('/')
if(skip_to_p and not skip_find):
if(alink != skip_to_p):
print('- Skip file, cause no find..., skip=%s,now=%s' % (skip_to_p, alink))
continue;
else:
skip_find = True;
if(alink in allflist):
print('- Searched before:' + alink)
continue;
rest='';
try:
res = urllib.request.urlopen(urlbase + alink)
rest = res.read().decode('utf-8')
except Exception as e:
print(e)
print(" ERROR accour, continue;")
continue;
allflist.append(alink)
if(rest.find('class="sourcefirst"') > 0):
print('- Code resourse:%s %d/%d' % (alink, i, arrlen))
filename = alink.split('/')[-1]
linearr = re.findall(r'<span id=".+">(.+)</span>', rest)
fileObject = open(dirbase + alink, 'w')
for line in linearr:
fileObject.write(html.unescape(line) + '\r\n')
fileObject.close()
else:
pa = dirbase + alink
print('- Directory:%s %d/%d' % (alink, i, arrlen))
if(not os.path.exists(pa)):
print('makedirs:%s' % alink);
os.makedirs('/tmp' + alink, mode=0o777 );
ta=re.findall(r'<tbody class="stripes2">(.+)<\/tbody>',rest, re.S)
ha = re.findall(r'href="(/jdk8u[\w\/\._]+)">(?!\[up\])', ta[0])
# 递归爬取解析
down_src_cur(ha) down_src_cur(harr);
做文件搜索,替换:
4. 做简单代码验证
# 做简单字符查找验证
>>> '234234fdgdfs'.find('f')
6
>>> '234234fdgdfs'.index('f')
6
>>> '234234fdgdfs'[2:5]
''
# 做正则匹配
>>> re.findall(r'[a-zA-Z0-9]*\.[a-zA-Z1-9]*[\.|com]*', 'www.baidu.com')
['www.baidu.com']
5. 写个运维脚本,监听本机8080端口的运行状态,如果发现挂了,就发送邮件通知主人,并重启服务器。
#!/usr/bin/env python
#!coding=utf-8
import os
import time
import sys
import smtplib
from email.mime.text import MIMEText def send_email (warning):
msg = MIMEText(warning)
msg['Subject'] = 'python send warning mail'
msg['From'] = '测试了<rootrr@163.com>'
try:
smtp = smtplib.SMTP()
to_mail = 'xx@163.com'
from_mail = 'xx@163.com'
smtp.connect(r'smtp.qiye.163.com')
smtp.login('xx@163.com', 'xxx123')
smtp.sendmail(from_mail, to_mail, msg.as_string())
smtp.close()
print('send mail to %s, content is: %s' % (to_mail, msg))
except Exception as e:
print("Send mail Error: %s" % e)
# 监听状态中。。。
while True:
http_status = os.popen('netstat -tulnp | grep ":8080"','r').readlines()
try:
if http_status == []:
os.system('service tomcat7 start')
time.sleep(3) # 等待启动
new_http_status = os.popen('netstat -tulnp | grep ":8080"','r').readlines()
str1 = ''.join(new_http_status)
is_port = -1;
send_email(warning = "8080 port shutdown, This is a warning!!!") # 发送通知
try:
is_port = str1.split()[3].split(':')[-1]
except IndexError, e:
print("out of range:", e)
if is_port != '':
print 'tomcat 启动失败'
else:
print 'tomcat 启动成功'
else:
print '8080端口正常'
time.sleep(5)
except KeyboardInterrupt:
sys.exit('out order\n')
6. 科学计算,大数据,图形识别。。。
看工作需要!
以下命令为反向kill某个端口的服务
# netstat -tunlp | grep ':8080' | awk '{split($7, arr, "/"); print(arr[1])}' | kill -9
嘿!我用python帮我干这些事的更多相关文章
- 让大蛇(Python)帮你找工作
前段时间用Python实现了一个网络爬虫(让大蛇(Python)帮你找工作),效率总体还可以,但是缺点就是每次都需要手动的去触发,于是打算对该爬虫加上Timer,经过网上一番搜索以及API的查询,发现 ...
- 用Python帮你实现IP子网计算
目录 0. 前言 1. ipaddress模块介绍 1.1 IP主机地址 1.2 定义网络 1.3 主机接口 1.4 检查address/network/interface对象 1.4.1 检查IP版 ...
- 用python帮朋友刷帖
0x0前言: 答应了一个朋友帮他刷贴,自己用python写了一个脚本刷. 虽然行为不好..但是缺钱用... 0x01准备: splinter模块: chrome浏览器驱动 0x02开始: 1.进入百度 ...
- 还在担心网聊相亲的小姐姐,美女变恐龙!Python帮你"潜伏"侦查
最近,小编的一个朋友很是苦恼,他在Python交流的群里,认识了一个妹子,看头像感觉挺不错的,大家都喜欢摄影,蛮谈得来的!但是想要约见面却不敢,因为他看过<头号玩家>,深知躲在电脑背后 ...
- Python 帮你玩微信跳一跳 GitHub Python脚本
前言想自己搞游戏小程序的 在github 有人已经利用 python程序, 通过adb 获取不同型号安卓手机的系统截图,然后通过计算小人与目标位置距离之后得到准确的触摸时间,再通过 开发者模式里的 a ...
- 我用Python帮朋友做了张猪肉数据分析图,结果。。。
却发现他是这么拿我当兄弟的 事情的经过是这样的: 我开开心心的去一家烧饼店吃饭 . 抬头一看,二师兄又涨价了 叹了口气,再这么下去真的要吃不起夹肉的烧饼了 点了两个烧饼一碗馄饨 快吃完的时候, ...
- 对比Node.js和Python 帮你确定理想编程解决方案!
世上没有最好的编程语言.有些编程语言比其他编程语言用于更具体的事情.比如,你可能需要移动应用程序,网络应用程序或更专业化的系统,则可能会有特定的语言.但是我们暂时假设你需要的是一个相对来说比较简单的网 ...
- 让大蛇(Python)帮你找工作 之增强版
前一段时间用Python写了个简单的网络爬虫,可以从某个求职网站上根据预先设置的条件一次性的爬取所有的职位信息,最近对该程序进行了一下完善,主要包括如下内容 (1)可以对爬取的结果再进行筛选 例如,你 ...
- 官方新出的 Kotlin 扩赞库 KTX,到底帮你干了什么?
Kotlin KTX 2月5号的时候,Google 发布了一款 Kotlin 的扩展库,叫 Android KTX,不过现在还处于预览版的状态.它能使 Android 上的 Kotlin 代码更简洁, ...
随机推荐
- c#跨线程访问的代码和窗体关闭退出死循环的代码
一:一段跨线程访问,给页面内的控件赋值的代码找了半天没找到,还得找了以前写的程序. 在这记下来吧 . 这是其他程序内可以跨线程访问的代码 . if (gridControl1.InvokeRequi ...
- ORA-15137: cluster in rolling patch
oracle 12.1.0.2,给diskgroup加盘的时候报错ORA-15137: cluster in rolling patch 确认两节点补丁相同 crsctl query crs soft ...
- java去除数组重复元素的方法
转载自:https://blog.csdn.net/Solar24/article/details/78672500 import java.util.ArrayList; import java.u ...
- Chapter_4_JAVA作业
一.类的封装,继承与多态 1.课前预习 1.1 举列现实生活中的封装,以及简述在程序中什么是属性的封装? 1.1.1 将东西捆绑在一起,如集成芯片:高压电线等等 1.1.2 封装就是将属性私有化,提供 ...
- Mad Libs游戏,华氏与摄氏转换
华氏温度 与 摄氏温度的相互转换 公式:摄氏 ℃=5/9(°F-32) 华氏°F= ℃×9/5+32 # -*- coding: UTF-8 -*- num=input('输入摄氏温度:') num ...
- 颜色16进制转为RGB格式
<script> 2 function getRGB(str){ var arr = str.split(""); var myred = arr[1]+arr[2]; ...
- Laravel 中使用 JWT 认证的 Restful API
Laravel 中使用 JWT 认证的 Restful API 5天前/ 678 / 3 / 更新于 3天前 在此文章中,我们将学习如何使用 JWT 身份验证在 Laravel 中构建 r ...
- HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别: 1xx:指示信息--表示请求已接收,继续处理 2xx:成功--表示请求已被成功接收.理解.接受 3xx:重定向--要完成请求必须进行 ...
- 数据库镜像转移Failover Partner
数据库主体镜像转换:任务 - 镜像 - 故障转移 sqlserver2008 数据库镜像服务配置完成后,大家会发现我们有了两个数据库服务,这两个服务可以实现自动故障转移,那么我们的程序如何实现自动连接 ...
- 初识STM32中的USMART组件
今天看了usmart那部分的模块,感觉使我们stm32的学习变更加方便,你可以通过串口查看和检验你所注册过的函数. USMART配步骤1.将USMART包添加到工程中,头文件要包括path2.添加所需 ...